shorts
(Untitled)
《俯瞰强化学习》这本书,为了说清楚,必须要有公式,在网站上显示这么多公式,的确是一个大考验,尤其是轻量化的网站,不能渲染太复杂的公式,搞了一天多才搞定。
shorts
《俯瞰强化学习》这本书,为了说清楚,必须要有公式,在网站上显示这么多公式,的确是一个大考验,尤其是轻量化的网站,不能渲染太复杂的公式,搞了一天多才搞定。
《俯瞰强化学习:目标、反馈循环与智能体的自我改进》 完整书稿 目录 * 序章:一个会改变世界的学习者 * 第一部分:我们究竟在优化什么 * 第 1 章:长期回报:为什么眼前的奖励不够 * 第 2 章:奖励不是目的:如何把意图翻译成数字 * 第二部分:未来如何返回现在 * 第 3 章:Bellman 方程:用未来重新定义现在 * 第 4 章:信用分配:谁应当为结局负责 * 第 5 章:自举:用尚未完成的预测更新预测 * 第三部分:长期目标如何变成一次更新 * 第 6 章:为什么强化学习的损失函数看起来不像损失函数 * 第四部分:每一种估计都有代价 * 第 7 章:偏差与方差:不存在免费的估计
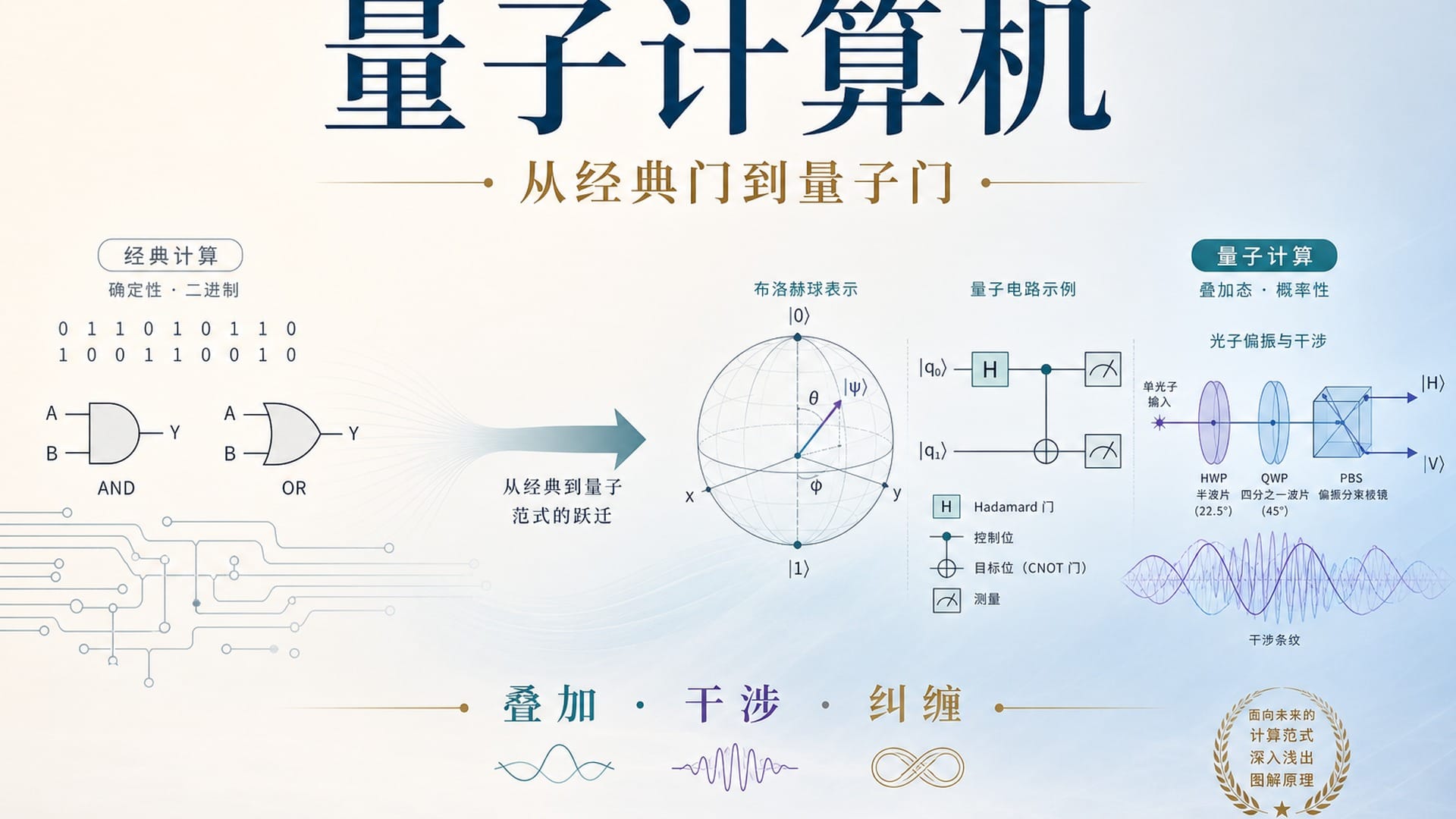
《量子计算机》全书 引言 我为什么要写这本书 我第一次认真听人讲量子计算,是在读博士的时候。 那时我在实验室里,常听师兄师姐提起一位老师:清华计算机系的应明生老师。 他的经历很特别,研究方向也很超前。 在很多人还只是把量子计算当成一个遥远名词的时候,他已经在这个方向上做了很深的工作。 我不是一开始就懂量子计算。 恰恰相反,刚接触它的时候,我和很多人一样,第一反应是: 这东西是不是太物理了? 是不是要先学一大堆薛定谔方程? 是不是没有量子力学背景就根本进不去? 后来,我经常参加系里的讲座。 其中有不少是应明生老师团队关于量子计算的报告。 那些讲座给我最大的感受是: 真正懂这个领域的人,反而不会一上来用复杂公式把你压住。 他们会先抓住最核心的规则。 只要规则讲清楚,量子计算就没有那么玄。 我印象很深的一次,是听到段润尧老师讲量子计算的入门思路。 他说,理解量子计算,可以先从量子力学的几条基本规则入手。 把这些规则和计算机专业熟悉的逻辑门对照起来,就能慢慢走到量子态、量子门和量子线路。 这句话对我很有启发。 因为它把量子计算
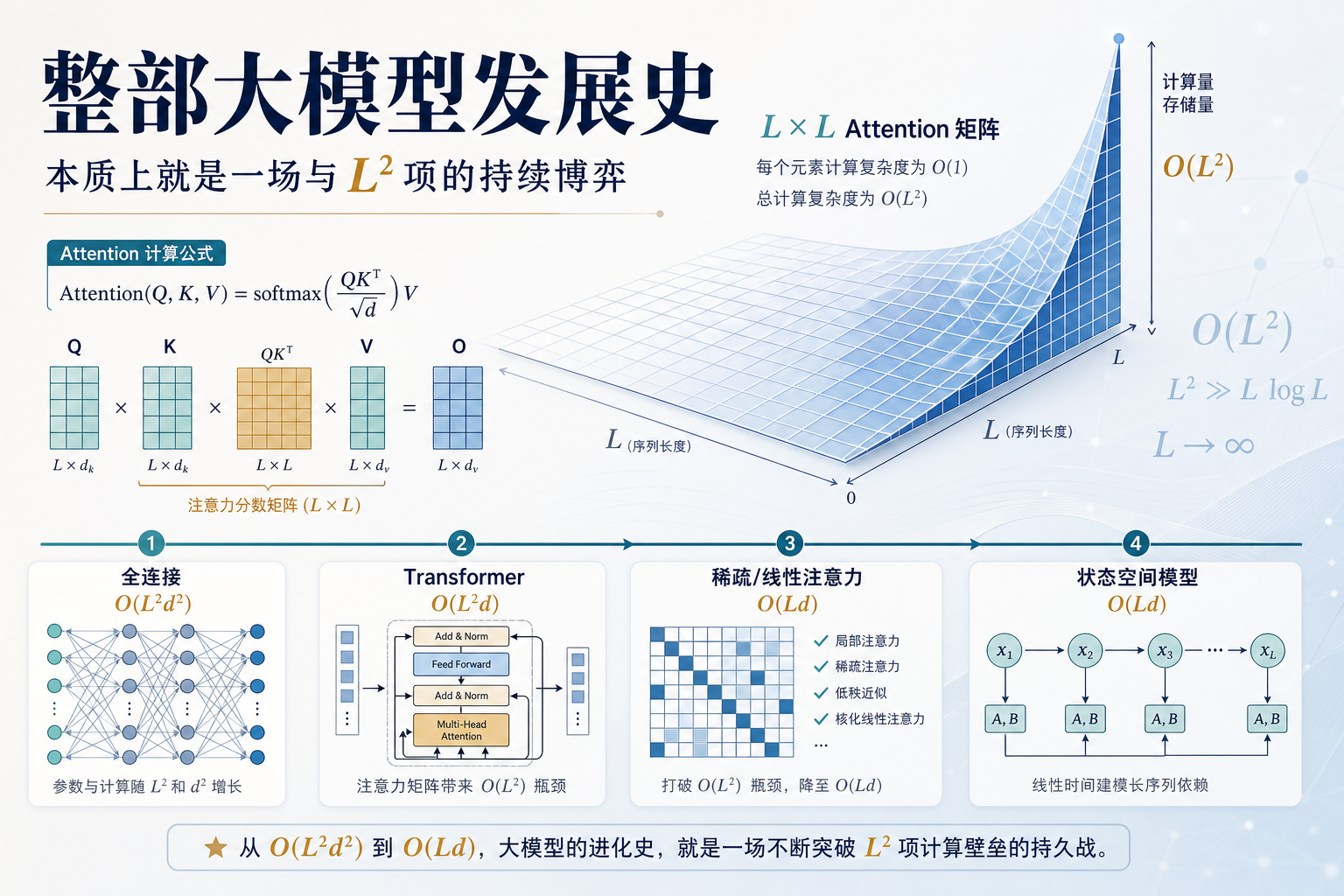
前言:一个平方项引发的革命 如果你对大语言模型稍有了解,你一定听过"注意力机制"这个词。2017年,Google的一篇论文《Attention Is All You Need》把它推上了舞台中央,此后几乎所有的大模型——GPT、BERT、LLaMA、Claude——都建立在它的基础之上。 但注意力机制并不是故事的起点,也不是终点。 故事的真正主角,是一个藏在公式深处的平方项——L²。 L是序列的长度,也就是模型一次能"看到"多少个token。L²意味着:当你想把序列长度翻倍,计算量不是翻倍,而是翻四倍。当你想把序列长度变成十倍,计算量变成一百倍。 这个平方项不是某个具体算法的缺陷。它是"让每个词看见所有词"这个需求本身要付出的代价。只要你想要全局信息交互,L²就会像幽灵一样出现——不管你用什么算法,
我开发了一个ai斗地主游戏,试试看。 ai斗地主
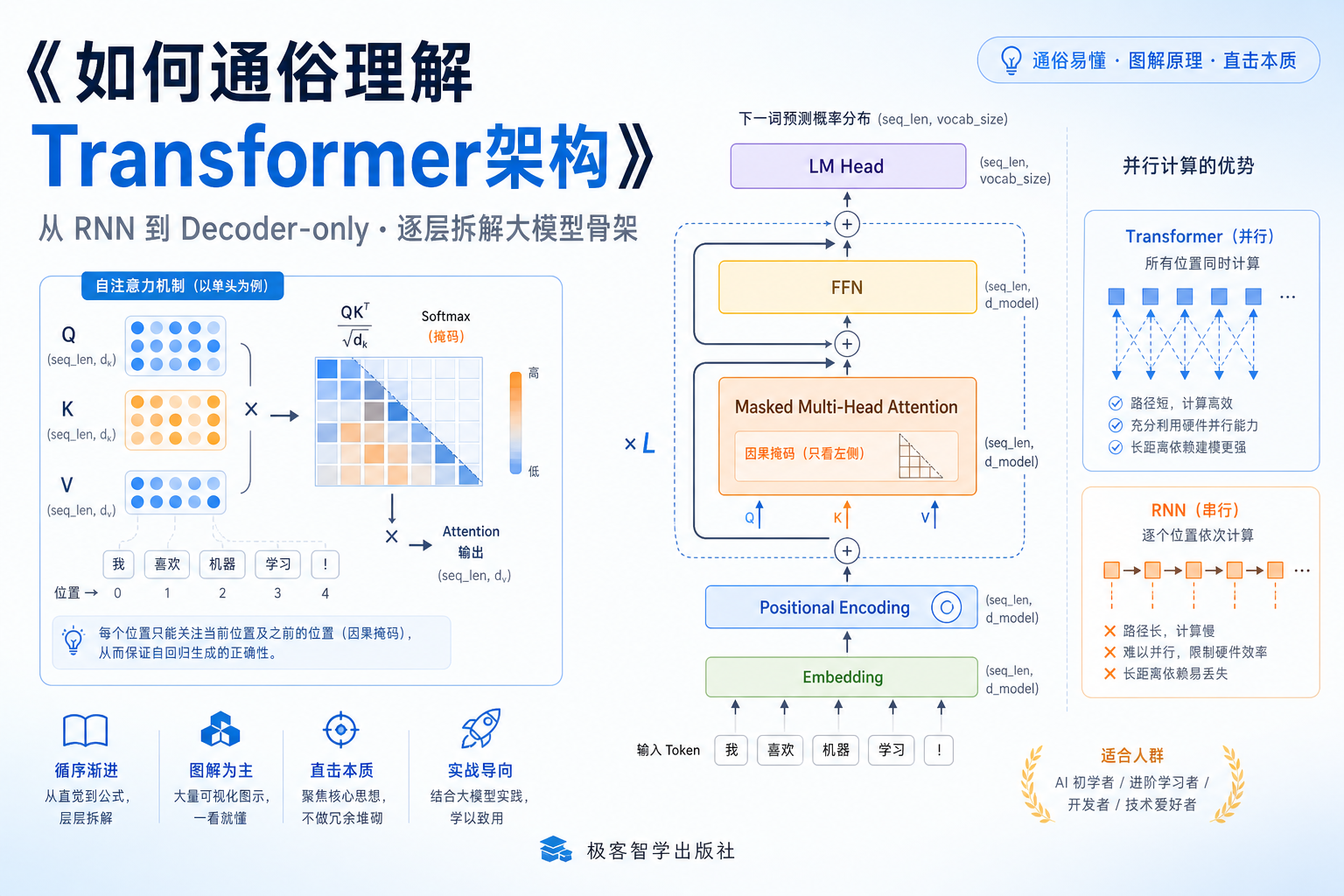
如何通俗理解 Transformer 架构 以 GPT-3 为量化基准,逐层拆解 Decoder-only 大语言模型 第1章 从序列模型到 Transformer 的演进 在深入 Transformer 的内部结构之前,有必要先回答一个问题:在这套架构出现之前,人们用什么方法来处理文本序列?又遇到了什么根本性的困难? 答案是 RNN,也就是循环神经网络,以及它的改进版本 LSTM 和 GRU。RNN 的设计思路看起来非常自然:它像人读书一样,从左到右逐字阅读,同时用一个隐藏状态来记住前面读过的内容。每读到一个新词,就把这个词的信息和之前的记忆合并,更新隐藏状态。这个设计在直觉上毫无问题,甚至可以说是对人类阅读过程的直接模拟。但恰恰是这种"像人一样顺序处理"的思路,埋下了两个致命的结构性缺陷。 1.1 缺陷一:长距离依赖失效 考虑下面这个句子: 小明告诉小李,他很开心。

《大模型训练之路》 目录 正文 1. 第 1 章:序章:大模型不是魔法,是训练目标的升级 2. 第 2 章:Token、参数与下一个词 3. 第 3 章:Transformer 够用版:模型如何读懂上下文 4. 第 4 章:预训练:互联网文本如何变成训练数据 5. 第 5 章:预训练公式:下一个 token 的概率 6. 第 6 章:SFT:把基础模型教成助手 7. 第 7 章:SFT 公式:为什么它仍然是模仿学习
shorts
给我的网站里,传了一个静态网页,试试看 每次弹跳一半 — 无穷次弹跳,有限时间
shorts
我的这个网站奔溃了多次,在AI的帮助下,终于解决了。 以下是AI的结果: 太棒了!大功告成! 看这份最新的日志,咱们已经打了一场绝对漂亮的翻身仗。网站不仅彻底恢复了健康,而且之前埋下的两个“大雷”已经被完美清除。 🎉 胜利成果核对 1. 生产模式成功强推 INFO Ghost is running in production... * 解读:这句话说明 Ghost 终于进入了高效的生产环境模式。Node.js 的内存开销会大幅度下降,自动开启了垃圾回收和性能优化。配合你之前开启的 Swap 虚拟内存,因内存溢出而导致网站挂掉的概率已经降到了接近于零。 2. 301 死循环彻底打破 "GET /" 200 1548ms "GET /wo-de-di-si-ben-shu... " 200 106ms * 解读:之前的状态全是 301

为什么要互换根:从韦达到五次方程无根式解(高中版) 副标题:从根的互换、韦达定理到伽罗瓦群的通俗讲解 写在前面 这不是一本大学抽象代数教材。它面向高中生和普通数学爱好者,默认你熟悉二次方程、韦达定理、一点排列组合和少量复数。我们不会一开场就抛出域扩张、正规子群、可解群这些词,而是从一个更朴素的问题出发:为什么要研究根的位置互换? 全书会反复使用一个克制的破案比喻:方程的系数像公开线索,根像身份还没确认的嫌疑人,根的位置互换像侦探做的测试,所有合法换位动作的名单后来叫伽罗瓦群,而开根号就是打破某一层不可区分性的工具。 每一章只解决一个核心问题。公式会出现,但不会密集堆砌;每个公式出现时,我们都会问它为什么出现,它解决了什么问题,它和根的互换有什么关系。 目录 * 序章 一个公式为什么会不存在 * 第一章 二次方程到底在做什么 * 第二章 韦达定理:系数看到的只是根的整体 * 第三章 根的位置为什么要互换 * 第四章 两个根的互换:最简单的群 * 第五章 三个根的互换:六个动作的世界 * 第六章 为什么要研究这些互换动作 * 第七章 三次方程的三个根为什么