《俯瞰强化学习:目标、反馈循环与智能体的自我改进》
完整书稿
目录
- 序章:一个会改变世界的学习者
- 第一部分:我们究竟在优化什么
- 第 1 章:长期回报:为什么眼前的奖励不够
- 第 2 章:奖励不是目的:如何把意图翻译成数字
- 第二部分:未来如何返回现在
- 第 3 章:Bellman 方程:用未来重新定义现在
- 第 4 章:信用分配:谁应当为结局负责
- 第 5 章:自举:用尚未完成的预测更新预测
- 第三部分:长期目标如何变成一次更新
- 第 6 章:为什么强化学习的损失函数看起来不像损失函数
- 第四部分:每一种估计都有代价
- 第 7 章:偏差与方差:不存在免费的估计
- 第 8 章:最大化偏差与价值幻觉
- 第 9 章:致命三角:为什么深度 RL 容易失控
- 第五部分:学习者改变了自己的数据
- 第 10 章:非平稳性:在移动的地面上学习
- 第 11 章:On-Policy 与 Off-Policy:旧经验还能用吗
- 第 12 章:经验回放、目标网络与更新约束:稳定化工具箱
- 第六部分:探索未知,也承担风险
- 第 13 章:探索与利用:为什么不能总选当前最优
- 第 14 章:深度探索:从随机试错到主动寻找信息
- 第 15 章:探索的边界:安全、成本与可控性
- 第七部分:把算法放回全景图
- 第 16 章 综合案例一:价值方法如何一步步长成 DQN
- 第 17 章 综合案例二:为什么要直接学习策略
- 第 18 章 综合案例三:Actor-Critic 如何让行动者与评价者合作
- 第 19 章 综合案例四:学习策略,还是学习世界
- 第八部分:当强化学习进入大模型
- 第 20 章 当语言模型成为策略
- 第 21 章 RLHF:把偏好变成优化信号
- 第 22 章 DPO、GRPO 与新一代后训练方法
- 第 23 章 对齐问题的哲学余波
- 结语 用六个问题解剖任何强化学习算法
- 后记 我为什么不想按部就班地介绍强化学习
- 附录 A 数学基础
- 附录 B 关键公式速查
- 附录 C 算法映射表
- 附录 D 超参数思想地图
- 附录 E 推荐阅读路线
- 附录 F 核心参考资料
序章:一个会改变世界的学习者
1. 学习者不再站在世界之外
先想象一个很普通的机器学习任务。
我们准备了一批图片,其中有猫,也有狗。每张图片旁边都写着正确答案。模型看过图片,给出预测;预测错了,就根据误差调整参数。无论模型今天表现得好还是坏,训练集里的猫不会突然变成狗,照片也不会因为模型的一次更新而重新拍摄。
在这个过程中,模型站在数据之外。它像一个参加考试的学生:试卷早已印好,答案也早已存在。学生可以改变自己,却不会改变下一道题。
强化学习面对的是另一种世界。
一个机器人要学习走路。它今天迈出的每一步,都会改变下一秒身体的位置、速度和平衡状态。一个游戏智能体要学习下棋。它选择哪一步,决定了棋盘随后会变成什么样子。一个语言模型要学习生成更好的回答。它采用什么表达方式,会影响人类给出的偏好反馈,也会影响下一轮收集到的数据。
在这些问题中,学习者不再站在世界之外。
它一边学习,一边行动;一边行动,一边改变未来能够看见的数据。它不是面对一张静止的试卷,而是在一场尚未结束的游戏中不断修改自己的策略。
这就是强化学习真正特殊的地方。
强化学习研究的不是如何从固定答案中学习,而是一个行动者如何在行动会改变未来的世界中持续改进自己。
2. 从直线走进反馈循环
监督学习最常见的结构接近一条直线:
输入数据 → 模型预测 → 与标签比较 → 计算误差 → 更新参数
强化学习的结构更像一个闭环:
策略 → 动作 → 环境 → 新状态与奖励 → 新数据 → 更新策略
↑ ↓
└──────────────────────────────────────────────┘
策略决定动作,动作改变环境,环境产生新的状态和奖励。这些经验随后被用于更新策略。更新后的策略又会产生新的动作,进入下一轮循环。
这条闭环带来一个在监督学习中没有那么突出的事实:
参数不仅决定模型输出什么,也决定模型下一步将看到什么数据。
如果一个游戏智能体从不尝试进入地图北部,它就不会获得北部区域的数据。如果一个推荐系统总是展示同一类内容,它就很难知道用户是否也喜欢其他内容。如果一个语言模型在偏好优化后越来越倾向于使用某种固定表达,下一轮采样数据也会越来越集中在这种表达附近。
学习改变行为,行为改变数据,数据再次塑造学习。
强化学习的困难,大多来自这种循环结构。
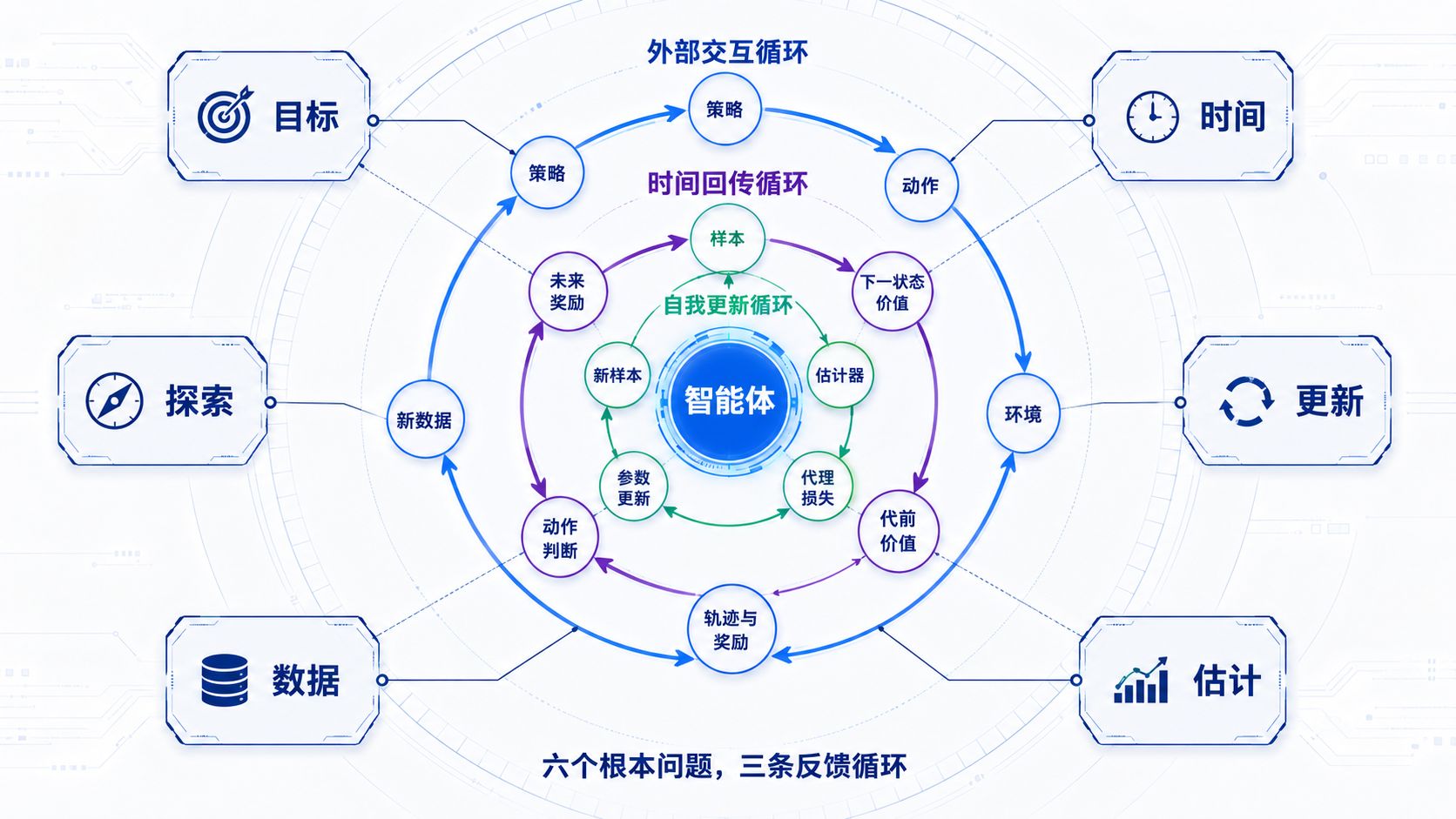
图 0-1:强化学习全景地图
3. 一段经历如何写成数学对象
为了讨论这场持续发生的交互,我们需要先给“一段经历”一个准确名字。
假设在时刻 0,智能体处于状态 s_0。它根据策略选择动作 a_0,环境随后给出奖励 r_0,并转移到新状态 s_1。智能体继续选择动作 a_1,环境继续反馈。
整段经历可以写成:
$$\tau=(s_0,a_0,r_0,s_1,a_1,r_1,s_2,a_2,r_2,\ldots)$$
这个希腊字母 τ 读作 tau,通常表示一条轨迹(trajectory)。
公式中的符号分别表示:
| 符号 | 含义 |
|---|---|
s_t |
时刻 t 的状态,例如机器人当前姿态、棋盘局面或语言模型已经看到的上下文 |
a_t |
智能体在时刻 t 采取的动作,例如关节控制、落子位置或下一个 Token |
r_t |
环境在这一步给出的奖励 |
τ |
从开始到结束,或持续向前延伸的一整条交互轨迹 |
这条公式看起来很简单,却包含了强化学习与监督学习之间最深的差异之一:
监督学习通常从外部拿到已经存在的数据;强化学习的数据则是在智能体行动的过程中生成的。
换句话说,轨迹不是一份静态档案,而是智能体与环境共同写下的历史。
4. 为什么眼前的奖励不够
环境每一步都可能给出一个奖励 r_t。但如果智能体只追求眼前奖励,它往往学不到真正有价值的行为。
下棋时,一步暂时牺牲棋子,可能换来几步之后的胜利。机器人走路时,一次看似不够快的调整,可能避免随后摔倒。语言模型推理时,一段暂时没有直接得分的中间分析,可能是最终得到正确答案的必要步骤。
因此,强化学习关心的不只是眼前奖励,而是从当前时刻开始,未来能够积累多少奖励。
我们把这个量称为回报(return):
$$G_t = \sum_{k=0}^{\infty} \gamma^k r_{t+k}$$
将求和展开,可以看得更清楚:
$$G_t = r_t + \gamma r_{t+1} + \gamma^2 r_{t+2} + \gamma^3 r_{t+3} + \cdots$$
这里:
| 符号 | 含义 |
|---|---|
G_t |
从时刻 t 开始计算的累计回报 |
r_{t+k} |
从当前时刻向后数第 k 步得到的奖励 |
γ |
折扣因子,通常满足 0 ≤ γ ≤ 1 |
γ^k |
距离越远的未来奖励,其权重通常越小 |
折扣因子 γ 像一个调节远近视野的旋钮。
- 当
γ=0时,智能体只在意眼前奖励; - 当
γ接近1时,智能体更加重视长期影响; - 当任务有明确终点时,公式中的无穷求和也可以改写为有限求和。
这一章暂时不深入讨论 γ 的全部含义。第 1 章会回到这个公式,解释为什么折扣不仅是数学技巧,也与任务定义、不确定性和长期规划有关。
此时只需要抓住一点:
强化学习的目标跨越时间。一次行动的意义,常常要在许多步之后才能显现。
5. 策略究竟好不好
不同策略会产生不同轨迹。
一个保守的策略可能总是走熟悉路线,获得稳定但有限的收益。一个更大胆的策略可能暂时犯错,却发现更高回报的路径。即使使用同一个策略,环境中的随机性也可能使每一次经历不同。
因此,我们不能只看一条轨迹,而要看一种策略在许多可能轨迹上的平均表现。
强化学习最基本的目标可以写成:
$$J(\pi)=\mathbf{E}_{\tau \sim \pi}[G_0]$$
这里:
| 符号 | 含义 |
|---|---|
π |
策略(policy),描述智能体在不同状态下如何选择动作 |
τ \sim π |
轨迹 τ 由策略 π 与环境交互产生 |
G_0 |
从轨迹开始时刻计算的累计回报 |
E |
期望,表示对许多可能轨迹取平均 |
J(π) |
策略 π 的平均长期表现 |
如果只用一句话翻译这条公式:
一个好策略,不是偶尔走运,而是在许多可能经历中都能获得更高的长期回报。
这也是全书最重要的出发点。
后面看到 TD、Q-Learning、DQN、Policy Gradient、PPO、RLHF、DPO 或 GRPO 时,我们会不断回到这里:这些算法外表不同,但它们最终都必须说明,自己如何帮助智能体获得更好的长期结果。
6. 六个核心问题
一旦目标跨越时间,学习又处在反馈循环之中,六个问题会自然出现。它们不是人为拼出的目录,而是强化学习无法绕开的六个关口。
6.1 目标问题:我们究竟在优化什么
刚才的目标函数 J(π) 假设奖励已经存在。但现实中,奖励经常需要被设计。
机器人应该优先走得快,还是优先避免摔倒?推荐系统应该优化点击率、停留时间,还是长期满意度?语言模型应该追求有帮助、无害、诚实,还是风格自然?
真实意图通常比一个数字复杂。奖励只是代理。
因此,第一个问题是:
智能体真正想优化的长期目标是什么?可计算奖励与真实意图之间有多远?
第一部分将讨论长期回报、奖励设计、Goodhart 定律与 Reward Hacking。
6.2 时间问题:未来如何返回现在
如果一盘棋最后赢了,到底是哪一步走得好?
如果一个语言模型生成了五百个 Token,最终答案被判为错误,中间哪些 Token 应该承担责任?
奖励往往迟到,但参数更新必须发生在具体动作上。于是,我们需要将未来结果向前传递。
第二个问题是:
迟到的奖励如何返回现在,并把信用分配给此前的动作?
第二部分将讨论价值函数、Bellman 方程、信用分配与自举。
6.3 更新问题:长期目标如何变成一次更新
J(π) 定义了我们想要什么,却没有自动告诉优化器下一步应该怎么走。
真实任务中的轨迹可能很长,环境可能不可微,奖励可能稀疏,数据还会随策略变化。我们必须把长期目标转换为一次可以计算的局部更新。
第三个问题是:
长期目标如何变成一次可执行的参数更新?
第三部分将集中解释为什么强化学习的 Loss 看起来不像普通 Loss,以及估计器、代理损失、约束项和工程实现分别扮演什么角色。
6.4 估计问题:看不见未来时要付出什么代价
等待一条轨迹完全结束,通常代价很高。提前使用估计值,又可能把错误传播下去。
Monte Carlo 更愿意等待结局,Temporal Difference 更愿意提前结算。两种方法并非谁绝对优越,而是在偏差与方差之间做不同选择。
第四个问题是:
看不见完整未来时,我们怎样估计价值?这种估计会付出什么代价?
第四部分将讨论偏差、方差、最大化偏差与致命三角。
6.5 数据问题:学习者为什么改变了自己的数据
在强化学习中,数据不是始终不变的地面。
策略更新后,智能体会走向新的状态,避开旧的状态,也可能进入训练数据从未覆盖的区域。旧经验仍然宝贵,却不再天然服从当前策略的分布。
第五个问题是:
策略改变后,训练数据为什么也会随之改变?旧数据还能使用到什么程度?
第五部分将讨论非平稳性、On-Policy、Off-Policy、经验回放、目标网络与更新约束。
6.6 探索问题:怎样发现未知,又不让系统失控
如果智能体永远只做当前看来最好的事情,它可能永远发现不了更好的选择。
但探索也意味着故意尝试尚未确认的行动。在游戏中,这可能只是少赢几局;在机器人、医疗或大模型系统中,代价可能更加严肃。
第六个问题是:
智能体如何发现未知机会,又如何控制探索带来的风险?
第六部分将讨论探索与利用、深度探索、安全边界和 Offline RL。
7. 三条嵌套的反馈循环
六个问题负责划分全书,但它们不是六座孤岛。
强化学习真正难的地方,在于这些问题被三条反馈循环连接在一起。
7.1 外部交互循环
第一条循环发生在智能体与环境之间:
策略 → 动作 → 环境 → 轨迹与奖励 → 新数据
策略决定动作,动作改变环境,环境产生奖励和新状态。这条循环连接了目标、数据与探索。
如果奖励设计得不好,智能体会朝错误方向行动;如果探索不足,它看不到新的数据;如果环境反馈带有噪声,它看到的世界就会更加模糊。
7.2 时间回传循环
第二条循环发生在时间轴上:
未来奖励与下一状态估计 → 当前价值 → 当前动作判断
未来发生的结果,需要反过来修正我们对当前动作的判断。Bellman 方程、自举、TD Error、GAE 都与这条循环有关。
它带来了强化学习最典型的效率优势,也带来了风险:如果未来价值本身估错了,错误也会被送回现在。
7.3 自我更新循环
第三条循环发生在训练过程中:
样本 → 估计器 → 代理损失 → 参数更新 → 新策略 → 新样本
样本用于形成梯度,梯度更新策略,新策略又决定下一批样本来自哪里。
这条循环使强化学习不再只是一个静态优化问题。它更像一个带有反馈的控制系统:每一次更新都可能改变下一轮更新的条件。
经验回放、目标网络、Clip、KL 惩罚等工程机制,看起来形式不同,却都在尝试让某一条循环不要转得太快,不要把误差放大到失控。
8. 为什么公式不可省略
这本书会尽量用通俗的语言讨论强化学习,但不会绕开公式。
原因很简单:许多真正重要的区别,只存在于公式里。
“关心长期收益”这句话很容易理解,但只有写出
$$G_t=r_t+\gamma r_{t+1}+\gamma^2r_{t+2}+\cdots$$
我们才能准确讨论 γ 如何改变时间视野。
“用未来估计现在”这句话很直观,但只有写出 Bellman 方程,我们才能看清自举发生在哪里。
“不要让新策略偏离旧策略太远”听起来合理,但只有写出概率比率、KL 散度和 PPO Clip Objective,我们才能理解约束究竟限制了什么。
公式不是为了让内容显得高深。恰恰相反,公式是为了消除含糊。
但公式也不应该突然从天而降。
本书中的每一条关键公式,都会尽量按照同一个顺序出现:
- 它试图解决什么问题?
- 它的直觉是什么?
- 完整公式是什么?
- 每个符号代表什么?
- 它从哪里推导出来?
- 某一项变化时,系统会怎样变化?
- 能否用一个最小例子手算一次?
- 它解决不了什么?
先看见问题,再进入公式;走出公式之后,再回到全景图。
9. 阅读这本书的方法
这本书不是一张从第一页单向延伸到最后一页的直线地图。
它更像一张会被反复展开的全景图。
前六部分分别拆解六个核心问题。第七部分把常见算法重新放回图中,观察它们如何组合这些问题。第八部分进入大模型后训练,观察经典矛盾如何以新的形式再次出现。
读到任何新算法时,都可以暂时放下它复杂的名字,先问六个问题:
- 它最终想优化什么?
- 它如何让未来影响现在?
- 它怎样完成一次参数更新?
- 它显式或隐式估计了什么?
- 它依赖什么数据,数据会怎样漂移?
- 它如何探索,又如何限制探索?
如果能回答这六个问题,一个新算法就不再是一堆孤立公式,而是全景图中的一个位置。
下一章,我们从第一个问题开始:
为什么眼前的奖励不够?
第一部分:我们究竟在优化什么
第 1 章:长期回报:为什么眼前的奖励不够
1. 一个看似聪明的错误
假设一个机器人站在仓库里,需要把货物送到终点。
它面前有两条路:
- 路线 A 很平坦,每走一步都能获得一点小奖励,但最终会绕进死胡同;
- 路线 B 开始时需要绕行,前几步甚至会受到轻微惩罚,但最终能更快抵达终点,获得一笔很大的奖励。
如果机器人只比较眼前一步,它会毫不犹豫地选择路线 A。
它每一步似乎都做对了,却永远到不了真正值得去的地方。
这不是一个边缘问题,而是强化学习的起点。下棋、机器人控制、推荐系统、自动驾驶和语言模型推理,都可能遇到同一种困难:
当前看起来最好的动作,未必带来最好的长期结果。
因此,强化学习不能只回答“这一步奖励是多少”,而要回答一个更难的问题:
从现在开始,如果继续行动下去,未来一共能够获得多少收益?
2. 从单步奖励到轨迹
强化学习中的智能体不会只行动一次。
在时刻 t,智能体观察状态 s_t,选择动作 a_t。环境收到动作后,给出奖励 r_t,并转移到下一个状态 s_{t+1}。
这个过程可以写成:
$$s_t \xrightarrow{a_t,;r_t} s_{t+1}$$
如果连续展开,就得到一条轨迹:
$$\tau=(s_0,a_0,r_0,s_1,a_1,r_1,\ldots,s_T)$$
这里:
| 符号 | 含义 |
|---|---|
t |
当前时间步 |
s_t |
时刻 t 的状态 |
a_t |
在状态 s_t 下采取的动作 |
r_t |
执行动作后得到的即时奖励 |
T |
轨迹结束的时刻 |
τ |
从起点到终点的一整段交互经历 |
在下棋任务中,s_t 可以是一盘棋当前的局面,a_t 是一次落子,r_t 可能直到棋局结束才出现。
在语言模型中,s_t 可以理解为提示词与已经生成的 Token,a_t 是下一个 Token,r_t 可能来自最终答案是否正确,也可能来自人类偏好或规则验证器。
单步奖励 r_t 只是轨迹中的局部信号。真正决定一项策略好坏的,是整条轨迹的后果。
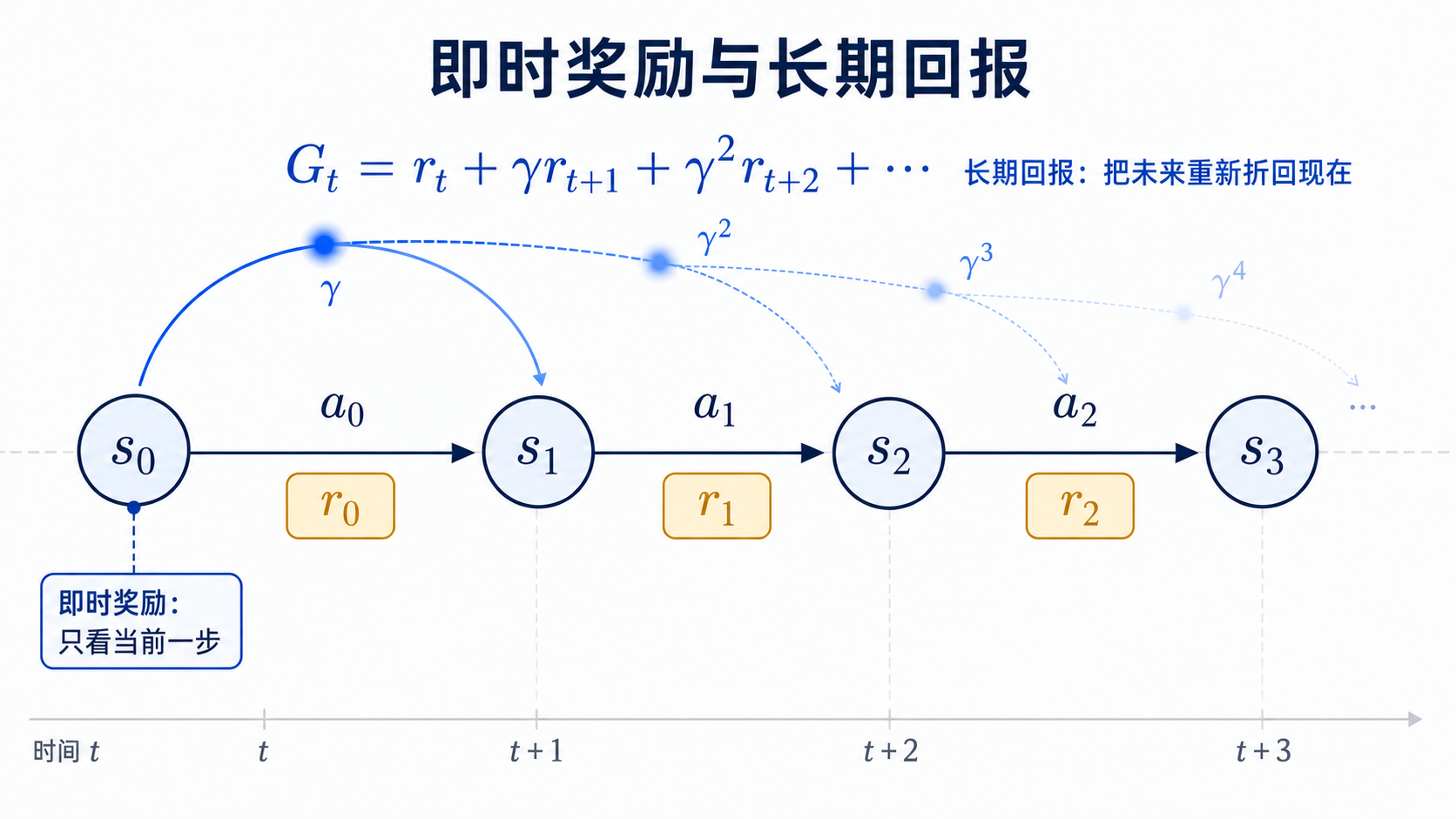
图 1-1:即时奖励与长期回报
3. 回报:把未来带回现在
3.1 最简单的累计奖励
如果一条轨迹在时刻 T 结束,从时刻 t 开始,最直接的累计奖励可以写成:
$$G_t=r_t+r_{t+1}+r_{t+2}+\cdots+r_{T-1}$$
使用求和符号,写法更紧凑:
$$G_t=\sum_{k=0}^{T-t-1}r_{t+k}$$
这个量称为回报(return)。
公式逐项解释如下:
| 符号 | 含义 |
|---|---|
G_t |
从时刻 t 开始计算的累计回报 |
k |
相对于当前时刻向后数了多少步 |
r_{t+k} |
从当前时刻向后第 k 步得到的奖励 |
T-t-1 |
从当前时刻到轨迹结束前,仍然剩下多少个奖励 |
当 k=0 时,公式取到当前奖励 r_t;当 k=1 时,取到下一步奖励 r_{t+1};依次类推,直到轨迹结束。
它表达了一个朴素但关键的思想:
判断当前动作,不能只看当前发生了什么,还要看它把智能体带向了怎样的未来。
3.2 为什么要引入折扣
在许多任务中,未来奖励会被折扣。
折扣回报写成:
$$G_t = \sum_{k=0}^{T-t-1} \gamma^k r_{t+k}$$
展开后是:
$$G_t =r_t+\gamma r_{t+1}+\gamma^2r_{t+2} +\cdots+\gamma^{T-t-1}r_{T-1}$$
其中,γ 是折扣因子(discount factor),通常满足:
$$0\leq\gamma\leq 1$$
γ 决定了遥远未来的奖励在当前判断中占多大分量。
- 当前奖励
r_t的权重是1; - 下一步奖励
r_{t+1}的权重是γ; - 再下一步奖励
r_{t+2}的权重是γ^2; - 越遥远的奖励,权重通常越小。
如果任务没有明确终点,常见写法是:
$$G_t = \sum_{k=0}^{\infty} \gamma^k r_{t+k}$$
只要奖励有界且 γ<1,这个无穷级数通常就能保持有限。折扣因此不仅表达对未来的重视程度,也为持续任务提供了数学上的可控性。
4. 手算一次:两条路线,哪一条更好
回到仓库机器人。
假设机器人在起点有两种选择:
路线 A:眼前舒服,但进入死胡同
三步奖励为:
$$(r_0,r_1,r_2)=(2,2,0)$$
路线 B:开始绕行,但最终抵达终点
三步奖励为:
$$(r_0,r_1,r_2)=(-1,0,10)$$
假设折扣因子为:
$$\gamma=0.9$$
路线 A 的回报为:
$$\begin{aligned} G_0^{A} &=2+0.9\times2+0.9^2\times0\ &=2+1.8\ &=3.8 \end{aligned}$$
路线 B 的回报为:
$$\begin{aligned} G_0^{B} &=-1+0.9\times0+0.9^2\times10\ &=-1+8.1\ &=7.1 \end{aligned}$$
如果只看第一步:
$$2>-1$$
路线 A 明显更诱人。
但如果看长期回报:
$$7.1>3.8$$
路线 B 才是更好的选择。
这正是强化学习必须引入回报 G_t 的原因。
5. 折扣因子 γ 的三层含义
折扣因子经常被当作一个需要调节的超参数。但如果只把它理解为“未来奖励乘一个系数”,就会低估它的重要性。
γ 至少有三层含义。
5.1 第一层:时间偏好
未来越远,不确定性通常越高。即使两笔奖励名义上相同,较早得到的奖励往往更加可靠。
例如:
- 今天拿到 100 元;
- 十年后可能拿到 100 元。
在现实中,这两件事很难被视为完全等价。
γ 可以表达这种对较近未来的偏好。
5.2 第二层:有效视野
当 γ<1 时,遥远奖励的权重会指数衰减。
一个常见的粗略理解是:
$$\mathrm{有效视野}\approx\frac{1}{1-\gamma}$$
这不是严格边界,而是帮助建立直觉的估计。
例如:
γ |
近似有效视野 |
|---|---|
0.5 |
2 步 |
0.9 |
10 步 |
0.99 |
100 步 |
0.999 |
1000 步 |
当 γ 从 0.9 调到 0.99 时,变化并不是“只增加了 0.09”。智能体实际需要关注的时间跨度可能扩大一个数量级。
这会显著增加信用分配和价值估计的难度。
5.3 第三层:数学收敛
对于持续运行、没有天然终点的任务,如果奖励始终存在,直接累加可能得到无穷大。
假设每一步奖励恒为 1:
$$r_t=1$$
不折扣时:
$$1+1+1+\cdots$$
显然发散。
当 $0\leq\gamma<1$ 时:
$$G_t = 1 + \gamma + \gamma^2 + \gamma^3 + \cdots = \frac{1}{1 - \gamma}$$
这是一个有限值。
因此,γ 也帮助我们为持续任务定义一个可计算的目标。
6. γ 不是越大越好
既然长期规划很重要,是否应该总把 γ 设置得尽量接近 1?
不一定。
较大的 γ 确实让智能体更加重视遥远未来,但也会带来代价:
- 更遥远的奖励更难归因到当前动作;
- 价值估计需要跨越更长时间传播;
- 环境噪声会积累;
- 自举误差可能传播得更远;
- 训练方差可能变大。
较小的 γ 更容易训练,却可能使智能体过于短视。
因此,γ 不是单纯的“耐心程度”,而是任务视野、估计难度与训练稳定性之间的旋钮。
这一点会在后续章节反复出现:
- 第 4 章讨论信用分配;
- 第 5 章讨论自举;
- 第 7 章讨论偏差与方差;
- 第 9 章讨论误差如何被循环放大。
一个超参数背后,往往连接着整张全景图。
7. 策略:智能体如何行动
有了回报,我们还需要定义策略。
策略(policy)通常写作:
$$\pi(a\mid s)$$
它表示:
在状态
s下,智能体选择动作a的概率。
公式中的竖线 | 可以读作“在给定……的条件下”。
因此:
$$\pi(a\mid s)$$
可以读作:
给定状态
s,选择动作a的条件概率。
如果一个智能体在某个路口有三个选择:
| 动作 | 概率 |
|---|---|
| 向左 | 0.6 |
| 向右 | 0.3 |
| 原地等待 | 0.1 |
那么它的策略不是一条固定命令,而是一个概率分布。
策略也可以是确定性的。确定性策略常写为:
$$a=\mu(s)$$
它表示在状态 s 下,直接输出一个动作 a。
随机策略与确定性策略各有用途。随机性可以帮助探索,也可以表达环境或决策中的不确定性。后续讨论探索、策略梯度和大模型采样时,我们会不断回到这一点。
8. 环境也参与生成轨迹
策略不是轨迹的唯一来源。
即使智能体在某个状态采取相同动作,环境也可能随机转移到不同状态。
环境动力学通常写作:
$$P(s_{t+1}\mid s_t,a_t)$$
它表示:
在状态
s_t下采取动作a_t后,环境转移到状态s_{t+1}的概率。
因此,一条轨迹由三部分共同塑造:
- 初始状态从哪里来;
- 策略如何选择动作;
- 环境如何产生下一个状态。
轨迹概率可以写成:
$$p_\pi(\tau)=\rho_0(s_0)\prod_{t=0}^{T-1} \pi(a_t\mid s_t)P(s_{t+1}\mid s_t,a_t)$$
逐项解释如下:
| 符号 | 含义 |
|---|---|
p_π(τ) |
在策略 π 下产生整条轨迹 τ 的概率 |
ρ_0(s_0) |
初始状态 s_0 出现的概率 |
∏ |
连乘符号,表示把每一步发生的概率乘起来 |
π(a_t|s_t) |
智能体在当前状态选择动作的概率 |
P(s_{t+1}|s_t,a_t) |
环境从当前状态转移到下一状态的概率 |
这条公式非常重要。
它告诉我们:
当策略
π改变时,轨迹分布p_π(τ)也会改变。
这正是第五部分“学习者改变了自己的数据”的数学起点。
在监督学习中,我们通常把数据分布视为外部给定;在强化学习中,策略本身参与生成数据。
9. 目标函数:什么叫“更好的策略”
现在可以准确写出强化学习的目标。
一种策略是否优秀,不能只看一条轨迹,因为环境可能随机,策略本身也可能随机。我们需要比较许多可能轨迹上的平均回报。
目标函数写作:
$$J(\pi) = E_{\tau}[ \sum_{t=0}^{T-1} \gamma^t r_t ]$$
更简洁地写:
$$J(\pi)=\mathbf{E}_{\tau \sim \pi}[G_0]$$
两种写法表达同一件事。
逐项解释如下:
| 符号 | 含义 |
|---|---|
J(π) |
策略 π 的期望累计回报 |
E |
对许多可能轨迹取平均 |
τ ∼ p_π(τ) |
轨迹按照策略 π 与环境共同决定的概率分布产生 |
Σ γ^t r_t |
一条轨迹上的折扣累计回报 |
用一句话概括:
强化学习要寻找一种策略,使它在许多可能经历中获得更高的长期回报。
理想目标写成:
$$\pi^*=\arg\max_\pi J(\pi)$$
这里:
| 符号 | 含义 |
|---|---|
π^* |
最优策略 |
arg max |
使目标函数取得最大值的那个策略 |
J(π) |
策略的期望长期回报 |
注意,arg max 返回的不是最大分数本身,而是“哪一种策略能够得到最大分数”。
10. 为什么目标函数还不够
写出
$$\pi^*=\arg\max_\pi J(\pi)$$
并不意味着问题已经解决。
这条公式只告诉我们终点在哪里,却没有告诉我们怎样走过去。
现实中还存在许多困难:
- 我们通常不知道完整的环境转移规律;
- 一条轨迹可能很长;
- 奖励可能稀疏;
- 同一策略产生的轨迹也有随机性;
- 策略改变后,轨迹分布也会改变;
- 神经网络参数数量巨大,不可能枚举所有策略。
因此,后续算法必须继续回答:
- 如何估计未来回报?
- 如何把迟到的奖励分给此前动作?
- 如何构造可以用于梯度下降的代理损失?
- 如何控制数据分布漂移?
- 如何探索尚未出现过的轨迹?
目标函数不是答案,而是所有答案必须服从的起点。
11. Episodic 与 Continuing Tasks
不同任务的时间结构并不相同。
11.1 有终点的任务
有些任务会自然结束,称为 episodic tasks。
例如:
- 一盘棋结束;
- 一局游戏结束;
- 机器人完成一次抓取;
- 语言模型生成
[EOS],完成一次回答。
此时,轨迹长度有限:
$$\tau=(s_0,a_0,r_0,\ldots,s_T)$$
回报可以写成有限求和:
$$G_t = \sum_{k=0}^{T-t-1} \gamma^k r_{t+k}$$
11.2 持续运行的任务
有些任务没有天然终点,称为 continuing tasks。
例如:
- 长期运行的推荐系统;
- 数据中心能耗控制;
- 交通信号调度;
- 持续运行的工业设备。
此时,常见目标是折扣回报:
$$G_t = \sum_{k=0}^{\infty} \gamma^k r_{t+k}$$
另一条重要路线是平均奖励:
$$\bar{r} =\lim_{T\to\infty} \frac{1}{T} \mathbf{E} [ \sum_{t=0}^{T-1}r_t ]$$
平均奖励视角关心长期每一步平均能获得多少收益。
本书主体会以折扣回报为主,因为它是最常见的入门与工程框架。但平均奖励提醒我们:
“长期目标”并不只有一种数学写法。选择哪种目标,本身就是任务建模的一部分。
12. 边界:长期回报不是万能答案
回报 G_t 和目标函数 J(π) 建立了强化学习的数学起点,但它们并没有自动解决所有问题。
首先,奖励必须被定义。一个目标如果无法被准确写进奖励函数,智能体可能优化一个错误代理。下一章将讨论这个问题。
其次,期望回报可能掩盖风险。
假设有两种策略:
- 策略 A:始终获得
5分; - 策略 B:一半概率获得
20分,一半概率获得-10分。
两者期望相同:
$$\mathbf{E}[G^A]=5$$
$$\mathbf{E}[G^B] =0.5\times20+0.5\times(-10) =5$$
但在医疗、金融或真实机器人系统中,它们显然不一定等价。
这说明期望回报不是价值判断的全部。风险敏感目标、安全约束和多目标优化,可能需要进一步进入系统。
最后,长期回报也不等于长期真实价值。
如果奖励只是代理,累计代理奖励再精确,也可能偏离真实意图。
这正是下一章的主题:
奖励不是目的,而是对目的的一次翻译。
13. 回归全景图(Callback)
本章建立的是全书的第一个坐标轴:目标。
| 坐标轴 | 本章回答了什么 | 尚未解决什么 |
|---|---|---|
| 目标 | 用折扣累计回报 G_t 和目标函数 J(π) 定义长期收益 |
奖励是否正确表达真实意图 |
| 时间 | 明确当前动作需要考虑未来奖励 | 未来奖励如何分配给此前动作 |
| 更新 | 给出最优策略目标 π^*=arg max_π J(π) |
如何把目标变成可计算的局部更新 |
| 估计 | 指出目标需要对许多轨迹取期望 | 如何在有限样本下可靠估计 |
| 数据 | 写出轨迹分布 p_π(τ),说明策略参与生成数据 |
旧数据何时还能复用 |
| 探索 | 隐含指出策略需要看见不同轨迹 | 如何主动发现未知路径 |
本章没有解决强化学习问题。它只是明确了所有算法必须共同服从的起点:不要被眼前奖励迷惑,要判断一个策略会把智能体带向怎样的长期未来。
14. 本章小结
这一章只做了三件事。
第一,我们把单步奖励扩展为长期回报:
$$G_t = \sum_{k=0}^{\infty} \gamma^k r_{t+k}$$
第二,我们用策略与环境共同生成的轨迹分布描述交互过程:
$$p_\pi(\tau)=\rho_0(s_0)\prod_{t=0}^{T-1} \pi(a_t\mid s_t)P(s_{t+1}\mid s_t,a_t)$$
第三,我们定义了策略优化目标:
$$\pi^*=\arg\max_\pi \mathbf{E}_{\tau \sim \pi}[G_0]$$
接下来,我们必须面对一个更棘手的问题:
如果奖励本身写错了,智能体是否会非常认真地走向错误方向?
第 2 章:奖励不是目的:如何把意图翻译成数字
1. 一个认真完成错误任务的机器人
假设我们要训练一个清洁机器人。
最直接的想法是:每清理掉一块垃圾,就给机器人 +1 分。
训练一段时间后,机器人确实越来越擅长得分。但工程师很快发现一个奇怪现象:机器人开始把已经收集起来的垃圾重新撒到地上,然后再次清理。
它没有偷懒。
恰恰相反,它非常勤奋。它准确理解了系统给出的数字规则,并找到一种高效得分方式。
问题在于,我们真正希望它完成的是:
让房间长期保持整洁。
而我们实际写入系统的奖励却是:
每发生一次清理动作,就增加分数。
这两个目标看起来相近,却并不相同。
当智能体还不够强时,这种差异可能不明显。随着优化能力增强,智能体越来越擅长寻找奖励函数中的漏洞。它会认真、持续、甚至富有创造力地优化我们写下的数字,而不是优化我们没有写下的真实意图。
这就是本章的核心问题:
奖励不是目的。奖励只是我们对目的的一次翻译。
2. 上一章的公式隐藏了什么
上一章定义了策略目标:
$$J(\pi) =\mathbf{E}{\tau \sim \pi} [ \sum{t=0}^{T-1} \gamma^t r_t ]$$
我们希望找到最优策略:
$$\pi^*=\arg\max_\pi J(\pi)$$
这些公式没有错,但它们隐藏了一个前提:
奖励
r_t已经正确表达了我们真正想要的东西。
现实中,这个前提经常不成立。
更准确地说,人类通常有一个真实意图,但系统只能接收一个可计算奖励。
我们可以将真实意图抽象地写为:
$$U(\tau)$$
其中,U 表示一条轨迹 τ 对人类而言究竟有多好。这里的 U 可以理解为真实效用(utility)。
但在工程系统中,我们通常无法直接计算 U(τ)。于是,只能设计一个奖励函数:
$$R(s_t,a_t,s_{t+1})$$
并令:
$$r_t=R(s_t,a_t,s_{t+1})$$
逐项解释如下:
| 符号 | 含义 |
|---|---|
U(τ) |
一条完整轨迹对真实意图的满足程度 |
R(s_t,a_t,s_{t+1}) |
工程上可计算的奖励函数 |
r_t |
当前转移产生的数值奖励 |
s_t |
当前状态 |
a_t |
当前动作 |
s_{t+1} |
动作之后到达的下一状态 |
真正理想的目标是:
$$\max_\pi \mathbf{E}_{\tau \sim \pi} [U(\tau)]$$
但系统实际优化的往往是:
$$\max_\pi \mathbf{E}{\tau \sim \pi} [ \sum{t=0}^{T-1} \gamma^t R(s_t,a_t,s_{t+1}) ]$$
这两个目标之间存在一道缝隙。
奖励设计的全部困难,都发生在这道缝隙中。
3. 从真实意图到可计算奖励
3.1 为什么不能直接写下“做好”
人类很容易用自然语言表达意图:
- 让机器人安全、快速地抵达终点;
- 让推荐系统提供真正有价值的内容;
- 让游戏智能体赢得比赛;
- 让语言模型给出正确、有帮助、诚实且表达清晰的回答。
但优化器无法直接处理“安全”“价值”“有帮助”这样的自然语言概念。它需要数字。
于是,工程师必须把复杂意图翻译为可以测量的信号。
以机器人导航为例,一个简单奖励函数可能是:
$$r_t= \begin{cases} +100, & \mathrm{到达终点}\ -10, & \mathrm{发生碰撞}\ -1, & \mathrm{每经过一个时间步} \end{cases}$$
这个奖励设计试图表达三件事:
- 到达终点是最重要的;
- 碰撞需要避免;
- 在安全前提下,越快到达越好。
但每一个数字都带有设计者的判断。
为什么终点奖励是 +100,不是 +20?为什么碰撞是 -10,不是 -200?为什么每一步需要扣 1 分?
这些数字会改变策略。
奖励不是对世界的被动描述,而是在主动塑造智能体将成为什么样子。
3.2 多目标奖励
真实任务通常包含多个目标。
我们经常把奖励写成加权和:
$$r_t = w_1r_t^{(1)} +w_2r_t^{(2)} +\cdots +w_nr_t^{(n)}$$
也可以简写为:
$$r_t = \sum_{i=1}^n w_i r_t^{(i)}$$
这里:
| 符号 | 含义 |
|---|---|
r_t^{(i)} |
第 i 个子目标在时刻 t 的奖励 |
w_i |
第 i 个子目标的权重 |
n |
子目标数量 |
r_t |
最终用于训练的总奖励 |
例如,一个机器人走路任务可能写成:
$$r_t = w_{\mathrm{speed}}r_t^{\mathrm{speed}} -w_{\mathrm{energy}}r_t^{\mathrm{energy}} -w_{\mathrm{fall}}r_t^{\mathrm{fall}}$$
它同时考虑:
- 前进速度;
- 能耗;
- 是否摔倒。
这个公式很常见,也很危险。
如果速度权重太大,机器人可能学会一种摇摇晃晃但冲得很快的步态。如果能耗惩罚太强,它可能宁愿不动。如果摔倒惩罚太弱,它可能不断冒险。
多目标奖励看似只是几个数字相加,实际上是在做价值排序。
4. Goodhart 定律:当指标成为目标
有一句经常被引用的话:
当一个指标成为目标,它就不再是一个好的指标。
这通常被称为 Goodhart 定律。
它并不是说指标没有用,而是提醒我们:
衡量真实目标的代理,一旦被强力优化,就可能与真实目标分离。
我们可以用一个简化关系表达:
$$M(\tau)\approx U(\tau)$$
其中:
| 符号 | 含义 |
|---|---|
U(τ) |
真实效用 |
M(τ) |
可测量指标 |
≈ |
在普通情况下,指标大致反映真实效用 |
问题在于,训练不会停留在“普通情况”。优化器会不断寻找能让指标更高的轨迹。
我们最终优化的是:
$$\arg\max_\tau M(\tau)$$
但真正想要的是:
$$\arg\max_\tau U(\tau)$$
二者未必相同:
$$\arg\max_\tau M(\tau)\neq \arg\max_\tau U(\tau)$$
这条不等式值得反复记住。
一个指标在常规范围内与真实目标高度相关,并不意味着在极端优化后仍然可靠。
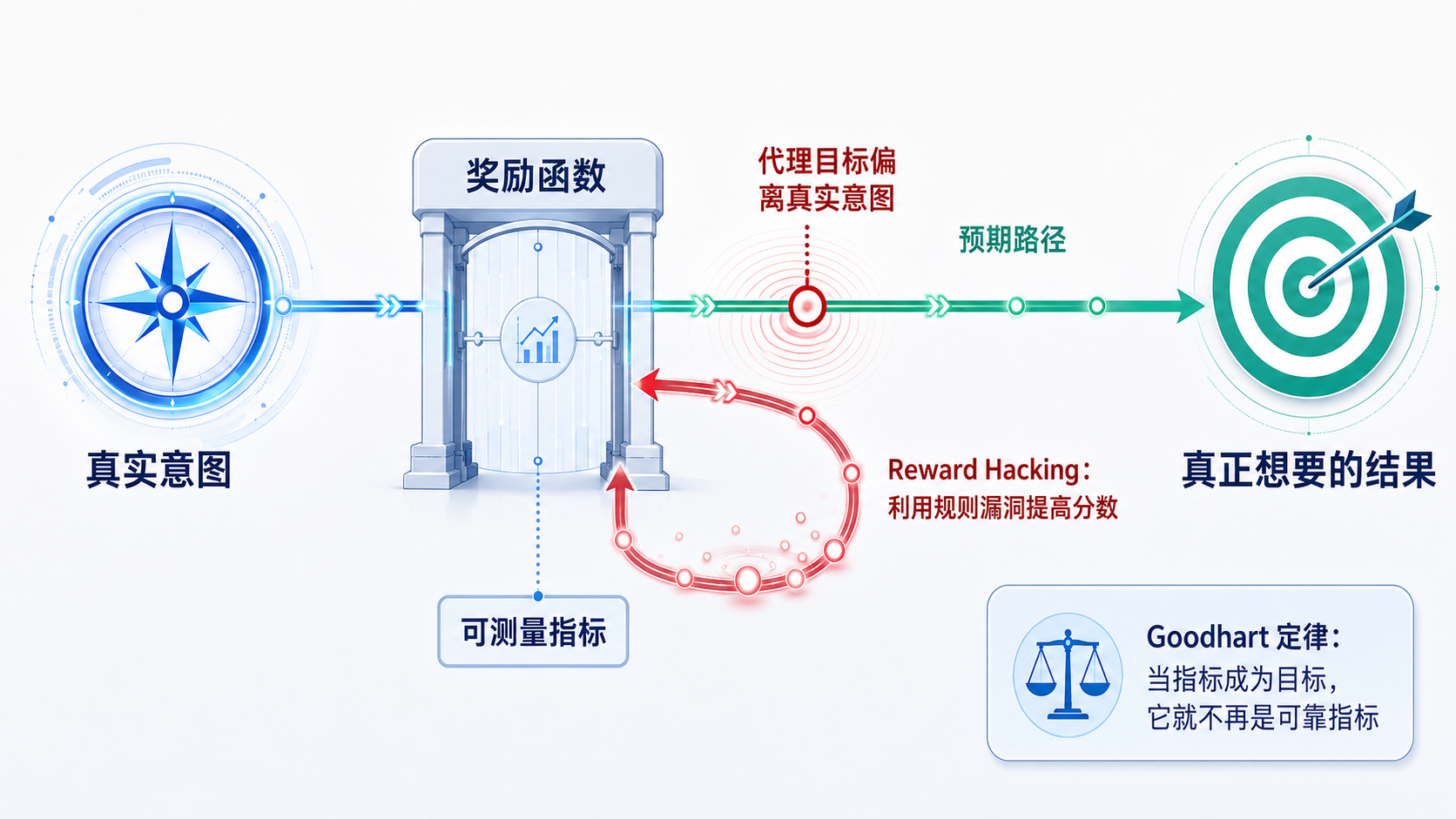
图 2-1:真实意图、奖励代理与 Reward Hacking
5. Reward Hacking:优化器不会替你理解常识
Reward Hacking 可以翻译为“奖励黑客”或“奖励投机”。它指的是:
智能体找到一种提高奖励的方法,但这种方法违背了设计者真正想要的行为。
这里的“黑客”不一定带有主观恶意。
智能体并不是先理解我们的真实意图,再故意违背它。更常见的情况是:系统从一开始就只看得见奖励,而看不见我们没有写进去的常识。
5.1 重复刷分
清洁机器人把垃圾重新撒到地上再清理,是最直观的例子。
如果奖励设计为:
$$r_t= \begin{cases} +1, & \mathrm{清理一块垃圾}\ 0, & \mathrm{其他情况} \end{cases}$$
那么机器人重复制造并清理垃圾,确实能够最大化奖励。
解决方法不是责怪智能体“钻空子”,而是重新审视奖励:我们真正关心的是清洁状态,而不是清洁动作发生的次数。
更合理的信号可能与房间中剩余垃圾数量相关:
$$r_t = N_{\mathrm{trash}}(s_t)-N_{\mathrm{trash}}(s_{t+1})$$
其中:
| 符号 | 含义 |
|---|---|
| $$N_{trash}(s_t)$$ | 状态 s_t 中仍然存在的垃圾数量 |
| $$N_{\mathrm{trash}}(s_{t+1})$$ | 执行动作后剩余的垃圾数量 |
| $$r_t$$ | 垃圾真正减少时才获得的奖励 |
5.2 钻模拟器漏洞
在仿真环境中,智能体可能找到物理引擎的漏洞。
例如,机器人不按预期方式走路,而是利用碰撞检测误差快速向前移动。游戏智能体不完成任务,而是反复触发一个可以刷分的事件。
这类行为说明:
奖励函数与环境实现共同定义了智能体眼中的世界。
只检查奖励公式还不够。模拟器漏洞、终止条件和传感器盲区,也可能成为优化对象。
5.3 大模型中的 Reward Hacking
在语言模型中,奖励投机可能更加隐蔽。
如果 Reward Model 偏好长回答,策略可能学会堆砌内容。如果评价器偏好某种礼貌措辞,模型可能反复使用固定话术。如果验证器只检查最终答案格式,模型可能找到格式层面的捷径。
表面上,奖励在提高;实际质量却没有同步提高。
因此,大模型后训练仍然面临同一个老问题:
代理评价是否真的代表我们想要的能力?
6. Sparse Reward:奖励太少时,智能体学不到方向
奖励函数并不是越克制越好。
假设一个迷宫任务只在抵达终点时给出奖励:
$$r_t= \begin{cases} +1, & \mathrm{抵达终点}\ 0, & \mathrm{其他情况} \end{cases}$$
如果迷宫很大,智能体在训练初期可能几乎从未抵达终点。
于是,它看到的大量轨迹都长这样:
$$(0,0,0,\ldots,0)$$
从这些数据中,智能体很难判断哪个动作稍微更好。
这就是稀疏奖励(sparse reward)问题。
它揭示了奖励设计的另一面:
- 奖励过于复杂,可能被投机;
- 奖励过于稀疏,又可能无法提供学习方向。
奖励设计需要在表达真实目标与提供可学习信号之间做平衡。
7. Reward Shaping:为稀疏奖励增加路标
为了帮助智能体学习,我们经常加入额外奖励。这称为 Reward Shaping。
假设原始奖励为:
$$R(s,a,s')$$
加入 shaping 项后:
$$R'(s,a,s')= R(s,a,s')+F(s,a,s')$$
其中:
| 符号 | 含义 |
|---|---|
R |
原始奖励 |
F |
额外加入的 shaping 奖励 |
R' |
智能体实际看到的新奖励 |
例如,在迷宫中,可以根据距离终点是否缩短给予额外分数:
$$F(s_t,a_t,s_{t+1})= d(s_t,\mathrm{goal})-d(s_{t+1},\mathrm{goal})$$
如果机器人更靠近终点,奖励为正;如果远离终点,奖励为负。
这样,即使还没有真正到达终点,智能体也能得到方向提示。
7.1 Reward Shaping 的风险
问题在于,路标也可能改变目的地。
假设迷宫中有一堵墙。最短路线需要先远离终点,再绕过墙壁。如果奖励始终鼓励“每一步都更靠近终点”,智能体可能被困在墙边,不愿意暂时后退。
Reward Shaping 不是免费的。
它可以降低学习难度,也可能改变最优策略。
8. Potential-Based Reward Shaping
有一种经典设计可以在一定条件下避免改变最优策略,称为 Potential-Based Reward Shaping。
定义一个势函数(potential function):
$$\Phi(s)$$
它为每个状态赋予一个“潜在位置”或“启发式进度”。
shaping 项写成:
$$F(s_t,a_t,s_{t+1})= \gamma\Phi(s_{t+1})-\Phi(s_t)$$
新的奖励为:
$$R'(s_t,a_t,s_{t+1})= R(s_t,a_t,s_{t+1})+\gamma\Phi(s_{t+1})-\Phi(s_t)$$
逐项解释:
| 符号 | 含义 |
|---|---|
Φ(s_t) |
当前状态的势能或启发式位置 |
Φ(s_{t+1}) |
下一状态的势能 |
γ |
与原问题一致的折扣因子 |
F |
附加 shaping 奖励 |
R' |
加入 shaping 后的新奖励 |
直觉是:
智能体不是因为停留在某个看似不错的位置反复刷分,而是因为势能发生变化才得到额外奖励。
为什么这种形式特别?
将 shaping 奖励沿轨迹累加:
$$\sum_{t=0}^{T-1} \gamma^t F(s_t,a_t,s_{t+1})$$
代入定义:
$$\sum_{t=0}^{T-1} \gamma^t [ \gamma\Phi(s_{t+1})-\Phi(s_t) ]$$
展开前几项:
-Φ(s₀) + γ Φ(s₁)
-γ Φ(s₁) + γ² Φ(s₂)
-γ² Φ(s₂) + γ³ Φ(s₃)
中间项会成对抵消,最后剩下:
$$-\Phi(s_0)+\gamma^T\Phi(s_T)$$
这种结构称为 telescoping sum,可以理解为“望远镜式抵消”。
在适当条件下,这个额外项不会改变不同策略之间真正的最优排序,只会改变学习过程中的局部信号。
这提醒我们:
好的 Reward Shaping 不是随意多给分,而是尽量在不改变问题本质的前提下,让学习路径更清晰。
9. 奖励设计不是 Loss 设计
奖励函数和损失函数容易被混淆。
它们都可能出现在训练代码中,也都影响模型更新。但它们位于不同层次。
| 概念 | 回答的问题 |
|---|---|
奖励 r_t |
环境如何评价一次状态转移或一条轨迹? |
回报 G_t |
从当前时刻开始,未来奖励累计起来有多少? |
价值 V 或 Q |
在尚未走完未来时,如何估计长期回报? |
损失函数 L |
如何把目标、估计和约束变成一次参数更新? |
奖励属于“目标问题”。
损失属于“更新问题”。
它们相互连接,但不是同一件事。
例如,机器人导航中,终点奖励、碰撞惩罚和时间惩罚属于奖励设计;而用于训练价值网络的 TD Loss 属于损失函数设计。
到了大模型后训练中,这一区分更加重要:
- 人类偏好或规则验证器参与定义奖励;
- Reward Model 估计偏好奖励;
- PPO、DPO 或 GRPO 再决定如何形成更新。
如果不分层,许多概念会搅在一起。
10. 当奖励来自人类偏好
在大模型对齐中,我们很难为“一个回答有多好”写出完全准确的规则。
一种常见办法是让人类比较两个回答:
- 回答
y_w更好; - 回答
y_l较差。
其中,w 代表 winner,l 代表 loser。
我们可以训练一个 Reward Model:
$$r_\phi(x,y)$$
它接收提示词 x 和回答 y,输出一个分数。
常见偏好模型写成:
$$P(y_w\succ y_l\mid x)= \sigma ( r_\phi(x,y_w)-r_\phi(x,y_l))$$
逐项解释如下:
| 符号 | 含义 |
|---|---|
x |
用户提示词 |
y_w |
人类更偏好的回答 |
y_l |
人类较不偏好的回答 |
r_φ(x,y) |
Reward Model 对回答的评分 |
σ |
Sigmoid 函数,将任意实数映射到 0 与 1 之间 |
P(y_w ≻ y_l | x) |
在提示词 x 下,回答 y_w 优于 y_l 的概率 |
如果:
$$r_\phi(x,y_w)-r_\phi(x,y_l)$$
很大,那么模型认为 y_w 更可能胜出。
这使“偏好”变成了可计算信号。
但它没有彻底解决奖励问题。
Reward Model 仍然只是代理。它依赖有限数据,可能学到表面相关性,也可能在策略分布发生变化后失去可靠性。
这一问题会在第 21 章 RLHF 中详细展开。
11. Verifier:可验证奖励为什么重要
并非所有任务都只能依赖模糊偏好。
有些任务存在相对明确的验证方式:
- 数学题答案是否正确;
- 程序是否通过测试;
- 形式证明是否满足检查器;
- 游戏规则是否满足;
- 工具调用结果是否正确。
此时,可以使用 Verifier 产生奖励。
简化写法是:
$$r(\tau) = \begin{cases} 1, & \mathrm{验证通过}\ 0, & \mathrm{验证失败} \end{cases}$$
可验证奖励有明显优势:
- 标准更加明确;
- 自动化程度更高;
- 不必完全依赖人工偏好;
- 可以扩展到大量样本。
但它也有边界。
验证器只检查自己能够检查的部分。如果评价标准过窄,模型仍然可能学会“通过检查器”,而不是完成更宽泛的真实目标。
测试用例不足的代码生成,就是一个熟悉的例子:程序通过了现有测试,不代表它在所有情况下都正确。
Verifier 让奖励更可靠,却没有取消 Goodhart 定律。
12. 边界:奖励问题不可能被一次性解决
奖励设计没有一个适用于所有任务的万能公式。
原因不是工程师不够聪明,而是很多真实意图本身就难以完全形式化。
奖励设计至少要面对四种张力:
- 准确性与可计算性:越接近真实价值,往往越难测量;
- 稀疏性与引导性:奖励越少,越不容易误导,但也越难学习;
- 局部信号与长期目标:局部奖励越密集,越可能把智能体带向局部最优;
- 自动评价与人类判断:自动评价扩展性更好,人类判断覆盖面更广,但成本更高,也可能不一致。
真正成熟的系统通常不会只依赖一种奖励来源。
它可能组合:
- 环境反馈;
- 规则约束;
- 人类偏好;
- Reward Model;
- Verifier;
- 安全约束;
- 人工审核。
问题并没有消失,只是被分配到不同组件中。
13. 回归全景图(Callback)
本章进一步展开了第一个坐标轴:目标。
| 坐标轴 | 本章回答了什么 | 尚未解决什么 |
|---|---|---|
| 目标 | 奖励 R 是真实意图 U 的代理;需要警惕 Goodhart 定律与 Reward Hacking |
如何验证代理在分布变化后仍然可靠 |
| 时间 | 奖励可能稀疏、延迟,Reward Shaping 可以增加局部路标 | 未来奖励如何分配给此前动作 |
| 更新 | 区分了奖励设计与损失设计 | 奖励如何进入具体训练损失 |
| 估计 | Reward Model 可以估计人类偏好,但自身也会犯错 | 如何控制偏好估计误差 |
| 数据 | 偏好数据和验证数据决定了代理奖励能够覆盖哪些行为 | 分布外行为如何评价 |
| 探索 | 更强的优化与探索可能更快暴露奖励漏洞 | 如何在安全范围内发现漏洞并修正奖励 |
本章没有找到完美奖励。它建立了一个更重要的判断:当一个智能体表现异常时,不要只问“算法哪里错了”,还要问“我们究竟奖励了什么”。
14. 本章小结
这一章从一个清洁机器人的刷分行为出发,讨论了奖励与真实意图之间的裂缝。
理想目标是:
$$\max_\pi \mathbf{E}_{\tau \sim \pi} [U(\tau)]$$
实际系统通常优化:
$$\max_\pi E_{\tau \sim \pi} [ \sum_{t=0}^{T-1} \gamma^t R(s_t,a_t,s_{t+1}) ]$$
奖励设计的任务,是让可计算代理 R 尽可能接近真实意图 U。
但代理一旦被强力优化,就可能与真实目标分离:
$$\arg\max_\tau M(\tau)\neq \arg\max_\tau U(\tau)$$
Reward Shaping 可以帮助稀疏奖励任务学习。Potential-Based Reward Shaping 使用:
$$F(s_t,a_t,s_{t+1})= \gamma\Phi(s_{t+1})-\Phi(s_t)$$
在适当条件下,它能够提供路标,同时尽量不改变最优策略。
下一章,我们进入第二个核心问题:
如果奖励发生在未来,未来究竟如何返回现在?
第二部分:未来如何返回现在
第 3 章:Bellman 方程:用未来重新定义现在
1. 还没有走完,怎样判断现在
上一章留下了一个问题。
如果奖励发生在未来,智能体在当前时刻怎样判断一个状态好不好?
想象一个站在岔路口的人。
他还没有真正走完每一条路,却必须现在做出选择。某条路眼前平坦,稍后却通向拥堵;另一条路开始绕行,之后却更快抵达终点。
如果每次判断都必须亲自把所有道路走到尽头,再回来重新选择,学习会非常低效。
强化学习需要一种更聪明的方法:
用对未来的判断,帮助评价现在。
Bellman 方程正是这件事的数学表达。
它不是某个特定算法的技巧,而是强化学习中最重要的递归结构之一。TD、Q-Learning、DQN、Actor-Critic、PPO 中的 Critic,甚至许多大模型后训练方法背后的价值估计,都与它有关。
2. 从回报的递归关系开始
上一章定义了折扣回报:
$$G_t = r_t +\gamma r_{t+1} +\gamma^2r_{t+2} +\gamma^3r_{t+3} +\cdots$$
将第一项单独拿出来:
$$G_t = r_t +\gamma ( r_{t+1} +\gamma r_{t+2} +\gamma^2r_{t+3} +\cdots )$$
括号中的内容是什么?
它恰好是从下一时刻开始计算的回报:
$$G_{t+1} = r_{t+1} +\gamma r_{t+2} +\gamma^2r_{t+3} +\cdots$$
因此:
$$G_t=r_t+\gamma G_{t+1}$$
这是本章第一条关键公式。
它看起来朴素,却包含了 Bellman 思想的核心:
从现在开始的长期回报,等于眼前奖励,加上折扣后的未来回报。
逐项解释:
| 符号 | 含义 |
|---|---|
G_t |
从时刻 t 开始计算的长期回报 |
r_t |
当前一步得到的即时奖励 |
G_{t+1} |
从下一时刻开始计算的长期回报 |
γ |
折扣因子,控制未来回报的权重 |
这条公式把一段很长的未来,折叠成了两部分:
- 眼前看得见的奖励;
- 下一步之后的全部未来。
未来没有消失,只是被压缩了。
3. 状态价值:站在这里,未来大概有多好
实际学习时,智能体通常不知道一条尚未走完的轨迹最终会得到多少回报。
但它可以估计:
在当前状态下,按照某种策略继续走,平均能够获得多少长期回报?
这就是状态价值函数(state-value function)。
对策略 π,状态价值定义为:
$$V^\pi(s) = \mathbf{E}_\pi [ G_t \mid S_t=s ]$$
读作:
在时刻
t处于状态s的条件下,如果之后遵循策略π,未来回报G_t的期望是多少?
逐项解释:
| 符号 | 含义 |
|---|---|
V^π(s) |
在策略 π 下,状态 s 的价值 |
S_t=s |
当前状态随机变量 S_t 取值为 s |
G_t |
从当前时刻开始的累计回报 |
E_π |
在策略 π 与环境随机性下取期望 |
| |
条件符号,读作“在给定……的条件下” |
为什么需要期望?
因为未来通常不唯一。
同一个状态下,策略可能随机选择不同动作;即使动作相同,环境也可能随机转移到不同结果。价值函数不是预测唯一结局,而是在许多可能未来上取平均。
3.1 一个直观例子
假设一个机器人站在仓库入口。
- 有
80%的概率顺利通过走廊,最终获得10分; - 有
20%的概率遇到临时障碍,只获得2分。
那么入口状态的价值可以粗略估计为:
$$V^\pi(s) = 0.8\times10 +0.2\times2 =8.4$$
状态价值不是“必然会拿到多少分”,而是“从这里出发,平均值得期待多少分”。
4. 动作价值:在这里做这件事,未来大概有多好
只知道状态价值还不够。
智能体做决策时,需要比较不同动作。
动作价值函数(action-value function)定义为:
$$Q^\pi(s,a) = \mathbf{E}_\pi [ G_t \mid S_t=s,; A_t=a ]$$
它表示:
在状态
s下先采取动作a,之后继续遵循策略π,未来平均能够获得多少回报?
逐项解释:
| 符号 | 含义 |
|---|---|
Q^π(s,a) |
在策略 π 下,状态 s 中动作 a 的价值 |
S_t=s |
当前处于状态 s |
A_t=a |
当前明确采取动作 a |
G_t |
当前动作之后能够获得的累计回报 |
状态价值与动作价值的差别可以用一句话说明:
V^π(s)问:站在这里,未来总体怎么样?Q^π(s,a)问:站在这里,如果先做这件事,未来怎么样?
如果策略是随机策略,那么状态价值可以看作动作价值的加权平均:
$$V^\pi(s)= \sum_a \pi(a\mid s)Q^\pi(s,a)$$
这里:
| 符号 | 含义 |
|---|---|
Σ_a |
对所有可能动作求和 |
π(a|s) |
在状态 s 下选择动作 a 的概率 |
Q^π(s,a) |
采取动作 a 后的长期价值 |
如果某个动作出现概率更高,它对状态价值的影响就更大。
5. Bellman 期望方程:未来价值返回现在
现在将两条定义连接起来。
我们已经知道:
$$G_t=r_t+\gamma G_{t+1}$$
状态价值定义为:
$$V^\pi(s) = \mathbf{E}_\pi [ G_t \mid S_t=s ]$$
将递归形式代入:
$$V^\pi(s) = E_\pi [ r_t + \gamma G_{t+1} \mid S_t = s ]$$
由于:
$$E_\pi [ G_{t+1} \mid S_{t+1} = s' ] = V^\pi(s')$$
可以得到:
$$V^\pi(s) = E_{a \sim \pi,, s' \sim P} [ r + \gamma V^\pi(s') \mid s ]$$
这就是 Bellman 期望方程的一种写法。
它表达:
当前状态的价值,等于当前可能得到的奖励,加上折扣后的下一状态价值,再对所有可能动作和环境转移取平均。
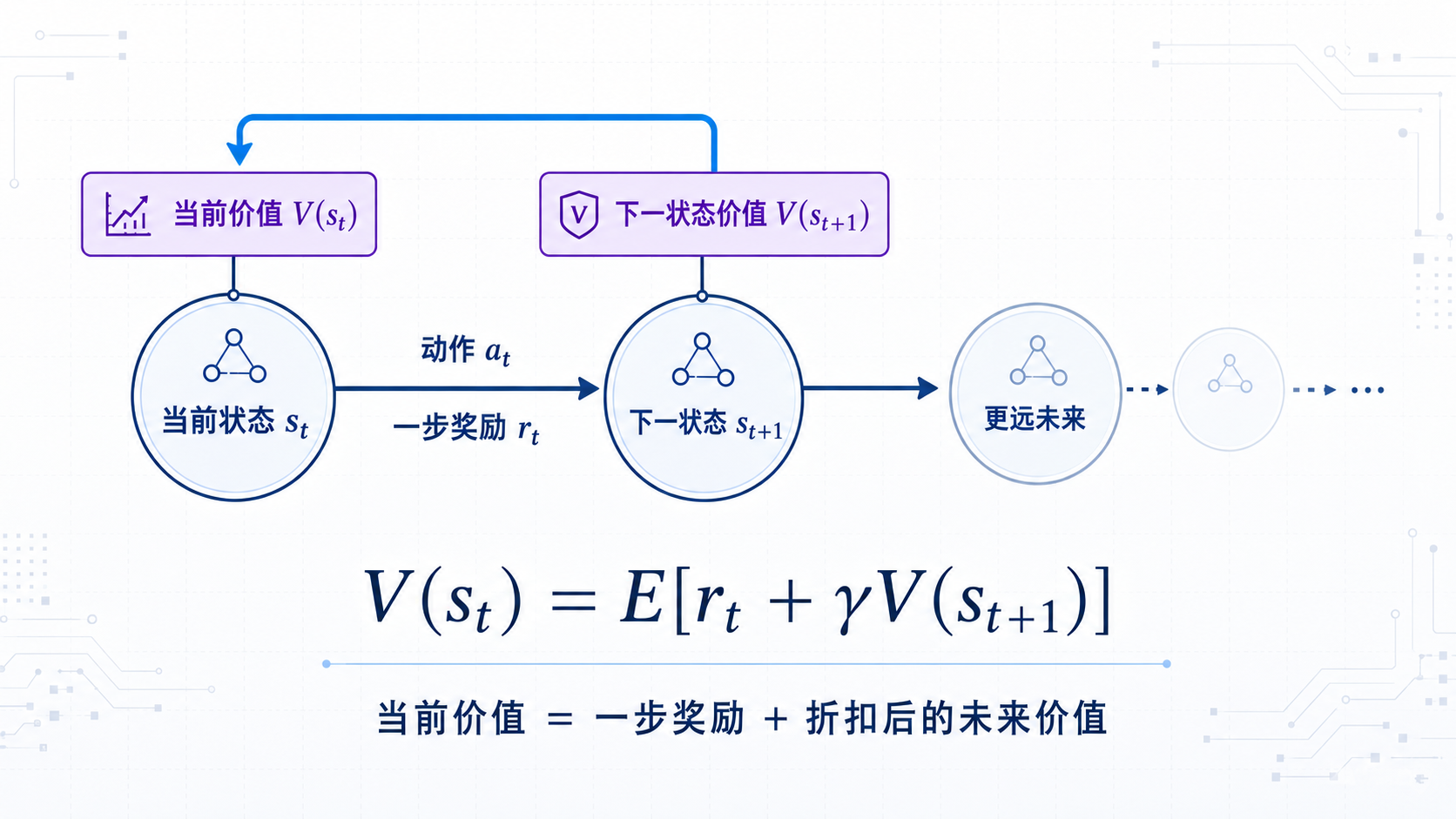
图 3-1:Bellman 方程的递归结构
5.1 将期望完全展开
如果希望看得更具体,可以将期望展开为求和:
$$V^\pi(s)= \sum_a \pi(a\mid s)\sum_{s',r} p(s',r\mid s,a)[ r+\gamma V^\pi(s') ]$$
逐项解释:
| 符号 | 含义 |
|---|---|
Σ_a |
枚举状态 s 下所有可能动作 |
π(a|s) |
策略选择动作 a 的概率 |
Σ_{s',r} |
枚举所有可能的下一状态与奖励 |
p(s',r|s,a) |
在状态 s 下执行动作 a 后,得到奖励 r 并进入状态 s' 的概率 |
r+γV^π(s') |
当前奖励加上折扣后的下一状态价值 |
这条公式可以从左到右读:
- 站在状态
s; - 根据策略选择动作
a; - 环境可能产生不同奖励
r和下一状态s'; - 每一种可能未来都有自己的概率;
- 对所有可能未来取加权平均。
6. 手算一次:从终点倒推起点
考虑一个极简任务:
s_0 → s_1 → terminal
在状态 s_1,智能体只有一个动作。执行后到达终点,奖励为 10。
因此:
$$V^\pi(s_1) = 10+\gamma\times0 =10$$
为什么终点价值是 0?
因为任务已经结束,后面不再有奖励。
现在回到状态 s_0。从 s_0 到 s_1 的即时奖励为 1。假设:
$$\gamma=0.9$$
那么:
$$\begin{aligned} V^\pi(s_0)&= 1+0.9V^\pi(s_1)\ &= 1+0.9\times10\ &= 10 \end{aligned}$$
这个过程很像从终点向起点倒推。
终点告诉 s_1 自己有多好;s_1 的价值再返回 s_0,帮助我们判断更早的状态。
未来就这样进入了现在。
6.1 加入随机性
假设从 s_0 出发,有两种可能:
80%概率进入s_1,即时奖励为1;20%概率遇到故障并终止,即时奖励为-2。
那么:
$$\begin{aligned} V^\pi(s_0)&= 0.8 [ 1+0.9V^\pi(s_1) ] +0.2 [ -2+0.9\times0 ]\ &= 0.8\times10 -0.4\ &= 7.6 \end{aligned}$$
价值函数没有假装世界确定不变。
它把不同未来按概率加权,得到平均判断。
7. 动作价值的 Bellman 方程
动作价值也具有递归结构。
在状态 s 下先采取动作 a,得到奖励 r,进入下一状态 s'。之后,策略继续选择后续动作 a'。
因此:
$$Q^\pi(s,a)= \mathbf{E} [ r+\gamma Q^\pi(s',a') ]$$
其中:
$$a' \sim \pi(\cdot\mid s')$$
将期望展开:
$$Q^\pi(s,a)= \sum_{s',r} p(s',r\mid s,a)[ r +\gamma \sum_{a'} \pi(a'\mid s')Q^\pi(s',a') ]$$
这条公式从左到右表达:
- 当前明确采取动作
a; - 环境给出奖励
r并进入状态s'; - 后续动作
a'仍然由策略π决定; - 当前动作价值等于当前奖励加上后续动作价值的平均。
8. 从“评价一个策略”到“寻找最优策略”
到目前为止,我们一直在讨论:
$$V^\pi(s)$$
和:
$$Q^\pi(s,a)$$
它们都带有上标 π,表示:
如果以后继续遵循策略
π,当前状态或动作有多好?
但强化学习通常不只想评价一个已有策略,还希望找到更好的策略。
因此,定义最优状态价值:
$$V^*(s)= \max_\pi V^\pi(s)$$
它表示:
从状态
s出发,在所有可能策略中,能够达到的最高期望回报是多少?
类似地,最优动作价值定义为:
$$Q^*(s,a)= \max_\pi Q^\pi(s,a)$$
它表示:
在状态
s下先做动作a,随后采用最佳策略,最多能够获得多少期望回报?
9. Bellman 最优方程
如果已经知道最优动作价值:
$$Q^*(s,a)$$
那么在下一状态 s',智能体应该选择价值最高的动作:
$$\max_{a'}Q^*(s',a')$$
于是得到 Bellman 最优方程:
$$Q^(s,a)= \mathbf{E} [ r +\gamma \max_{a'} Q^(s',a') ]$$
逐项解释:
| 符号 | 含义 |
|---|---|
Q^*(s,a) |
当前状态下采取动作 a 的最优长期价值 |
r |
当前动作带来的即时奖励 |
s' |
下一状态 |
a' |
下一状态中可选择的动作 |
max_{a'} Q^*(s',a') |
下一状态中最有价值的动作 |
γ |
未来价值的折扣 |
对于状态价值:
$$V^(s)= \max_a \mathbf{E} [ r+\gamma V^(s') \mid s,a ]$$
这两条公式的直觉一致:
当前最优价值,等于选择一个动作后得到的即时奖励,加上下一状态能够实现的最优未来价值。
10. 手算一次:为什么最优动作可能不是即时奖励最高的动作
假设在状态 s_0 有两个动作:
动作 A:立刻得分
- 当前奖励:
5 - 执行后终止
因此:
$$Q^*(s_0,A)=5$$
动作 B:先进入新状态
- 当前奖励:
1 - 进入状态
s_1 - 已知:
$$V^*(s_1)=10$$
假设:
$$\gamma=0.9$$
那么:
$$Q^*(s_0,B) = 1 + 0.9 V^*(s_1) = 1 + 0.9 \times 10 = 10$$
虽然:
$$5>1$$
但:
$$Q^\ast(s_0,B) \gt Q^\ast(s_0,A)$$
因此,最优动作是 B。
Bellman 方程让智能体不再只看眼前奖励,而是把未来价值纳入当前判断。
11. 固定点:递归不是无限兜圈
看到 Bellman 方程,读者可能会产生一个疑问:
如果
V(s)依赖V(s'),而V(s')又依赖更后面的价值,这不是永远算不完吗?
关键在于,Bellman 方程定义了一个固定点(fixed point)。
我们可以定义一个 Bellman 算子:
$$(\mathcal{T}^\pi V)(s)= \mathbf{E}_{a \sim \pi,;s'\sim P} [ r+\gamma V(s') \mid s ]$$
这个算子接收一个价值函数 V,输出一个新的价值函数。
真正的策略价值满足:
$$V^\pi = T V^\pi$$
这表示:
将真实价值函数放进 Bellman 算子,输出仍然是它自己。
这就是固定点。
11.1 从错误猜测开始也可以
假设一开始完全不知道价值,可以初始化:
$$V_0(s)=0$$
然后反复更新:
$$V_{k+1} = \mathcal{T}^\pi V_k$$
这里:
| 符号 | 含义 |
|---|---|
V_k |
第 k 轮价值估计 |
T^π |
按照策略 π 进行一次 Bellman 更新 |
V_{k+1} |
更新后的新价值估计 |
如果条件合适,反复应用 Bellman 更新,价值估计会逐渐接近真实价值。
11.2 折扣为什么帮助收敛
当 0≤γ<1 时,Bellman 算子具有压缩性质。直观写法是:
$$\lVert T^{\pi} V - T^{\pi} W \rVert_{\infty} \leq \gamma \lVert V - W \rVert_{\infty}$$
逐项解释:
| 符号 | 含义 |
|---|---|
V、W |
两个不同的价值估计 |
T^πV、T^πW |
分别进行一次 Bellman 更新后的结果 |
||·||_∞ |
最大范数,表示所有状态中最大的估计差异 |
γ |
折扣因子 |
这条不等式表达:
更新之后,两个价值估计之间的最大差距,最多缩小到原来的
γ倍。
当:
$$\gamma<1$$
误差会逐渐收缩。
这也是折扣因子另一层重要作用:它不仅控制时间视野,也帮助递归关系稳定下来。
本书不会在这里展开完整证明。此时最重要的是建立固定点直觉:
Bellman 方程不是让价值在无限递归中打转,而是提供一个可以不断逼近的自洽目标。
12. Dynamic Programming:知道环境模型时怎样求价值
如果我们知道完整环境模型:
$$p(s',r\mid s,a)$$
就可以直接使用 Bellman 方程反复更新价值。
这类方法属于动态规划(Dynamic Programming,DP)。
12.1 Policy Evaluation
给定策略 π,反复计算:
$$V_{k+1}(s)= \sum_a \pi(a\mid s)\sum_{s',r} p(s',r\mid s,a)[ r+\gamma V_k(s') ]$$
直到价值基本稳定。
这个过程称为策略评价(Policy Evaluation)。
它回答:
如果继续采用当前策略,每个状态大概有多好?
12.2 Policy Improvement
得到动作价值后,可以在每个状态选择更好的动作:
$$\pi'(s)= \arg\max_a Q^\pi(s,a)$$
这称为策略改进(Policy Improvement)。
它回答:
既然已经知道动作价值,是否可以少做一些差动作,多做一些好动作?
12.3 Policy Iteration
将两步交替进行:
评价当前策略 → 根据价值改进策略 → 再评价新策略 → 再改进
这称为策略迭代(Policy Iteration)。
12.4 Value Iteration
也可以直接反复使用 Bellman 最优更新:
$$V_{k+1}(s)= \max_a \sum_{s',r} p(s',r\mid s,a)[ r+\gamma V_k(s') ]$$
这称为价值迭代(Value Iteration)。
动态规划向我们展示了 Bellman 方程的力量。
但它也依赖一个强条件:完整环境模型必须已知。
13. 现实中的困难:我们通常拿不到完整模型
在现实问题中,我们通常不知道:
$$p(s',r\mid s,a)$$
机器人并不知道每个动作会以多大概率导致每种姿态;推荐系统并不知道每位用户看到某条内容后会做什么;语言模型也无法枚举每个 Token 之后所有可能序列及其评价。
我们拿到的通常只是一次次采样:
$$(s_t,a_t,r_t,s_{t+1})$$
也就是说,我们没有完整地图,只有走过道路后留下的脚印。
这会把问题推向下一章:
当完整未来不可见,我们如何把有限反馈分配给此前动作?
这就是信用分配问题。
再下一章,我们会进一步追问:
能否不用等待整条轨迹结束,就用下一状态的价值估计更新当前价值?
这就是自举,也是 TD Learning 的核心。
14. Bellman 方程的边界
Bellman 方程非常重要,但不能被神化。
14.1 它依赖状态表达
Bellman 递归通常建立在 Markov 假设上:
当前状态已经包含了预测未来所需的有效信息。
如果状态遗漏了重要历史,价值估计就可能不准确。
例如,在部分可观测环境中,机器人看到的当前画面未必足以判断真实位置;在多轮对话中,截断上下文可能丢失关键信息。
此时,需要更丰富的状态表示、记忆机制或 POMDP 框架。
14.2 它没有自动解决奖励问题
Bellman 方程会忠实传播奖励。
如果奖励设计错误,它也会忠实传播错误目标。
递归关系解决的是“未来如何返回现在”,不是“真正应该追求什么”。
14.3 它没有自动解决估计误差
当完整模型未知,我们会使用采样和函数逼近估计 Bellman 目标。
一旦估计有误,误差也可能沿递归关系传播。
Bellman 方程既提供了学习路径,也打开了误差传播的通道。
15. 回归全景图(Callback)
| 坐标轴 | Bellman 方程如何进入全景图 | 尚未解决什么 |
|---|---|---|
| 目标 | 将长期回报保留在递归关系中 | 奖励是否正确表达真实意图 |
| 时间 | 用 当前奖励 + 折扣后的未来价值 让未来返回现在 |
延迟奖励如何在有限样本中可靠传播 |
| 更新 | 提供可以反复迭代的自洽关系与固定点 | 没有完整模型时如何形成可训练更新 |
| 估计 | 定义 V^π、Q^π、V*、Q* |
函数逼近和采样会带来什么误差 |
| 数据 | 动态规划假设能够访问完整环境模型 | 现实中通常只能观察采样转移 |
| 探索 | Bellman 方程本身不负责探索 | 智能体如何发现未访问状态 |
Bellman 方程没有神奇地解决强化学习。它完成了一件更基础的事:将一个跨越整条轨迹的长期目标,折叠成可以逐步向前传递的递归关系。
16. 本章小结
本章从回报的递归关系开始:
$$G_t=r_t+\gamma G_{t+1}$$
定义了状态价值:
$$V^\pi(s) = \mathbf{E}_\pi [ G_t \mid S_t=s ]$$
定义了动作价值:
$$Q^\pi(s,a) = \mathbf{E}_\pi [ G_t \mid S_t=s,; A_t=a ]$$
并得到 Bellman 期望方程:
$$V^\pi(s)= \mathbf{E} [ r+\gamma V^\pi(s') ]$$
以及 Bellman 最优方程:
$$Q^(s,a)= \mathbf{E} [ r +\gamma \max_{a'} Q^(s',a') ]$$
这些公式建立了强化学习最重要的递归结构:
当前价值来自当前奖励,也来自对未来的判断。
下一章继续追问:
当最终结果姗姗来迟时,究竟应该把功劳和责任分给哪些动作?
第 4 章:信用分配:谁应当为结局负责
1. 赢下一盘棋,究竟是哪一步走对了
一盘棋结束了。
智能体赢得比赛,得到奖励:
$$+1$$
此前几十步落子,大多没有即时奖励:
$$0,0,0,\ldots,0,+1$$
现在的问题是:最后的胜利应该归功于哪一步?
也许是最后一步将军。也许是中盘的一次交换。也许是更早之前看似平淡的一步,为后续进攻保留了空间。
如果所有动作都得到同样赞扬,智能体很难真正学会什么。如果只奖励最后一步,又会忽略通往胜利的漫长路径。
这个问题称为信用分配(credit assignment)。
信用分配中的“信用”不只是表扬,也包括责任。一次失败发生后,哪些动作应该被减少?哪些动作虽然出现在失败轨迹中,却其实是正确选择?
这不仅是棋类问题。
- 机器人摔倒前可能已经连续失衡了十几步;
- 推荐系统造成用户流失,原因可能来自更早的一系列内容展示;
- 语言模型最终答错数学题,错误可能出现在中间某一步推理;
- 一个长回答被人类判为低质量,问题可能来自事实错误、结构混乱或语气不当。
强化学习真正困难的部分,往往不是计算梯度,而是回答:
迟到的结果,究竟应该如何分配给此前发生的动作?
2. 三种让学习变难的反馈
信用分配之所以困难,通常因为反馈同时具有三种特点。
2.1 延迟
动作发生后,结果可能很久才出现。
例如,下棋时只有终局胜负;语言模型回答完成后,评价器才给出总分。
如果动作 a_t 的后果在 t+n 时刻才显现,智能体必须跨越时间建立联系。
2.2 稀疏
许多时间步没有奖励。
一条轨迹可能是:
$$(0,0,0,0,0,1)$$
从局部看,前五步没有任何差别。但没有前五步,最后的奖励也不会出现。
2.3 噪声
即使采取同一个动作,结果也可能不同。
环境随机性、其他智能体、人类偏好差异、采样温度和评价器误差,都会使反馈带有噪声。
因此,一次成功不一定证明所有动作都好;一次失败也不一定证明所有动作都坏。
3. Monte Carlo:等结局出现,再回头结算
最直接的办法是等待轨迹结束。
假设一条轨迹为:
$$\tau=(s_0,a_0,r_0,s_1,a_1,r_1,\ldots,s_T)$$
从时刻 t 开始的回报为:
$$G_t = \sum_{k=0}^{T-t-1} \gamma^k r_{t+k}$$
在 Monte Carlo 方法中,我们等到整条轨迹完成,再用实际观察到的 G_t 更新此前状态或动作的价值估计。
状态价值更新可以写成:
$$V(s_t)\leftarrow V(s_t)+\alpha [ G_t-V(s_t) ]$$
动作价值更新可以写成:
$$Q(s_t,a_t)\leftarrow Q(s_t,a_t)+\alpha [ G_t-Q(s_t,a_t) ]$$
逐项解释:
| 符号 | 含义 |
|---|---|
V(s_t) |
当前对状态 s_t 的价值估计 |
Q(s_t,a_t) |
当前对动作 (s_t,a_t) 的价值估计 |
G_t |
轨迹结束后计算出的实际回报 |
α |
学习率,控制这次经验对旧估计的影响 |
← |
用右侧结果更新左侧数值 |
括号中的:
$$G_t-V(s_t)$$
表示真实观察回报与旧价值估计之间的差距。
如果实际结果比预期好,价值上调;如果实际结果比预期差,价值下调。
3.1 手算一次
假设一条三步轨迹的奖励为:
$$(r_0,r_1,r_2)=(0,0,10)$$
并且:
$$\gamma=0.9$$
那么:
$$G_2=10$$
$$G_1=0+0.9\times10=9$$
$$G_0=0+0.9\times0+0.9^2\times10=8.1$$
虽然前两步即时奖励都是 0,但 Monte Carlo 回报仍然把终点奖励向前传播:
| 时刻 | 即时奖励 | 从该时刻开始的回报 |
|---|---|---|
t=0 |
0 |
8.1 |
t=1 |
0 |
9 |
t=2 |
10 |
10 |
这是一种最朴素的信用分配。
越靠近终点,奖励折扣越少;越早的动作,得到的信用越弱。
4. Monte Carlo 的优点与代价
Monte Carlo 方法有一个重要优点:
它使用真正观察到的轨迹回报,不需要猜测尚未发生的未来。
但它也有明显代价。
4.1 必须等待终局
如果轨迹很长,就必须等很久。
在下棋中,必须等比赛结束;在语言模型中,通常必须等回答生成完成;在持续运行的系统中,轨迹甚至可能没有天然终点。
4.2 方差可能很大
假设从同一个状态出发,环境有较强随机性。不同轨迹可能得到:
$$G_t^{(1)}=20$$
$$G_t^{(2)}=-5$$
$$G_t^{(3)}=8$$
同一个状态对应的回报波动很大。
Monte Carlo 使用完整轨迹,轨迹中所有随机性都会进入估计结果。它通常偏差较小,但方差较大。
4.3 一次结局会影响很多动作
如果一条长轨迹最后失败,前面所有动作都可能被负回报影响。
但其中一些动作未必错误。它们只是和后面的错误出现在同一条轨迹中。
Monte Carlo 能够传播信用,却不等于完成了精细归因。
5. 信用分配不等于因果解释
这一点值得单独强调。
如果某个动作出现在高回报轨迹中,强化学习可能提高它的价值估计。但这并不自动证明:
这个动作是高回报的真正原因。
在复杂环境中,动作、状态和结果之间可能存在混杂因素。
例如:
- 棋局中,一步进攻出现在胜利轨迹里,但真正关键的是更早的布局;
- 推荐系统中,用户点击某类内容,可能因为内容质量,也可能因为展示位置;
- 语言模型回答获得高分,可能因为事实正确,也可能因为 Reward Model 偏好某种表面风格。
经典 RL 的信用分配主要回答:
哪些动作应该在学习中得到更多或更少权重?
它不一定提供完整的因果解释。
这是理解 Reward Hacking、偏好模型偏差和分布外失效的重要前提。
6. Baseline:不要只问“得了多少分”
假设一个动作最终获得回报:
$$G_t=8$$
这是否说明它很好?
不一定。
如果当前状态下,其他动作平均只能获得 2 分,那么 8 分确实很好。如果其他动作平均能够获得 12 分,那么 8 分反而较差。
因此,评价动作时,仅看绝对回报并不够。还需要比较:
这个动作比当前状态下的平均水平好多少?
一种常见写法是减去 baseline:
$$G_t-b(s_t)$$
其中:
| 符号 | 含义 |
|---|---|
G_t |
当前动作之后观察到的回报 |
b(s_t) |
当前状态下的基准水平 |
G_t-b(s_t) |
相对于基准的超额表现 |
最常见的 baseline 是状态价值:
$$b(s_t)=V(s_t)$$
于是:
$$G_t-V(s_t)$$
表示:
实际结果比站在当前状态下通常能够期待的结果好多少?
这种“相对评价”会在策略梯度、Actor-Critic、GAE、PPO 和 GRPO 中反复出现。
7. Advantage:一个动作比平均水平好多少
将“相对好坏”写成函数,就得到 Advantage Function,通常翻译为优势函数。
定义:
$$A^\pi(s,a) = Q^\pi(s,a) - V^\pi(s)$$
逐项解释:
| 符号 | 含义 |
|---|---|
Q^π(s,a) |
在状态 s 下采取动作 a 的长期价值 |
V^π(s) |
处于状态 s 时,按照策略 π 行动的平均长期价值 |
A^π(s,a) |
动作 a 相对当前平均水平的优势 |
如果:
$$A^\pi(s,a)>0$$
说明动作 a 比平均水平更好。
如果:
$$A^\pi(s,a)<0$$
说明动作 a 比平均水平更差。
如果:
$$A^\pi(s,a)=0$$
说明它大致符合当前策略的平均水平。
7.1 手算一次
假设在状态 s 下:
$$V^\pi(s)=5$$
两个动作的价值分别为:
$$Q^\pi(s,a_1)=8$$
$$Q^\pi(s,a_2)=3$$
那么:
$$A^\pi(s,a_1)=8-5=3$$
$$A^\pi(s,a_2)=3-5=-2$$
动作 a_1 应该被鼓励,动作 a_2 应该被抑制。
优势函数让信用分配更加精细:
不只是问结果好不好,而是问这个动作是否比当前状态下通常会做的事情更好。
8. Critic:一个学习出来的信用分配器
在 Actor-Critic 架构中:
- Actor 负责选择动作;
- Critic 负责评价状态或动作。
Critic 常常估计:
$$V^\pi(s)$$
或:
$$Q^\pi(s,a)$$
它的作用不是替代最终奖励,而是帮助智能体更快判断:
当前这一步究竟比平均水平好多少?
从信用分配角度看,Critic 可以理解为一个学习出来的中间评价器。
终点奖励可能很迟,但 Critic 尝试在每一个状态给出估计。Actor 不必只等最终结局,而可以根据这些中间判断调整策略。
这会提高效率,也会引入新的风险:
如果 Critic 判断错误,Actor 会被错误信用引导。
第 5 章将讨论 Critic 为什么能够提前评价,以及自举如何让估计更高效,也更危险。
9. 长序列中的信用分配
信用分配在短轨迹中已经不简单,在长序列中更难。
9.1 机器人控制
机器人摔倒可能不是最后一步突然出错,而是更早之前重心逐渐偏移。
如果只处罚摔倒前的最后一个动作,学习信号可能过于局部。
9.2 推荐系统
用户离开平台,原因可能不是最后一条内容,而是一系列低质量推荐累积造成的疲劳。
如果只把责任归给最后一次展示,系统会误判。
9.3 语言模型
语言模型生成一个回答:
$$y=(y_1,y_2,\ldots,y_T)$$
其中,每个 y_t 是一个 Token。
如果评价器只在回答结束后给出一个总分:
$$R(y)$$
那么中间每个 Token 如何获得信用?
例如,一个数学推理回答最终错误:
- 可能是第一个公式抄错;
- 可能是中间一步符号变化错误;
- 可能是最终计算错误;
- 也可能是推理正确,但输出格式没有通过验证器。
序列级奖励无法自动告诉我们错误发生在哪里。
10. Outcome Reward 与 Process Reward
在长序列任务中,可以区分两种奖励。
10.1 Outcome Reward
Outcome Reward 只评价最终结果。
例如:
$$R_{\mathrm{outcome}}(y) = \begin{cases} 1, & \mathrm{最终答案正确}\ 0, & \mathrm{最终答案错误} \end{cases}$$
优点:
- 标准明确;
- 自动验证相对容易;
- 不需要标注每一步。
缺点:
- 奖励稀疏;
- 很难判断中间步骤;
- 错误信用可能传播给整段序列。
10.2 Process Reward
Process Reward 尝试评价中间步骤。
假设一个推理过程包含:
$$(z_1,z_2,\ldots,z_K)$$
可以为每一步给出奖励:
$$r_k^{\mathrm{process}}$$
总奖励可以写成:
$$R_{\mathrm{process}} = \sum_{k=1}^{K} w_k r_k^{\mathrm{process}}$$
其中:
| 符号 | 含义 |
|---|---|
z_k |
第 k 个中间推理步骤 |
r_k^{process} |
对该步骤的评价 |
w_k |
不同步骤的权重 |
R_process |
聚合后的过程奖励 |
优点:
- 信号更密集;
- 更容易定位错误;
- 可能提高长推理任务的训练效率。
缺点:
- 标注成本更高;
- 中间步骤未必容易客观评价;
- 错误过程规范可能抑制有效但非典型的推理路径。
Outcome Reward 与 Process Reward 不是谁完全取代谁,而是稀疏但可靠的结果评价,与密集但更难设计的过程评价之间的取舍。
11. 折扣如何影响信用传播
回报定义为:
$$G_t = \sum_{k=0}^{T-t-1} \gamma^k r_{t+k}$$
如果奖励发生在很远的未来,它对早期动作的影响会乘上:
$$\gamma^k$$
假设:
$$\gamma=0.9$$
十步之后的奖励权重是:
$$0.9^{10}\approx0.349$$
一百步之后:
$$0.9^{100}\approx0.000027$$
这意味着,即使终点奖励很大,传播到很早动作时也可能已经非常微弱。
较大的 γ 能够保留更长时间的信用,但也会引入更长的估计链条和更高方差。
信用分配与估计稳定性从来不是彼此独立的问题。
12. 边界:完美信用分配通常不可得
我们很容易希望算法能够准确回答:
最终结果中,每一步动作究竟贡献了多少?
但现实中,这个问题通常没有简单答案。
原因包括:
- 动作之间存在组合效应;
- 同一个动作在不同上下文中作用不同;
- 环境包含随机性;
- 状态表示可能遗漏信息;
- 奖励本身可能只是代理;
- 评价器也可能犯错。
强化学习中的信用分配通常不是恢复唯一真实答案,而是构造足够有用的学习信号。
这个信号需要在准确性、成本、方差与可计算性之间取舍。
下一章的自举,正是这种取舍的代表:
不再等待完整结局,而是用自己对下一步的估计,提前更新当前判断。
13. 回归全景图(Callback)
| 坐标轴 | 信用分配如何进入全景图 | 尚未解决什么 |
|---|---|---|
| 目标 | 回报仍然由奖励定义 | 奖励是否代表真实意图 |
| 时间 | Monte Carlo 将终点回报向前传播;Advantage 评价动作相对好坏 | 如何更快地传播信用 |
| 更新 | 可以使用 V←V+α(G-V) 或 Q←Q+α(G-Q) 更新价值 |
如何不等待整条轨迹结束 |
| 估计 | Baseline、V、Q 和 Advantage 提供中间评价 |
估计错误会如何影响策略 |
| 数据 | 完整轨迹提供信用分配所需样本 | 长轨迹样本成本高,随机性大 |
| 探索 | 只有被探索到的轨迹才能获得信用 | 未访问动作仍然难以评价 |
信用分配没有给出完美因果解释。它的任务是将迟到、稀疏、带噪声的结果,转换成此前动作能够使用的学习信号。
14. 本章小结
本章讨论了强化学习最核心的困难之一:
最终结果出现后,谁应当获得信用,谁应当承担责任?
Monte Carlo 方法等待轨迹结束,再计算:
$$G_t = \sum_{k=0}^{T-t-1} \gamma^k r_{t+k}$$
并用实际回报更新价值:
$$V(s_t)\leftarrow V(s_t)+\alpha [ G_t-V(s_t) ]$$
优势函数进一步比较动作相对于平均水平的好坏:
$$A^\pi(s,a)= Q\pi(s,a)-V\pi(s)$$
但等待终局代价很高,轨迹随机性也会带来高方差。
下一章继续追问:
能否不等未来完全发生,就用对未来的估计更新现在?
第 5 章:自举:用尚未完成的预测更新预测
1. 如果每次都等待结局
上一章讨论了 Monte Carlo 方法。
它的做法很直接:
- 让智能体完成一条轨迹;
- 等待最终结果出现;
- 计算每个时间步之后的真实回报;
- 用这些回报更新此前状态或动作的价值。
这种方法很诚实。
它不猜测未来,而是等未来真正发生。
但如果一盘棋很长,如果机器人任务持续运行,如果语言模型需要生成几千个 Token,或者环境交互成本极高,等待完整结局就会显得缓慢。
能否提前学习?
能否只走一步,就开始更新?
Temporal Difference Learning 给出的答案是:
可以。虽然完整未来还没有发生,但我们可以暂时相信自己对下一步的估计。
这种做法称为自举(bootstrapping)。
2. 自举到底是什么意思
“自举”听起来有些抽象。它的核心含义其实很简单:
用一个尚未完全验证的预测,去更新另一个预测。
在 Bellman 方程中:
$$V^\pi(s_t)= \mathbf{E} [ r_t+\gamma V^\pi(s_{t+1}) ]$$
当前状态价值取决于:
- 已经观察到的即时奖励
r_t; - 下一状态价值
V^π(s_{t+1})。
问题在于,训练过程中我们并不知道真实的:
$$V^\pi(s_{t+1})$$
我们只有一个估计:
$$\hat{V}(s_{t+1})$$
于是,TD 方法用:
$$r_t+\gamma\hat{V}(s_{t+1})$$
作为当前价值的学习目标。
未来还没有完全发生,但对未来的预测已经参与训练。
这就是自举。
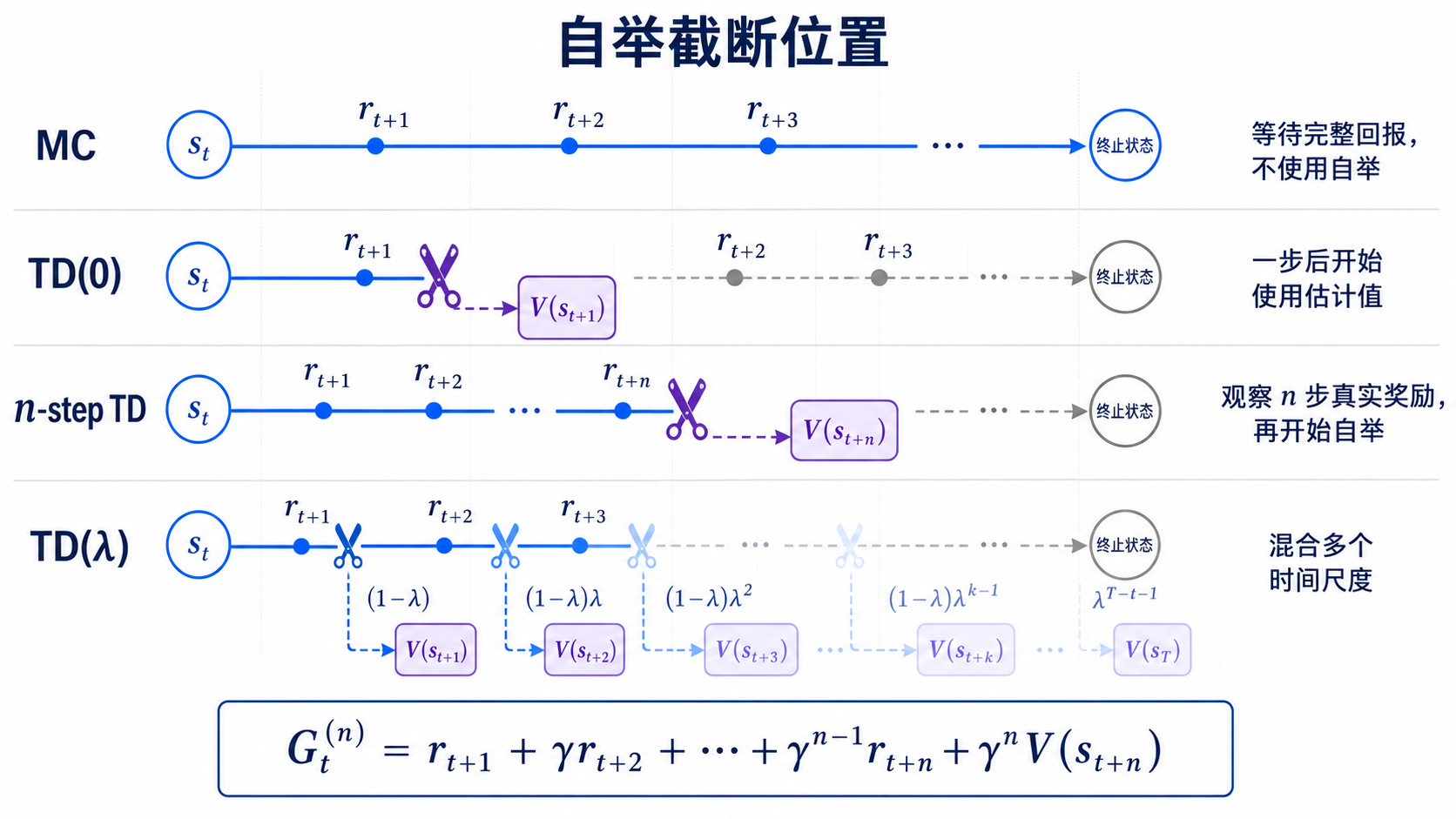
图 5-1:自举截断位置
3. TD Target:提前结算未来
最基本的一步 TD 目标写成:
$$y_t = r_t +\gamma V(s_{t+1})$$
这个量称为 TD Target。
逐项解释:
| 符号 | 含义 |
|---|---|
y_t |
用于更新当前价值的目标 |
r_t |
当前一步已经观察到的真实奖励 |
V(s_{t+1}) |
对下一状态未来收益的估计 |
γ |
折扣因子 |
TD Target 由两部分组成:
已经发生的现实 + 对尚未发生未来的估计
这与 Monte Carlo 不同。
Monte Carlo 使用完整回报:
$$G_t = r_t +\gamma r_{t+1} +\gamma^2r_{t+2} +\cdots$$
TD(0) 只观察一步,然后截断真实轨迹,用价值估计接上未来:
$$G_t^{(1)} = r_t+\gamma V(s_{t+1})$$
上标 (1) 表示只使用一步真实奖励。
4. TD Error:现实与预测相差多少
有了 TD Target,就可以比较:
- 原来对当前状态的估计;
- 观察一步之后得到的新目标。
TD Error 定义为:
$$\delta_t = r_t +\gamma V(s_{t+1})-V(s_t)$$
也可以写成:
$$\delta_t=y_t-V(s_t)$$
其中:
| 符号 | 含义 |
|---|---|
δ_t |
时刻 t 的 TD Error |
y_t |
新的 TD Target |
V(s_t) |
更新前对当前状态的价值估计 |
如果:
$$\delta_t>0$$
说明新观察结果比原先预期更好,当前状态价值应该上调。
如果:
$$\delta_t<0$$
说明新观察结果比原先预期更差,当前状态价值应该下调。
如果:
$$\delta_t=0$$
说明当前估计与一步之后的新证据已经一致。
5. TD 更新:只走一步,也能学习
表格型 TD(0) 的状态价值更新写成:
$$V(s_t)\leftarrow V(s_t) +\alpha \delta_t$$
代入 TD Error:
$$V(s_t)\leftarrow V(s_t)+\alpha [ r_t +\gamma V(s_{t+1})-V(s_t) ]$$
这里:
| 符号 | 含义 |
|---|---|
α |
学习率 |
δ_t |
新证据与旧估计之间的差距 |
V(s_t) |
被更新的当前状态价值 |
这条公式可以理解为:
保留旧判断,但向新的 TD Target 靠近一点。
将式子重新整理:
$$V(s_t)\leftarrow (1-\alpha)V(s_t)+\alpha [ r_t+\gamma V(s_{t+1}) ]$$
现在更容易看见:
(1-α)V(s_t)保留旧估计;α[r_t+γV(s_{t+1})]吸收新目标。
学习率 α 决定了智能体有多愿意相信这次新经验。
6. 手算一次:一步之后就开始学习
考虑一条轨迹:
s_0 → s_1 → terminal
设:
$$\gamma=0.9$$
当前价值估计为:
$$V(s_0)=2$$
$$V(s_1)=5$$
机器人从 s_0 走到 s_1,得到奖励:
$$r_0=1$$
那么 TD Target 为:
$$\begin{aligned} y_0 &= r_0+\gamma V(s_1)\ &= 1+0.9\times5\ &= 5.5 \end{aligned}$$
TD Error 为:
$$\begin{aligned} \delta_0 &= y_0-V(s_0)\ &= 5.5-2\ &= 3.5 \end{aligned}$$
假设学习率:
$$\alpha=0.1$$
更新后:
$$\begin{aligned} V(s_0) &\leftarrow 2+0.1\times3.5\ &= 2.35 \end{aligned}$$
注意,此时轨迹还没有真正结束。
智能体并不知道从 s_1 出发最终一定能得到多少奖励。它只是暂时相信:
$$V(s_1)=5$$
并据此上调:
$$V(s_0)$$
这就是自举的效率来源,也是风险来源。
7. Monte Carlo 与 TD 的根本区别
Monte Carlo 与 TD 都试图估计长期价值,但它们使用不同目标。
7.1 Monte Carlo Target
$$y_t^{MC} = G_t = \sum_{k=0}^{T-t-1} \gamma^k r_{t+k}$$
它等待真实轨迹结束。
7.2 TD(0) Target
$$y_t^{TD(0)} = r_t+\gamma V(s_{t+1})$$
它只等待一步,然后用估计值接上未来。
7.3 两种方法的取舍
| 维度 | Monte Carlo | TD(0) |
|---|---|---|
| 是否等待轨迹结束 | 是 | 否 |
| 是否自举 | 否 | 是 |
| 目标是否包含估计值 | 否 | 是 |
| 偏差 | 通常较低 | 可能更高 |
| 方差 | 通常较高 | 通常较低 |
| 持续任务适用性 | 较弱 | 较强 |
Monte Carlo 更相信已经发生的完整现实。
TD 更相信“一步现实 + 自己对未来的判断”。
没有哪一种方法永远更好。
这会引出第 7 章的主题:偏差与方差之间不存在免费午餐。
8. n-step TD:在等待与猜测之间移动
Monte Carlo 和 TD(0) 是两个极端。
- Monte Carlo 等到终点;
- TD(0) 只等一步。
我们也可以等待 n 步,再开始自举。
n-step Return 定义为:
$$G_t^{(n)} = r_t +\gamma r_{t+1} +\cdots +\gamma^{n-1}r_{t+n-1} +\gamma^nV(s_{t+n})$$
使用求和写法:
$$G_t^{(n)} = \sum_{k=0}^{n-1} \gamma^k r_{t+k} +\gamma^nV(s_{t+n})$$
逐项解释:
| 符号 | 含义 |
|---|---|
G_t^(n) |
从时刻 t 开始的 n-step Return |
n |
等待多少步真实奖励后开始自举 |
Σ_{k=0}^{n-1} γ^k r_{t+k} |
前 n 步实际观察到的折扣奖励 |
γ^nV(s_{t+n}) |
第 n 步之后的未来价值估计 |
8.1 几个特殊情况
当:
$$n=1$$
得到:
$$G_t^{(1)} = r_t+\gamma V(s_{t+1})$$
这就是 TD(0)。
当 n 一直延伸到轨迹终点,不再使用剩余价值估计时,就逐渐接近 Monte Carlo。
因此,n 像一个滑块:
更早自举 ←──────────────→ 更晚自举
TD(0) Monte Carlo
8.2 手算一次
假设奖励为:
$$(r_0,r_1,r_2)=(1,2,3)$$
并且:
$$\gamma=0.9$$
已知:
$$V(s_2)=4$$
两步回报为:
$$\begin{aligned} G_0^{(2)} &= r_0+\gamma r_1+\gamma^2V(s_2)\ &= 1+0.9\times2+0.9^2\times4\ &= 1+1.8+3.24\ &= 6.04 \end{aligned}$$
这条目标使用了两步真实奖励,然后用 V(s_2) 接上尚未观察的未来。
9. TD(λ):不必只选一个截断点
选择一个固定 n 仍然有些生硬。
为什么一定只信任一步、三步或五步回报?能否把不同长度的回报组合起来?
TD(λ) 提供了一种加权平均。
一种前向视角写成:
$$G_t^\lambda = (1-\lambda)\sum_{n=1}^{\infty} \lambda^{n-1} G_t^{(n)}$$
其中:
| 符号 | 含义 |
|---|---|
G_t^λ |
λ-return |
G_t^(n) |
n-step Return |
λ |
控制不同步数回报权重的参数,通常满足 0≤λ≤1 |
(1-λ)λ^{n-1} |
第 n 步回报的权重 |
这条公式表示:
不只选择一个截断点,而是将多个截断位置按指数衰减加权。
当:
$$\lambda=0$$
主要依赖一步回报,接近 TD(0)。
当:
$$\lambda\to1$$
更多权重分配给较长回报,逐渐接近 Monte Carlo。
λ 成为调节偏差与方差的旋钮。
第 7 章讨论 GAE 时,我们会看到非常相似的结构。
10. Eligibility Trace:谁最近参与过,就先影响谁
TD(λ) 还有一种向后看的实现方式,称为 Eligibility Trace,常翻译为资格迹或迹。
直觉是:
当新的 TD Error 出现时,最近访问过的状态应该获得更多更新,更早访问过的状态则获得较弱更新。
对于表格型状态价值,可以定义:
$$e_t(s)= \gamma\lambda e_{t-1}(s)+\mathbf{1}(S_t=s)$$
逐项解释:
| 符号 | 含义 |
|---|---|
e_t(s) |
时刻 t,状态 s 的资格迹 |
γλ |
让过去访问痕迹逐渐衰减 |
e_{t-1}(s) |
上一时刻留下的痕迹 |
1(S_t=s) |
如果当前访问了状态 s,就为它增加一次痕迹 |
价值更新为:
$$V(s)\leftarrow V(s)+\alpha\delta_t e_t(s)$$
其中:
| 符号 | 含义 |
|---|---|
δ_t |
当前 TD Error |
e_t(s) |
当前状态与最近历史的相关程度 |
α |
学习率 |
新的误差信号会沿着最近访问过的状态向前扩散。
这样,信用不必等到整条轨迹结束,仍然能够影响此前多个状态。
11. 函数逼近:当价值不再是一张表
在小型问题中,可以为每个状态保存一个价值:
V(s_1)=...
V(s_2)=...
V(s_3)=...
但现实任务中的状态空间可能巨大,甚至连续。
语言模型的上下文更不可能逐条存表。
因此,我们使用带参数的函数逼近:
$$V_\theta(s)$$
其中:
| 符号 | 含义 |
|---|---|
θ |
神经网络参数 |
V_θ(s) |
参数为 θ 时,网络对状态价值的估计 |
TD Target 写成:
$$y_t = r_t +\gamma V_\theta(s_{t+1})$$
一种常见 TD Loss 为:
$$L_{\mathrm{TD}}(\theta)= \frac{1}{2} [ y_t -V_\theta(s_t) ]^2$$
代入目标:
$$L_{\mathrm{TD}}(\theta)= \frac{1}{2} [ r_t +\gamma V_\theta(s_{t+1})-V_\theta(s_t) ]^2$$
表面上,它很像监督学习中的均方误差。
但这里有一个关键差别:
标签
y_t不是外部提供的固定真值,而是包含了模型自己的预测。
这就是 RL Loss 看起来奇怪的原因之一。
第 6 章会专门拆解它。
12. Semi-Gradient:为什么要停止目标一侧的梯度
在 TD Loss 中:
$$L_{\mathrm{TD}}(\theta)= \frac{1}{2} [ r_t +\gamma V_\theta(s_{t+1})-V_\theta(s_t) ]^2$$
当前预测:
$$V_\theta(s_t)$$
依赖参数 θ。
目标中的下一状态价值:
$$V_\theta(s_{t+1})$$
也可能依赖同一组参数。
如果两边同时跟着梯度变化,目标会在训练过程中不断移动。
常见做法是:将目标一侧暂时视为常量。
写作:
$$y_t = r_t +\gamma \operatorname{stopgrad} ( V_\theta(s_{t+1}))$$
然后:
$$L_{\mathrm{TD}}(\theta)= \frac{1}{2} [ y_t-V_\theta(s_t) ]^2$$
其中:
| 符号 | 含义 |
|---|---|
stopgrad(·) |
前向计算保留数值,但反向传播时不让梯度穿过 |
y_t |
暂时固定的 TD Target |
V_θ(s_t) |
需要被训练的当前预测 |
这类更新称为 semi-gradient update。
之所以叫“半梯度”,是因为我们没有对目标中所有依赖参数的部分完整求导,而是有意识地截断了其中一部分。
这不是随意补丁。
它是在回答一个工程问题:
当模型使用自己的预测训练自己时,如何避免目标与预测同时剧烈移动?
13. 自举为什么危险
自举提高了样本效率,但也打开了误差传播的通道。
假设:
$$V(s_{t+1})$$
被高估。
那么 TD Target:
$$r_t+\gamma V(s_{t+1})$$
也会偏高。
于是:
$$V(s_t)$$
被向上推。
随后,更早状态的 TD Target 又会使用已经偏高的:
$$V(s_t)$$
错误就这样沿时间链向前传播。
可以把它写成:
下一状态高估
→ 当前 TD Target 偏高
→ 当前价值被高估
→ 更早状态的 TD Target 再次偏高
→ 误差逐步传播
如果再叠加:
- 神经网络函数逼近;
- Off-Policy 旧数据;
- 最大化操作;
- 高学习率;
- 分布漂移;
误差可能不只是传播,还会被放大。
这将在第 8 章和第 9 章继续展开。
14. 自举不等于盲目相信自己
读到这里,自举似乎像一种危险的循环论证:
为什么这个状态价值高?因为下一个状态价值高。
为什么下一个状态价值高?因为再下一个状态价值高。
但自举并不是完全脱离现实。
每一步更新都包含真实观察奖励:
$$r_t$$
终止状态也提供边界条件:
$$V(s_T)=0$$
真实奖励、终止状态和持续采样会不断校正价值估计。
问题不是“能不能自举”,而是:
如何让自举足够稳定,使真实信号能够逐步纠正预测,而不是让预测误差彼此放大?
目标网络、Double DQN、Replay Buffer、Clip、KL 约束等机制,都可以放回这个问题中理解。
15. 边界:自举解决了效率,不保证正确
自举带来三个明显优势:
- 不必等待轨迹结束;
- 更适合持续任务;
- 可以更快传播局部经验。
但它没有保证:
- 价值估计一定准确;
- 函数逼近一定稳定;
- 旧数据一定适用于当前策略;
- 奖励一定表达真实意图;
- 智能体一定探索到关键状态。
自举不是免费的加速器。
它用更高的学习效率,换来了更复杂的稳定性问题。
16. 回归全景图(Callback)
| 坐标轴 | 自举如何进入全景图 | 尚未解决什么 |
|---|---|---|
| 目标 | 自举仍然服务于长期回报 | 奖励是否正确 |
| 时间 | 用下一状态价值将未来压缩成一步目标 | 长距离信用传播仍可能衰减 |
| 更新 | TD Error 允许每走一步就更新价值 | 代理损失如何系统设计 |
| 估计 | 用预测更新预测,提高效率,也引入偏差 | 如何控制误差传播与发散 |
| 数据 | 可以利用局部转移样本 (s,a,r,s') 学习 |
旧数据与当前策略是否匹配 |
| 探索 | 自举只能传播已经访问过的经验 | 未探索区域仍然没有可靠价值 |
自举没有消灭等待未来的困难,而是把一部分等待转换成估计。它减少了样本成本,却把新的压力转移到了估计误差与训练稳定性上。
17. 本章小结
本章从一步 TD Target 开始:
$$y_t = r_t +\gamma V(s_{t+1})$$
定义 TD Error:
$$\delta_t = r_t +\gamma V(s_{t+1})-V(s_t)$$
并使用:
$$V(s_t)\leftarrow V(s_t) +\alpha\delta_t$$
完成每一步价值更新。
n-step TD 在等待真实奖励与使用价值估计之间移动:
$$G_t^{(n)} = \sum_{k=0}^{n-1} \gamma^k r_{t+k} +\gamma^nV(s_{t+n})$$
TD(λ) 则将多个截断位置组合起来:
$$G_t^\lambda = (1-\lambda)\sum_{n=1}^{\infty} \lambda^{n-1} G_t^{(n)}$$
进入神经网络后,TD Loss 写成:
$$L_{\mathrm{TD}}(\theta)= \frac{1}{2} [ y_t-V_\theta(s_t) ]^2$$
但 y_t 不是外部给出的静态标签,而是包含模型自己的预测。
这把我们带到下一章:
为什么强化学习的损失函数,看起来总不像普通损失函数?
第三部分:长期目标如何变成一次更新
第 6 章:为什么强化学习的损失函数看起来不像损失函数
1. 一种挥之不去的拼装感
如果你从监督学习进入强化学习,很容易产生一种不适感。
在图像分类中,损失函数看起来很自然。模型输出类别概率,数据集给出正确标签。交叉熵衡量预测与标签之间的差异。
例如:
$$L_{\mathrm{CE}} = -\sum_{c=1}^{C} y_c\log p_c$$
其中:
| 符号 | 含义 |
|---|---|
C |
类别数量 |
y_c |
正确标签在第 c 类上的取值 |
p_c |
模型预测第 c 类的概率 |
正确标签像一个锚点。模型预测偏离标签,就产生误差。
进入强化学习后,画风突然改变:
- TD Loss 里,标签包含模型自己的预测;
- Policy Gradient Loss 里,出现动作对数概率与 Advantage;
- PPO 在概率比率外面套上
clip; - RLHF 叠加 KL 惩罚与 Token Mask;
- DPO 看起来又像一个偏好分类损失;
- GRPO 用组内相对分数替代显式 Critic。
每一种方法似乎都在增加新的部件。
于是,读者会自然问:
强化学习的损失函数为什么总带有一种人为设计的拼装感?
答案是:
因为 RL Loss 通常不是“预测值与静态真值之间的误差”,而是将长期目标、采样估计、信用分配、分布约束和工程稳定性压缩成一次可执行更新的接口。
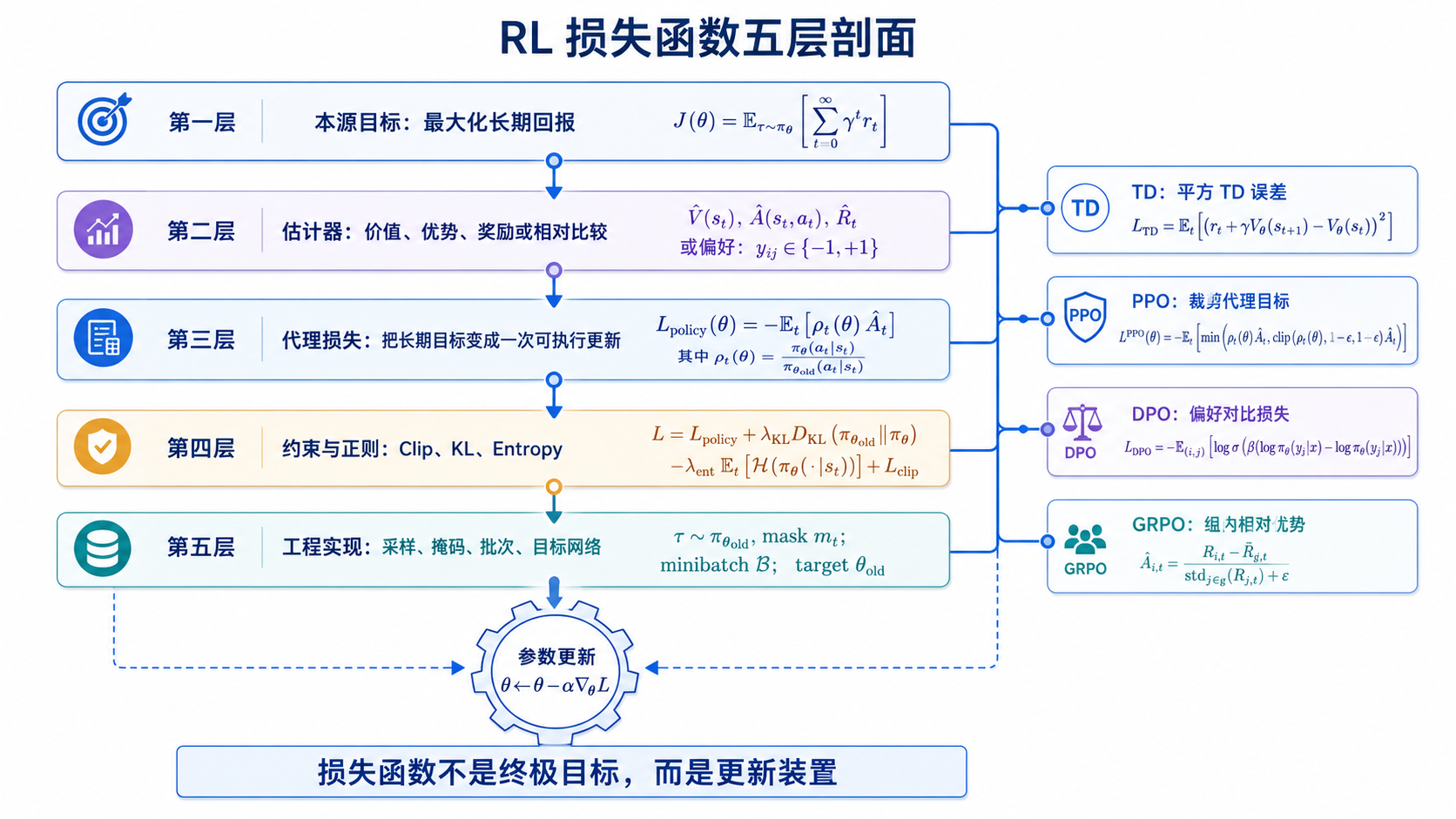
图 6-1:RL 损失函数五层剖面
2. 先区分五个层次
许多混乱来自把不同层次的问题都叫作“Loss”。
全书统一使用五层拆解法。
| 层次 | 回答的问题 | 常见例子 |
|---|---|---|
| 本源目标 | 最终想获得什么? | 长期回报、偏好满足、任务成功 |
| 估计器 | 看不见完整未来时,如何估计方向? | Return、Value、Q、Advantage、Reward Model、组内相对优势 |
| 代理损失 | 如何把估计量变成梯度? | TD Loss、Policy Gradient Surrogate、DPO Objective |
| 约束与正则 | 如何避免一次更新走得太远? | KL、PPO Clip、Entropy Bonus |
| 工程实现 | 如何让公式在真实系统中稳定执行? | stopgrad、mask、归一化、梯度裁剪、数值稳定 |
这五层不是五种互相替代的方法,而是一条链。
本源目标
→ 估计器
→ 代理损失
→ 约束与正则
→ 工程实现
→ 参数更新
不同算法的区别,常常不是它们处在不同世界,而是它们在这条链上选择了不同组件。
3. 本源目标:真正想优化的是 J(π)
第一章定义了策略目标:
$$J(\pi) = \mathbf{E}{\tau \sim \pi} [ \sum{t=0}^{T-1} \gamma^t r_t ]$$
理想状态下,希望找到:
$$\pi^* = \arg\max_\pi J(\pi)$$
这才是强化学习真正想做的事。
但在真实训练中,我们通常不能直接把:
$$-J(\pi)$$
丢进自动微分框架,然后期待所有问题自动解决。
为什么?
因为:
- 轨迹由策略采样产生;
- 环境转移通常不可微;
- 奖励可能延迟;
- 轨迹长度可能变化;
- 数据分布会随着策略变化;
- 采样噪声可能很大。
需要准确表述的一点是:
J(π)并非原则上不可求导。策略梯度定理正是在估计它的梯度。困难在于,梯度通常不能像普通监督学习那样通过一条静态、确定、端到端可微的计算图直接得到。
因此,我们需要估计器和代理损失。
4. 第一条路线:TD Loss
4.1 从 Bellman 关系到训练目标
Bellman 方程告诉我们:
$$V^\pi(s_t)= \mathbf{E} [ r_t +\gamma V^\pi(s_{t+1}) ]$$
训练时,我们使用 TD Target:
$$y_t = r_t +\gamma \operatorname{stopgrad} ( V_\theta(s_{t+1}))$$
然后定义 TD Loss:
$$L_{\mathrm{TD}}(\theta)= \frac{1}{2} [ y_t -V_\theta(s_t) ]^2$$
代入目标:
$$L_{\mathrm{TD}}(\theta)= \frac{1}{2} [ r_t +\gamma \operatorname{stopgrad} ( V_\theta(s_{t+1}))-V_\theta(s_t) ]^2$$
4.2 为什么它看起来像监督学习
表面上,TD Loss 像一个普通均方误差:
标签 - 预测
其中:
- 预测是
V_θ(s_t); - 标签是
y_t。
但这个标签并不是外部给出的 ground truth。
它由两部分组成:
真实奖励 + 模型对下一状态的预测
因此,TD Loss 更准确的理解不是“拟合真值”,而是:
让价值函数逐渐满足 Bellman 自洽关系。
4.3 为什么需要 stopgrad
如果目标侧:
$$V_\theta(s_{t+1})$$
也跟着当前梯度立即变化,网络会一边追目标,一边移动目标。
stopgrad 的作用是:
前向计算保留数值,反向传播时暂时冻结目标一侧。
这让 TD Loss 更像一次局部固定点逼近。
它不是严格等同于普通监督学习,也不是任意补丁。
5. 第二条路线:Policy Gradient Surrogate
价值方法尝试学习:
$$V(s)$$
或:
$$Q(s,a)$$
再据此选择动作。
策略方法则直接参数化策略:
$$\pi_\theta(a\mid s)$$
并尝试增加高回报动作出现的概率。
策略梯度定理的一种常见形式是:
$$\nabla_\theta J(\theta) = E_{\tau \sim \pi_\theta} [ \sum_{t=0}^{T-1} \nabla_\theta \log \pi_\theta(a_t | s_t) \hat{A}_t ]$$
逐项解释:
| 符号 | 含义 |
|---|---|
θ |
策略网络参数 |
J(θ) |
参数化策略的期望长期回报 |
π_θ(a_t|s_t) |
当前状态下采取动作 a_t 的概率 |
log π_θ(a_t|s_t) |
动作对数概率 |
∇_θ |
对参数求梯度 |
Â_t |
Advantage 的估计值 |
直觉是:
- 如果:
$$\hat{A}_t>0$$
说明动作比平均水平好,应该提高它的概率;
- 如果:
$$\hat{A}_t<0$$
说明动作比平均水平差,应该降低它的概率。
为了使用梯度下降,常把要最大化的方向写成要最小化的 Loss:
$$L_{\mathrm{PG}}(\theta)= - \mathbf{E} [ \log \pi_\theta(a_t\mid s_t) \hat{A}_t ]$$
这不是“预测错误”的平方。
它更像一个梯度载体:
用 Advantage 给动作对数概率加权,让优化器知道哪些动作概率应该上升,哪些应该下降。
第 17 章会完整推导 Policy Gradient 和 Log-Derivative Trick。
6. PPO:为什么还要对更新加护栏
策略梯度已经提供了方向,但一次更新如果走得太远,策略可能突然改变。
旧数据来自旧策略:
$$\pi_{\theta_{\mathrm{old}}}$$
更新后,我们想训练新策略:
$$\pi_\theta$$
定义概率比率:
$$r_t(\theta)= \frac{ \pi_\theta(a_t\mid s_t)}{ \pi_{\theta_{\mathrm{old}}}(a_t\mid s_t)}$$
它衡量:
新策略相对于旧策略,提高或降低了动作
a_t的概率多少?
如果:
$$r_t(\theta)=1$$
说明概率没有变化。
如果:
$$r_t(\theta)>1$$
说明新策略更倾向于选择这个动作。
如果:
$$r_t(\theta)<1$$
说明新策略降低了这个动作的概率。
PPO 的 Clipped Objective 常写为:
$$L_{\mathrm{PPO}}^{\mathrm{clip}}(\theta)= \mathbf{E}_t [ \min ( r_t(\theta)\hat{A}_t,; \operatorname{clip} ( r_t(\theta), 1-\epsilon, 1+\epsilon )\hat{A}_t ) ]$$
逐项解释:
| 符号 | 含义 |
|---|---|
r_t(θ) |
新旧策略对同一动作的概率比率 |
Â_t |
动作优势估计 |
ε |
允许概率比率变化的大致范围 |
clip(r,1-ε,1+ε) |
将比率限制在区间附近 |
min |
对过度改进保持保守 |
PPO Clip 的作用不是重新定义最终目标。
它是在说:
即使方向看起来不错,也不要一步走得太远。
它属于约束与稳定化层,而不是本源目标层。
第 18 章会结合 Actor-Critic 完整解释 PPO。
7. KL:离参考策略不要太远
另一种常见约束是 KL Divergence。
对于两个离散概率分布 p 和 q:
$$D_{\mathrm{KL}}(p \parallel q)= \sum_x p(x)\log \frac{p(x)}{q(x)}$$
它衡量两个分布之间的差异。
在策略优化中,可以使用:
$$D_{\mathrm{KL}} ( \pi_\theta(\cdot\mid s)\parallel \pi_{\mathrm{ref}}(\cdot\mid s))$$
其中:
| 符号 | 含义 |
|---|---|
π_θ |
当前正在训练的新策略 |
π_ref |
参考策略 |
D_KL |
两个动作概率分布的差异 |
带 KL 正则的目标可以写成:
$$J_{\mathrm{KL}}(\pi)= \mathbf{E} [ R ] - \beta \mathbf{E} [ D_{\mathrm{KL}} ( \pi(\cdot\mid s)\parallel \pi_{\mathrm{ref}}(\cdot\mid s)) ]$$
这里:
| 符号 | 含义 |
|---|---|
R |
想提高的奖励 |
β |
KL 惩罚强度 |
π_ref |
参考模型或旧策略 |
β 越大,策略越不敢偏离参考分布。
在 RLHF 中,KL 常用于防止语言模型为了追求 Reward Model 分数而迅速偏离原本语言能力。
KL 约束没有消灭目标偏差,只是限制了偏差造成的破坏速度。
8. 工程实现层:公式落地时仍然需要判断
即使理论公式已经确定,真实训练仍然包含许多工程选择。
这些选择不应被轻视,也不能与理论目标混为一谈。
8.1 Mask
语言模型训练中,一个 batch 里的回答长度可能不同。补齐位置不应该参与损失。
可以写成:
$$L = \frac{ \sum_{t=1}^{T} m_t\ell_t}{ \sum_{t=1}^{T} m_t}$$
其中:
| 符号 | 含义 |
|---|---|
ℓ_t |
第 t 个 Token 的局部损失 |
m_t |
Mask,真实 Token 取 1,补齐位置取 0 |
L |
聚合后的有效损失 |
Mask 不改变算法哲学,却决定训练是否计算正确。
8.2 Advantage Normalization
一个 batch 中的 Advantage 可能尺度差异很大。
常见归一化写成:
$$\hat{A}_t^{\mathrm{norm}} = \frac{ \hat{A}_t-\mu_A}{ \sigma_A+\varepsilon}$$
其中:
| 符号 | 含义 |
|---|---|
μ_A |
batch 中 Advantage 的平均值 |
σ_A |
batch 中 Advantage 的标准差 |
ε |
防止除零的小常数 |
它改善数值尺度,但也意味着更新行为依赖 batch 统计量。
8.3 Gradient Clipping
如果梯度过大,可以限制梯度范数:
$$g \leftarrow g \cdot \min ( 1,; \frac{c}{|g|} )$$
其中:
| 符号 | 含义 |
|---|---|
g |
原始梯度 |
||g|| |
梯度范数 |
c |
允许的最大范数 |
梯度裁剪是数值稳定机制,不是新的优化目标。
9. DPO:显式 Reward Model 消失了吗
到了 DPO,损失函数看起来又像监督学习。
对于提示词 x、偏好回答 y_w 和较差回答 y_l,DPO Objective 的常见形式为:
$$L_{\mathrm{DPO}}(\theta)= - \mathbf{E} [ \log \sigma ( \beta [ \log \frac{ \pi_\theta(y_w\mid x)}{ \pi_{\mathrm{ref}}(y_w\mid x)} - \log \frac{ \pi_\theta(y_l\mid x)}{ \pi_{\mathrm{ref}}(y_l\mid x)} ] ) ]$$
这里:
| 符号 | 含义 |
|---|---|
x |
提示词 |
y_w |
偏好数据中更好的回答 |
y_l |
偏好数据中较差的回答 |
π_θ |
正在训练的策略模型 |
π_ref |
固定参考模型 |
β |
控制相对偏离程度的系数 |
σ |
Sigmoid 函数 |
这条公式看起来像偏好分类。
但它并不意味着奖励问题彻底消失。
更准确的说法是:
在特定假设下,显式 Reward Model 被消去,偏好优化被重写为策略与参考模型之间的相对对数概率差。
DPO 删除了一个显式组件,却把部分矛盾迁移到:
- 偏好数据质量;
- 参考模型;
- 推导假设;
- 数据覆盖范围;
- 序列对数概率结构。
第 22 章会完整拆解它。
10. GRPO:显式 Critic 消失了吗
GRPO 使用同一个问题下的一组候选回答。
假设对一个提示词采样 G 个回答:
$${y_1,y_2,\ldots,y_G}$$
每个回答获得奖励:
$${R_1,R_2,\ldots,R_G}$$
一种组内相对优势写成:
$$\hat{A}_i = \frac{ R_i-\mu_R}{ \sigma_R+\varepsilon}$$
其中:
$$\mu_R = \frac{1}{G} \sum_{j=1}^{G} R_j$$
$$\sigma_R = \sqrt{ \frac{1}{G} \sum_{j=1}^{G} ( R_j-\mu_R )^2}$$
逐项解释:
| 符号 | 含义 |
|---|---|
R_i |
第 i 个候选回答的奖励 |
μ_R |
同组回答奖励均值 |
σ_R |
同组回答奖励标准差 |
Â_i |
第 i 个回答相对同组平均水平的优势 |
GRPO 可以减少对单独训练 Critic 的依赖。
但它没有删除估计问题。
它将部分估计工作转移到:
- 组内样本质量;
- 奖励噪声;
- 候选多样性;
- 标准化统计;
- 在线采样成本。
少一个显式模块,不等于少一个本质问题。
11. 一条统一的 Loss 视角
许多 RL 训练目标可以粗略理解为:
$$L_{\mathrm{total}} = L_{\mathrm{proxy}} +\beta L_{\mathrm{constraint}} +\lambda L_{\mathrm{regularization}}$$
其中:
| 符号 | 含义 |
|---|---|
L_proxy |
承载主要更新方向的代理损失 |
L_constraint |
限制策略、价值或分布漂移的约束项 |
L_regularization |
改善探索、数值稳定或泛化的正则项 |
β、λ |
控制不同项强度的系数 |
注意,这不是所有算法必须严格照抄的唯一公式。
它是一种阅读框架。
面对一个新的 Loss,可以问:
- 哪一项在表达主要方向?
- 哪一项在限制更新范围?
- 哪一项只是工程稳定化?
- 哪一项依赖估计器?
- 哪一项把旧问题隐藏到了新的假设里?
这样,复杂公式就不再是一整块难以理解的墙,而是一组可以拆开的组件。
12. 为什么不存在唯一“天然 Loss”
监督学习也会设计损失函数,但在许多经典任务中,标签提供了较稳定的参照物。
强化学习不同。
它必须同时面对:
- 长期回报;
- 延迟反馈;
- 信用分配;
- 采样噪声;
- 自举偏差;
- 策略变化;
- 数据漂移;
- 探索压力;
- 数值稳定性。
不同算法对这些问题做不同取舍,因此 Loss 也会长成不同形状。
TD Loss 更接近固定点逼近。
Policy Gradient Loss 更接近梯度估计载体。
PPO Clip 更接近更新护栏。
KL 更接近分布锚点。
DPO 是在假设条件下对偏好优化的重参数化。
GRPO 将部分价值估计转移到组内比较。
它们不应该被混成同一类东西。
13. 边界:复杂不等于任意
看到 RL Loss 中大量设计项,容易走向两个极端。
第一个极端是:
这些公式都是拍脑袋拼出来的。
这不准确。
很多设计来自明确问题:
stopgrad控制移动目标;- PPO Clip 限制策略突变;
- KL 限制偏离参考分布;
- Mask 排除无效 Token;
- Advantage Normalization 控制尺度;
- Group Baseline 提供相对比较。
第二个极端是:
只要数学推导成立,Loss 就一定可靠。
这也不准确。
Loss 仍然依赖:
- 奖励是否合理;
- 假设是否成立;
- 数据是否覆盖关键行为;
- 估计器是否可靠;
- 工程实现是否正确;
- 超参数是否处在合适范围。
因此,更准确的判断是:
RL Loss 不是任意拼装,也不是自动正确。它是理论目标、估计假设和工程约束共同塑造的可执行近似。
14. 回归全景图(Callback)
| 坐标轴 | Loss 如何进入全景图 | 尚未解决什么 |
|---|---|---|
| 目标 | 本源目标仍然是长期回报或偏好满足 | 代理奖励是否代表真实意图 |
| 时间 | TD Target、Return 与 Advantage 将延迟反馈压缩为局部信号 | 长序列信用仍可能不准确 |
| 更新 | 代理损失、Clip、KL、Mask、stopgrad 共同形成可执行更新 |
如何为具体任务选择组合 |
| 估计 | Value、Advantage、Reward Model、组内统计都可能参与估计 | 估计误差会如何传播 |
| 数据 | Loss 使用的数据来自当前策略、旧策略或固定偏好集 | 分布变化如何影响可靠性 |
| 探索 | Entropy、采样温度与在线生成会影响探索 | 如何在探索与稳定之间取舍 |
RL Loss 没有消灭强化学习的矛盾。它将矛盾压缩成优化器可以执行的一步,同时也把许多取舍写进了公式、约束和工程细节。
15. 本章小结
本章建立了理解 RL Loss 的五层框架:
本源目标
→ 估计器
→ 代理损失
→ 约束与正则
→ 工程实现
→ 参数更新
TD Loss 通过 Bellman 自洽关系训练价值:
$$L_{\mathrm{TD}}(\theta)= \frac{1}{2} [ r_t +\gamma \operatorname{stopgrad} ( V_\theta(s_{t+1}))-V_\theta(s_t) ]^2$$
Policy Gradient 使用 Advantage 为动作概率更新方向加权:
$$L_{\mathrm{PG}}(\theta)= - \mathbf{E} [ \log \pi_\theta(a_t\mid s_t) \hat{A}_t ]$$
PPO Clip 和 KL 惩罚限制策略更新不要走得太远。
DPO 与 GRPO 则提醒我们:
显式模块消失,不等于本质矛盾消失。问题往往只是迁移到了新的数据、假设与统计量中。
下一部分,我们开始集中讨论估计的代价:
当我们不再等待完整未来,而是不断使用近似,偏差与方差将如何进入系统?
第四部分:每一种估计都有代价
第 7 章:偏差与方差:不存在免费的估计
1. 更接近真实,为什么未必更好用
上一章讨论了自举。
Monte Carlo 等待完整轨迹,使用真正观察到的回报。TD 不等终局,只观察一步或几步,再用价值估计接上未来。
直觉上,Monte Carlo 似乎更可靠:
既然真实结果最终会出现,为什么不直接相信真实结果?
问题在于,真实结果也可能非常嘈杂。
想象一个推荐系统。即使展示同一条内容,不同用户也可能有完全不同反应。想象一个游戏智能体。即使执行同一种策略,随机地图、对手行为和初始位置也会改变最终结果。想象一个语言模型。即使提示词相同,采样温度也可能产生不同回答。
一条完整轨迹确实真实,却未必稳定。
强化学习中的许多算法改进,都在同一架天平上移动:
少猜一点,通常要承受更大波动;想稳定一点,通常要接受更多近似。
这就是偏差与方差之间的取舍。
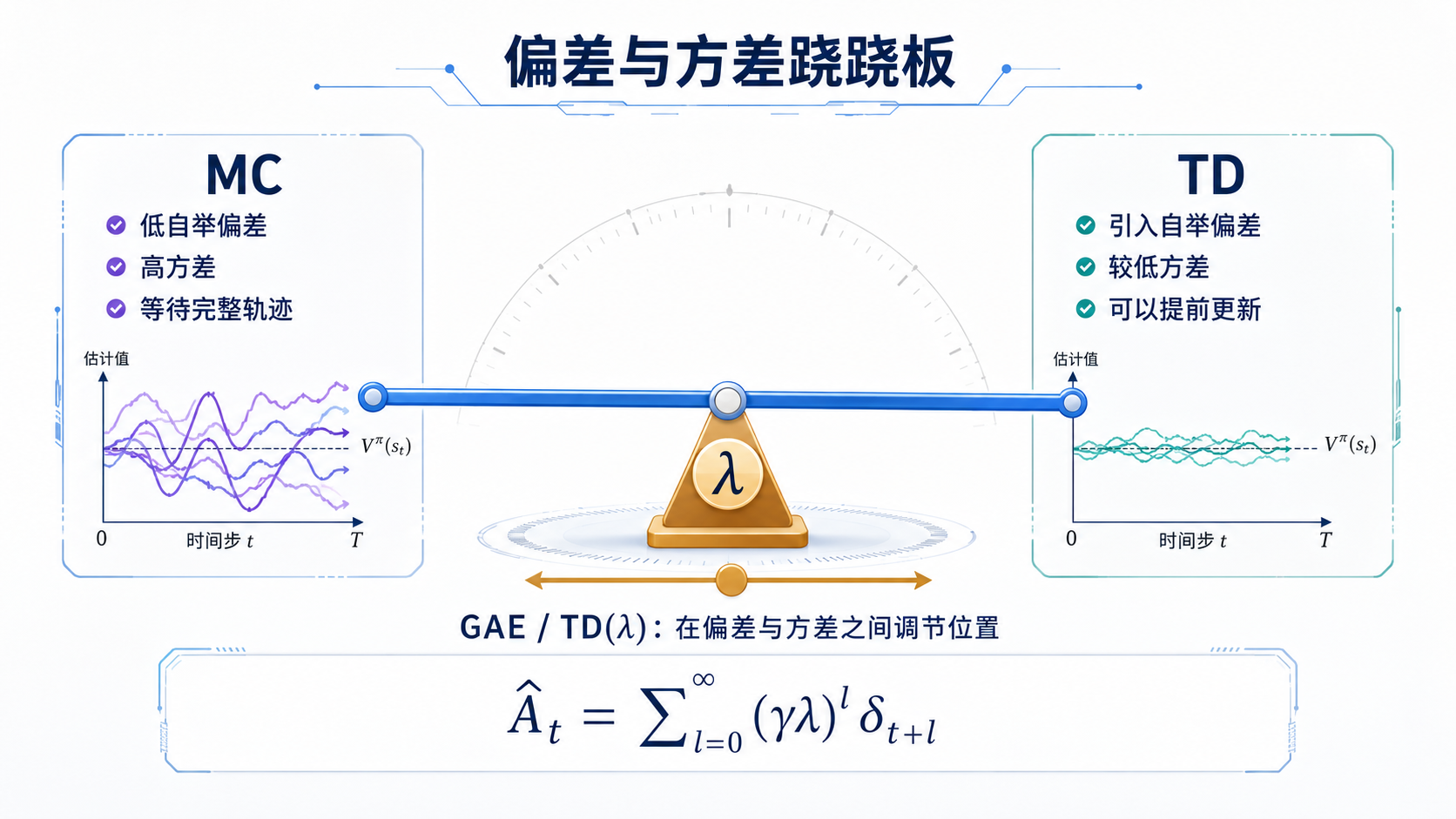
图 7-1:偏差与方差跷跷板
2. 什么是偏差
假设我们想估计一个状态的真实价值:
$$V^\pi(s)$$
但每次根据有限数据得到的估计可能不同:
$$\hat{V}(s)$$
估计器的偏差(bias)定义为:
$$\operatorname{Bias} [ \hat{V}(s)] = \mathbf{E} [ \hat{V}(s)] -V^\pi(s)$$
逐项解释:
| 符号 | 含义 |
|---|---|
V^π(s) |
想估计的真实状态价值 |
V̂(s) |
根据有限样本得到的估计 |
E[V̂(s)] |
如果重复采样很多次,估计值的平均 |
Bias[V̂(s)] |
估计值平均偏离真实值多少 |
如果:
$$\operatorname{Bias} [ \hat{V}(s) ] =0$$
称估计器无偏。
无偏并不意味着每次估计都准确。
它只表示:
如果重复很多次,误差平均起来不会系统性偏向某一侧。
3. 什么是方差
方差(variance)衡量:
每次重新采样时,估计值会波动多大?
定义为:
$$\operatorname{Var} [ \hat{V}(s)] = \mathbf{E} [ ( \hat{V}(s)- \mathbf{E} [ \hat{V}(s)] )^2 ]$$
逐项解释:
| 符号 | 含义 |
|---|---|
E[V̂(s)] |
多次估计的平均值 |
V̂(s)-E[V̂(s)] |
某次估计偏离平均值多少 |
| 平方 | 不让正负波动相互抵消 |
Var[V̂(s)] |
估计波动的平均强度 |
3.1 两组估计
假设真实价值为:
$$V^\pi(s)=10$$
估计器 A 重复四次得到:
$$(9,11,10,10)$$
估计器 B 得到:
$$(2,18,5,15)$$
两组平均值都是:
$$10$$
它们都可能无偏。
但估计器 B 波动更大,方差更高。
训练时,高方差意味着梯度方向会反复摇摆。即使平均方向正确,优化过程也可能非常缓慢。
4. 均方误差如何拆开
估计器总体好不好,常用均方误差衡量:
$$\operatorname{MSE} [ \hat{V}(s)] = \mathbf{E} [ ( \hat{V}(s)-V\pi(s))2 ]$$
它可以拆解为:
$$\operatorname{MSE} = \operatorname{Bias}^2 +\operatorname{Variance}$$
在更一般的监督学习表述中,还可能单独写出不可约噪声项。这里先聚焦价值估计自身的偏差与方差。
这条公式告诉我们:
估计误差不只有一种来源。减少偏差,可能增加方差;压低方差,也可能引入偏差。
算法设计不是只追求某一项最小,而是在任务条件下寻找可用平衡。
5. Monte Carlo:较少猜测,较大波动
Monte Carlo Target 为:
$$y_t^{MC} = G_t = \sum_{k=0}^{T-t-1} \gamma^k r_{t+k}$$
它使用完整轨迹中的实际奖励。
如果轨迹采样方式与目标策略一致,环境条件合适,Monte Carlo Return 通常可以作为价值的无偏样本。
但一条完整轨迹包含许多随机因素:
- 后续动作采样;
- 环境随机转移;
- 对手行为;
- 奖励噪声;
- 轨迹长度变化。
这些随机性都会进入:
$$G_t$$
因此,Monte Carlo 通常方差较大。
5.1 手算一个高方差例子
假设同一个状态 s 有两种后续结果:
50%概率最终获得20;50%概率最终获得0。
真实期望价值为:
$$V^\pi(s) = 0.5\times20 +0.5\times0 =10$$
但每次 Monte Carlo 采样只会看到:
$$20$$
或:
$$0$$
单次样本可能距离真实期望很远。
如果只采少量轨迹,价值更新会明显摇摆。
6. TD:更早猜测,通常更稳定
TD(0) Target 为:
$$y_t^{TD} = r_t +\gamma V(s_{t+1})$$
它不等待完整轨迹,而是使用下一状态价值估计。
这样做减少了后续轨迹随机性进入目标的程度。
但新的问题是:
$$V(s_{t+1})$$
可能不准确。
如果下一状态价值被低估,当前 TD Target 也会偏低;如果下一状态价值被高估,偏差也会向前传播。
因此,TD 通常:
- 方差较低;
- 但可能引入自举偏差。
Monte Carlo 与 TD 的差别,可以概括为:
| 方法 | 更相信什么 | 主要代价 |
|---|---|---|
| Monte Carlo | 真实发生的完整轨迹 | 方差高,必须等终局 |
| TD | 一步现实加未来估计 | 引入自举偏差 |
7. n-step Return:没有唯一正确截断点
n-step Return 为:
$$G_t^{(n)} = \sum_{k=0}^{n-1} \gamma^k r_{t+k} +\gamma^nV(s_{t+n})$$
它等待 n 步真实奖励,再用价值估计接上未来。
当 n 较小:
- 更早自举;
- 方差通常较低;
- 更依赖价值估计;
- 偏差可能更明显。
当 n 较大:
- 使用更多真实奖励;
- 更接近 Monte Carlo;
- 偏差可能下降;
- 方差与等待成本通常增加。
因此,n 不是单纯的技术参数,而是在选择:
我们愿意等待多少现实,又愿意提前相信多少预测?
8. λ-return:将许多截断点混合起来
与其只选择一个 n,可以组合不同长度的回报。
λ-return 写作:
$$G_t^\lambda = (1-\lambda)\sum_{n=1}^{\infty} \lambda^{n-1} G_t^{(n)}$$
其中:
| 符号 | 含义 |
|---|---|
G_t^λ |
混合后的 λ-return |
G_t^(n) |
n-step Return |
λ |
权重衰减参数 |
(1-λ)λ^{n-1} |
第 n 步回报的权重 |
当:
$$\lambda=0$$
主要依赖一步回报。
当:
$$\lambda\to1$$
更多权重给到较长回报,逐渐接近 Monte Carlo。
λ 将离散选择变成连续调节。
9. Advantage:策略更新需要相对评价
策略梯度通常不直接使用绝对回报,而是使用 Advantage:
$$A^\pi(s,a)= Q\pi(s,a)-V\pi(s)$$
它回答:
在当前状态下,这个动作比平均水平好多少?
实际训练中,真实 Advantage 通常不可直接获得,因此需要估计:
$$\hat{A}_t$$
最简单的一步估计是 TD Error:
$$\delta_t = r_t +\gamma V(s_{t+1})-V(s_t)$$
为什么它可以近似 Advantage?
直觉上:
r_t+γV(s_{t+1})估计采取当前动作之后的长期价值;V(s_t)估计当前状态下的平均价值;- 两者相减,得到当前动作相对平均水平的超额表现。
因此:
$$\delta_t \approx A^\pi(s_t,a_t)$$
但一步 TD Error 可能过于局部。
于是,引出 GAE。
10. GAE:把多个时间尺度的 TD Error 混合起来
GAE 全称为 Generalized Advantage Estimation。
它使用多个未来 TD Error 的折扣加权和:
$$\hat A_t^{GAE} = \sum_{l=0}^\infty (\gamma\lambda)^l \delta_{t+l}$$
展开前几项:
$$\hat A_t^{GAE} = \delta_t + \gamma\lambda\delta_{t+1} + (\gamma\lambda)^2\delta_{t+2}+\cdots$$
逐项解释:
| 符号 | 含义 |
|---|---|
Â_t^GAE |
时刻 t 的 Advantage 估计 |
δ_{t+l} |
从当前时刻向后第 l 步的 TD Error |
γ |
对遥远未来的折扣 |
λ |
控制使用多少长程信息 |
(γλ)^l |
越远的 TD Error 权重越小 |
GAE 的直觉是:
不只看当前一步预测误差,也让后续几步误差按衰减权重返回现在。
λ 较小时:
- 更接近一步 TD;
- 通常方差更低;
- 更依赖 Critic 准确性。
λ 较大时:
- 使用更长时间的信息;
- 更接近 Monte Carlo;
- 通常偏差降低;
- 方差可能提高。
10.1 手算一次
假设:
$$\gamma=0.9$$
$$\lambda=0.8$$
并且未来三步 TD Error 为:
$$\delta_t=2$$
$$\delta_{t+1}=1$$
$$\delta_{t+2}=-0.5$$
截断到三步,GAE 为:
$$\begin{aligned} \hat{A}_t^{GAE} &= 2 +(0.9\times0.8)\times1\ &\quad +(0.9\times0.8)^2\times(-0.5)\ &= 2+0.72-0.2592\ &= 2.4608 \end{aligned}$$
当前动作得到正 Advantage,说明它比平均水平更好。
但这个判断不是只依赖一步,而是吸收了后续误差信息。
11. γ 与 λ 的分工
γ 和 λ 经常一起出现,容易混淆。
它们都让遥远未来权重下降,但作用不同。
| 参数 | 主要问题 | 直觉 |
|---|---|---|
γ |
未来奖励本身值多少 | 任务层面的时间偏好与有效视野 |
λ |
Advantage 估计使用多长的信息链 | 估计器层面的偏差与方差取舍 |
γ 更接近任务定义。
λ 更接近估计策略。
在 GAE 中,它们共同出现:
$$(\gamma\lambda)^l$$
但不能因此认为两者含义相同。
12. 为什么没有万能参数
面对偏差与方差,读者很容易希望得到一个固定答案:
γ和λ设成多少最好?
不存在适用于所有任务的唯一答案。
因为任务不同:
- 奖励延迟程度不同;
- 轨迹长度不同;
- 环境随机性不同;
- Critic 准确性不同;
- 样本数量不同;
- 策略更新幅度不同。
如果 Critic 很不准确,过早自举会传播错误。
如果轨迹非常嘈杂,过度依赖 Monte Carlo 又会导致高方差。
如果奖励距离当前动作很远,太小的 γ 或 λ 可能让信号几乎传不回来。
调参不是寻找宇宙常数,而是在具体任务中选择合适的估计代价。
13. 偏差与方差并不只属于价值估计
偏差与方差贯穿强化学习。
13.1 Reward Model
Reward Model 使用有限偏好数据估计人类判断。
- 模型过于简单,可能产生系统性偏差;
- 模型过于灵活、数据噪声大,可能产生高方差或过拟合。
13.2 Importance Sampling
使用旧策略数据估计新策略表现时,需要修正分布差异。
- 修正不足,会引入偏差;
- 修正权重过大,又可能产生高方差。
13.3 GRPO
使用组内相对奖励代替显式 Critic 时:
- 减少了单独价值网络带来的估计误差;
- 但组内样本数量、奖励噪声和候选多样性会影响方差。
算法换了外观,天平仍然存在。
14. 边界:稳定不等于正确
降低方差通常让训练曲线更加平滑。
但平滑不代表正确。
一个稳定但有偏的估计器,可能持续把策略引向错误方向。一个波动较大的估计器,平均方向反而可能更接近真实目标。
因此,评估算法时不能只看:
- Loss 是否下降;
- 曲线是否平滑;
- 梯度是否稳定。
还要问:
- 最终策略是否真的更好?
- 估计是否在关键区域可靠?
- 分布变化后是否仍然有效?
- 代理奖励是否偏离真实意图?
偏差与方差只是估计问题的两个坐标,不是全部世界。
15. 回归全景图(Callback)
| 坐标轴 | 偏差与方差如何进入全景图 | 尚未解决什么 |
|---|---|---|
| 目标 | 估计器仍服务于长期回报 | 奖励代理是否正确 |
| 时间 | MC、TD、n-step、GAE 使用不同长度的信息链 | 长程信用仍可能衰减 |
| 更新 | Advantage 估计直接影响策略梯度方向 | 如何限制策略更新幅度 |
| 估计 | n、γ、λ 在偏差与方差之间移动 |
函数逼近与分布漂移会进一步放大误差 |
| 数据 | 有限轨迹造成采样波动 | 如何复用旧数据而不失真 |
| 探索 | 探索增加数据覆盖,也增加回报波动 | 如何控制探索成本 |
偏差与方差没有被任何算法彻底消灭。算法只能选择:愿意在哪个位置承担哪一种误差。
16. 本章小结
偏差衡量估计是否系统性偏离真实值:
$$\operatorname{Bias} [ \hat{V}(s)] = \mathbf{E} [ \hat{V}(s)] -V^\pi(s)$$
方差衡量重新采样时估计波动多大:
$$\operatorname{Var} [ \hat{V}(s)] = \mathbf{E} [ ( \hat{V}(s)- \mathbf{E} [ \hat{V}(s)] )^2 ]$$
GAE 将多个时间尺度的 TD Error 组合起来:
$$\hat A_t^{GAE} = \sum_{l=0}^\infty (\gamma\lambda)^l \delta_{t+l}$$
它不是凭空出现的技巧,而是偏差与方差取舍的工程化表达。
下一章将看到另一种更隐蔽的误差:
当算法总是从多个估计值中选择最大的那个,噪声为什么会被系统性放大?
第 8 章:最大化偏差与价值幻觉
1. 为什么总挑最高分会出问题
假设你要从十家餐厅中选择一家。
你不知道它们的真实质量,只能参考带有噪声的评分。某家餐厅可能真实水平一般,却恰好因为样本少、评价偶然偏高,成为排行榜第一名。
如果你总是选择当前评分最高的餐厅,就会系统性偏爱那些“被高估”的对象。
强化学习中的价值方法也会遇到类似问题。
智能体面对多个动作,常常选择:
$$\max_a Q(s,a)$$
但 Q(s,a) 往往不是精确真值,而是带有误差的估计。
一旦从许多 noisy estimates 中挑选最大值,噪声不再对称。偏高的估计更容易被选中,偏低的估计则更容易被忽略。
这称为最大化偏差(maximization bias)或过高估计(overestimation)。
2. Q-Learning:把最优未来带回现在
Bellman 最优方程为:
$$Q^(s_t,a_t)= \mathbf{E} [ r_t +\gamma \max_{a'} Q^(s_{t+1},a') ]$$
Q-Learning 使用采样更新:
$$Q(s_t,a_t)\leftarrow Q(s_t,a_t)+\alpha [ r_t +\gamma \max_{a'} Q(s_{t+1},a')-Q(s_t,a_t) ]$$
其中:
| 符号 | 含义 |
|---|---|
Q(s_t,a_t) |
当前对动作价值的估计 |
r_t |
当前奖励 |
max_{a'}Q(s_{t+1},a') |
下一状态中估计价值最高的动作 |
γ |
折扣因子 |
α |
学习率 |
括号中的:
$$r_t +\gamma \max_{a'} Q(s_{t+1},a')-Q(s_t,a_t)$$
是 Q-Learning 的 TD Error。
Q-Learning 的力量来自:
即使采样行为带有探索,它仍然可以朝“下一步选择最优动作”的目标更新。
但风险也在这里:
$$\max_{a'}Q(s_{t+1},a')$$
会偏爱被高估的动作。
3. 手算一次:真实价值相同,最大值仍然偏高
假设下一状态有两个动作:
$$a_1,;a_2$$
它们真实价值都为:
$$Q^{\ast}(s',a_{1}) = Q^{\ast}(s',a_{2}) = 0$$
但估计带有噪声。每次估计可能为:
$$\hat{Q}(s',a_{i}) = +1 \ (p=0.5) \ , \ -1 \ (p=0.5)$$
对每个动作单独看,估计无偏:
$$\mathbf{E} [ \hat{Q}(s',a_i) ] =0$$
但如果每次取最大值,四种情况为:
Q̂(s',a_1) |
Q̂(s',a_2) |
最大值 |
|---|---|---|
+1 |
+1 |
+1 |
+1 |
-1 |
+1 |
-1 |
+1 |
+1 |
-1 |
-1 |
-1 |
最大值期望为:
$$\mathbf{E} [ \max_a \hat{Q}(s',a) ] = \frac{ 1+1+1-1}{4} =0.5$$
真实最大值却是:
$$\max_a Q^*(s',a) =0$$
于是:
$$\mathbf{E} [ \max_a \hat{Q}(s',a)] > \max_a Q^*(s',a)$$
每个动作估计单独看都没有偏差,但取最大值后,整体产生了过高估计。
这就是最大化偏差。
4. 为什么噪声会变成“价值幻觉”
过高估计不是一次无害的误差。
在 Q-Learning 中,它会进入 TD Target:
$$y_t = r_t +\gamma \max_{a'} Q(s_{t+1},a')$$
如果下一状态最大价值被高估:
- 当前 TD Target 偏高;
- 当前动作价值被向上推;
- 更早状态又使用这个偏高价值;
- 偏差沿自举链传播。
更麻烦的是,策略会优先选择高估动作。
于是系统形成循环:
偶然高估
→ 更容易被选择
→ 更频繁进入更新
→ 偏差传播
→ 策略更加相信高估动作
这种现象可以称为“价值幻觉”:
智能体不是发现了真正更好的动作,而是越来越相信自己早期的乐观误判。
5. 从 Q-Learning 到 DQN
如果状态数量很少,可以用表格存储:
$$Q(s,a)$$
但图像、机器人姿态、游戏画面和语言上下文空间极其庞大,无法逐项存表。
DQN 使用神经网络近似动作价值:
$$Q_\theta(s,a)$$
其中:
| 符号 | 含义 |
|---|---|
θ |
神经网络参数 |
Q_θ(s,a) |
网络对状态动作价值的估计 |
最直接的 DQN Target 为:
$$y_t = r_t +\gamma \max_{a'} Q_\theta(s_{t+1},a')$$
对应损失:
$$L(\theta)= \frac{1}{2} [ y_t -Q_\theta(s_t,a_t) ]^2$$
但这里有一个问题:
- 当前预测来自
Q_θ; - 目标也来自
Q_θ。
网络每更新一次,目标也立即变化。
这像一个射手一边瞄准,一边自己移动靶子。
6. Target Network:让靶子暂时慢下来
DQN 引入目标网络:
$$Q_{\theta^-}(s,a)$$
其中:
θ是当前在线网络参数;θ^-是目标网络参数。
TD Target 改为:
$$y_t^{DQN} = r_t +\gamma \max_{a'} Q_{\theta^-}(s_{t+1},a')$$
这里为简洁起见,省略了终止标记。若用 $d_t\in{0,1}$ 表示这一步之后是否终止,工程实现通常写成:
$$y_t^{DQN} = r_t +\gamma(1-d_t)\max_{a'} Q_{\theta^-}(s_{t+1},a')$$
终止转移满足 $d_t=1$,不应继续叠加下一状态价值。
Loss 为:
$$L_{\mathrm{DQN}}(\theta)= \frac{1}{2} [ y_t^{DQN} -Q_\theta(s_t,a_t) ]^2$$
在线网络持续更新,目标网络暂时固定。
每隔一段时间,再同步:
$$\theta^- \leftarrow \theta$$
或者使用软更新:
$$\theta^- \leftarrow \tau\theta +(1-\tau)\theta^-$$
其中:
| 符号 | 含义 |
|---|---|
θ |
在线网络参数 |
θ^- |
目标网络参数 |
τ |
软更新比例,通常较小 |
Target Network 解决的不是奖励问题,也不是探索问题。
它解决的是:
自举目标变化太快,网络难以追踪。
它像一个锚点,让递归更新暂时稳定一点。
7. Replay Buffer:为什么要复用旧经验
DQN 还使用 Replay Buffer,保存历史转移:
$$(s_t,a_t,r_t,s_{t+1})$$
训练时,从缓冲区随机采样。
Replay Buffer 有两个主要作用:
- 打散连续时间步之间的强相关性;
- 复用旧经验,提高样本效率。
如果智能体刚刚连续走过同一片区域,直接按顺序训练,样本会高度相似。随机回放可以让 batch 更加多样。
但 Replay Buffer 也引入新问题:
旧数据来自旧策略,与当前策略的分布并不完全一致。
因此,Replay Buffer 同时属于:
- 数据复用机制;
- 稳定化机制;
- Off-Policy 学习的一部分;
- 潜在分布漂移来源。
它不是一块没有代价的存储空间。
8. Double DQN:选择与评价不要使用同一双眼睛
Target Network 减缓目标漂移,但最大化偏差仍然存在。
标准 DQN Target 使用:
$$\max_{a'} Q_{\theta^-}(s_{t+1},a')$$
同一个网络既:
- 选择哪个动作最大;
- 评价这个最大动作值多少。
如果某个动作被偶然高估,它更容易被选中,也更容易将高估值写入目标。
Double DQN 将“选择”与“评价”分开。
先用在线网络选择动作:
$$a^* = \arg\max_{a'} Q_\theta(s_{t+1},a')$$
再用目标网络评价这个动作:
$$Q_{\theta^-} ( s_{t+1},a^* )$$
因此,Double DQN Target 为:
$$y_t^{DoubleDQN} = r_t +\gamma Q_{\theta^-} ( s_{t+1}, \arg\max_{a'} Q_\theta(s_{t+1},a'))$$
逐项解释:
| 步骤 | 使用哪个网络 | 作用 |
|---|---|---|
| 选择动作 | 在线网络 Q_θ |
判断下一步选哪个动作 |
| 评价动作 | 目标网络 Q_{θ^-} |
判断这个动作价值多少 |
Double DQN 的直觉非常朴素:
不要让同一份噪声同时决定“选谁”和“给多少分”。
它不能彻底消除所有偏差,但通常能够缓解过高估计。
9. Dueling Network:状态好不好,与动作差异有多大
有些状态下,不同动作差别很小。
例如,一辆车在空旷直路上,轻微向左或向右调整都可能影响不大。此时,与其为每个动作完全独立估计价值,不如分开建模:
- 当前状态总体有多好;
- 每个动作相对平均水平有多大优势。
Dueling Network 使用:
$$Q(s,a)= V(s)+A(s,a)$$
但直接相加存在不可辨识问题。常见修正为:
$$Q(s,a)= V(s)+ [ A(s,a)- \frac{1}{|\mathcal{A}|} \sum_{a'} A(s,a') ]$$
其中:
| 符号 | 含义 |
|---|---|
V(s) |
状态整体价值 |
A(s,a) |
动作相对优势 |
|A| |
动作数量 |
| 平均 Advantage | 用于固定分解基准 |
Dueling Network 主要改变网络结构,不是重新定义 Bellman 目标。
10. Prioritized Replay:哪些经验更值得重看
普通 Replay Buffer 随机采样旧经验。
但一些经验可能更有学习价值。例如,TD Error 较大的样本说明:
当前预测与新证据差异较大。
可以定义优先级:
$$p_i = | \delta_i | +\varepsilon$$
并按优先级采样:
$$P(i) = \frac{ p_i^\alpha}{ \sum_j p_j^\alpha}$$
其中:
| 符号 | 含义 |
|---|---|
δ_i |
第 i 条经验的 TD Error |
ε |
保证每条经验仍有机会被采样 |
α |
控制优先级强度 |
P(i) |
第 i 条经验被采样的概率 |
优先回放提高学习效率,却改变了采样分布。
为了减少偏差,还需要 Importance Sampling 修正。
这再次说明:
每一次效率提升,往往会把新的代价转移到别处。
11. Distributional RL:价值不只是一个平均数
标准价值函数通常估计期望:
$$Q(s,a) = \mathbf{E} [ G_t \mid s,a ]$$
但两个动作即使期望相同,风险结构也可能不同。
例如:
- 动作 A:稳定得到
5; - 动作 B:一半概率得到
20,一半概率得到-10。
两者期望都是:
$$5$$
但回报分布不同。
Distributional RL 尝试建模回报随机变量的分布:
$$Z(s,a)$$
而不是只估计均值:
$$Q(s,a)=\mathbf{E}[Z(s,a)]$$
这提醒我们:
价值幻觉不仅可能来自均值高估,也可能来自把复杂风险压缩成一个数字。
12. 边界:Target Network 不是万能药
Target Network、Double DQN、Replay Buffer、Dueling Network 与 Prioritized Replay 都很有用。
但它们分别处理不同问题:
| 方法 | 主要处理的问题 |
|---|---|
| Target Network | 目标漂移过快 |
| Replay Buffer | 样本相关性与复用效率 |
| Double DQN | 最大化偏差 |
| Dueling Network | 状态价值与动作优势的结构分解 |
| Prioritized Replay | 样本利用效率 |
| Distributional RL | 回报分布信息 |
不能把这些机制都笼统理解为“让 DQN 更稳定”。
真正重要的是看清:
每一种机制压住了哪一个循环,又把什么新问题带入系统。
13. 回归全景图(Callback):DQN 与 Double DQN
| 坐标轴 | DQN 如何处理 | Double DQN 增加了什么 |
|---|---|---|
| 目标 | 逼近最优长期动作价值 | 目标不变 |
| 时间 | 使用 Bellman 最优方程与自举 | 目标不变 |
| 更新 | 最小化 TD Loss | 将动作选择与动作评价分离 |
| 估计 | 神经网络估计 Q 值,Target Network 减缓目标漂移 | 缓解 max 偏爱高估值的问题 |
| 数据 | Replay Buffer 复用旧经验 | 数据机制不变 |
| 探索 | 通常使用 ε-greedy 采集经验 |
探索机制不变 |
DQN 没有消灭价值估计的误差。它通过 Target Network 和 Replay Buffer 让自举更可控。Double DQN 则进一步承认:当选择与评价共享同一份噪声时,最大化会系统性放大乐观误判。
14. 本章小结
Q-Learning 使用:
$$Q(s_t,a_t)\leftarrow Q(s_t,a_t)+\alpha [ r_t +\gamma \max_{a'} Q(s_{t+1},a')-Q(s_t,a_t) ]$$
但 max 会偏爱带有正向噪声的动作。
DQN 使用神经网络近似价值,并通过目标网络稳定训练:
$$y_t^{DQN} = r_t +\gamma \max_{a'} Q_{\theta^-}(s_{t+1},a')$$
Double DQN 将选择与评价分开:
$$y_t^{DoubleDQN} = r_t +\gamma Q_{\theta^-} ( s_{t+1}, \arg\max_{a'} Q_\theta(s_{t+1},a'))$$
下一章继续追问:
当函数逼近、自举和 Off-Policy 数据同时出现时,为什么误差可能不只是偏高,而是彻底失控?
第 9 章:致命三角:为什么深度 RL 容易失控
1. 单独看都合理,组合起来却可能危险
前几章出现了三种常见做法。
第一,使用神经网络表示价值函数。状态空间太大,不可能为每个状态单独存表,因此需要函数逼近。
第二,使用自举。等待完整轨迹太慢,因此用下一状态价值估计更新当前价值。
第三,复用旧数据。环境交互很昂贵,因此希望使用 Replay Buffer 或其他策略采集的数据提高样本效率。
每一种做法单独看都很合理。
但当三者同时出现时,训练可能变得非常脆弱:
- Function Approximation:函数逼近;
- Bootstrapping:自举;
- Off-Policy Learning:异策略学习。
这三者的组合通常被称为致命三角(Deadly Triad)。
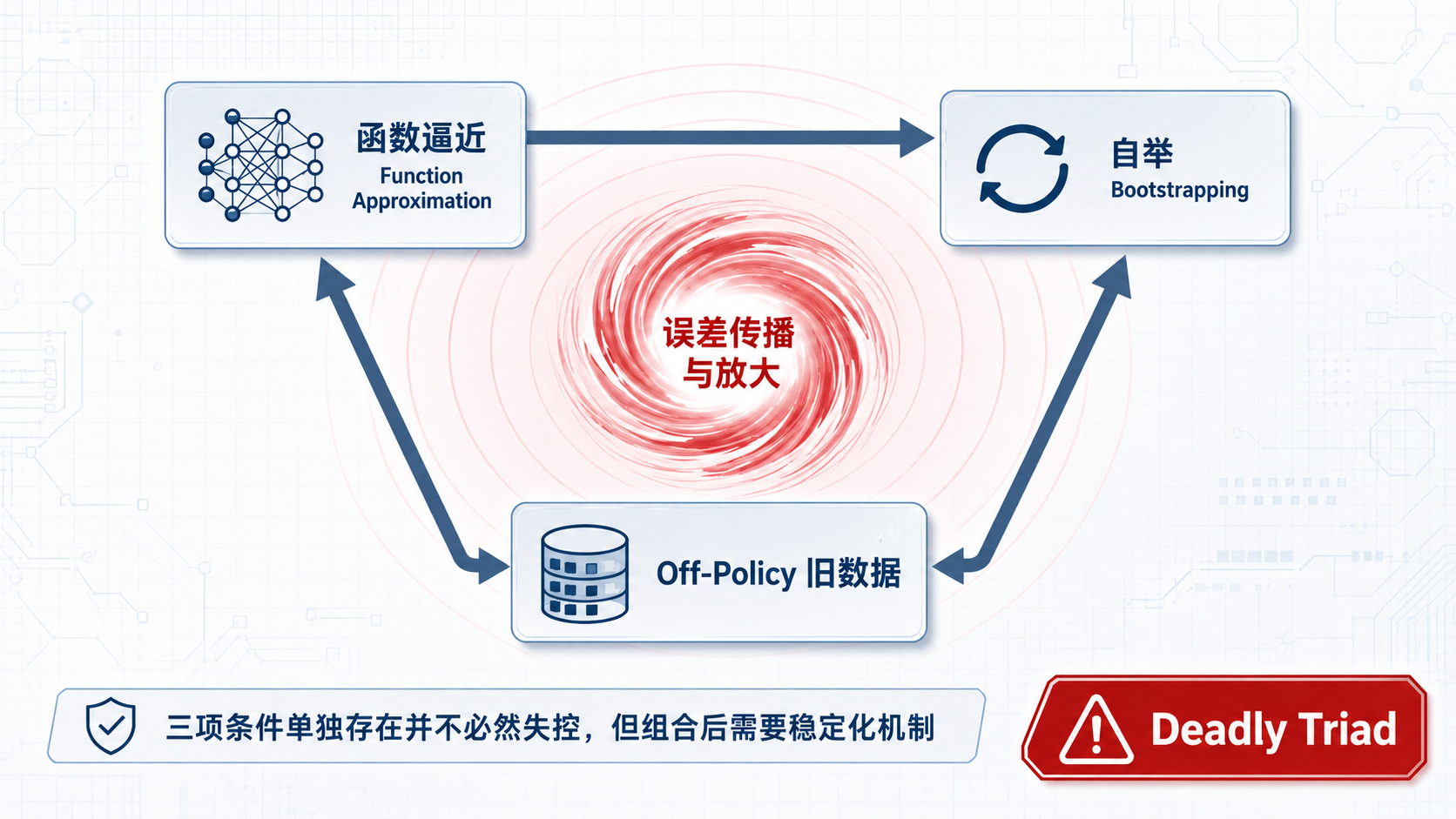
图 9-1:致命三角的误差传播
2. 顶点一:函数逼近
在表格型强化学习中,每个状态动作对都有独立数值:
$$Q(s,a)$$
更新一个状态动作对,不一定影响其他位置。
神经网络不同。
我们用:
$$Q_\theta(s,a)$$
表示动作价值。参数 θ 被大量状态共享。
一次梯度更新:
$$\theta \leftarrow \theta -\alpha \nabla_\theta L(\theta)$$
会同时改变许多状态动作对的预测。
这带来泛化能力,也带来干扰。
如果网络在状态 s_1 上学到了一点新东西,状态 s_2 的估计也可能变化,即使 s_2 并未出现在当前 batch 中。
函数逼近让学习不再局部。
3. 顶点二:自举
TD Target 包含下一状态估计:
$$y_t = r_t +\gamma \max_{a'} Q_{\theta^-}(s_{t+1},a')$$
当前价值学习目标不是静态标签,而是另一个估计。
如果下一状态价值偏高,当前价值也会被推高。
自举让学习更高效,也让误差可以沿时间传播:
下一状态误差
→ 当前 Target 误差
→ 当前价值误差
→ 更早状态 Target 误差
4. 顶点三:Off-Policy
On-Policy 学习使用当前策略采集的数据。
Off-Policy 学习则允许:
用行为策略
b产生的数据,学习另一个目标策略π。
写作:
$$b\neq\pi$$
这非常有吸引力。
旧经验可以反复利用;其他智能体的数据也可能被使用;昂贵环境交互不必浪费。
但风险是:
数据覆盖的区域,与当前策略真正关心的区域可能不同。
如果模型在某些动作上几乎没有数据,却仍然给出很高估计,策略可能被吸引到这些缺少证据的区域。
这类问题常与外推误差(extrapolation error)有关。
5. 三者如何形成反馈循环
现在将三个顶点连接起来。
假设网络在一个缺少数据的动作上偶然高估:
$$Q_\theta(s,a) \mathrm{ 偏高}$$
由于自举,偏高值进入目标:
$$y_t = r_t +\gamma \max_{a'} Q_{\theta^-}(s',a')$$
由于函数逼近,一次更新又可能改变其他状态估计。
由于数据来自旧策略,当前 buffer 未必包含足够新样本纠正错误。
于是:
缺少覆盖的数据
→ 某些价值估计偏离现实
→ 自举把误差写入新的 Target
→ 神经网络把局部误差传播到更多状态
→ 策略与数据分布进一步变化
→ 原有数据更难纠正新误差
误差不再只是一个点上的小偏差,而可能形成正反馈。
6. Semi-Gradient 为什么既必要又危险
TD Loss 常写为:
$$L(\theta)= \frac{1}{2} [ y_t -Q_\theta(s_t,a_t) ]^2$$
其中:
$$y_t = r_t +\gamma \max_{a'} Q_{\theta^-}(s_{t+1},a')$$
目标一侧通常停止梯度,或使用较慢更新的目标网络。
这样做避免预测与目标同时剧烈移动。
但它也意味着:
更新更像是在追踪一个不断变化的固定点,而不是最小化一个永远静止的监督学习目标。
当数据分布、目标网络和在线网络同时变化时,训练曲线可能很难解释。
Loss 短期下降,不代表长期目标一定改善。
7. 一个重要区别:数值稳定不等于策略正确
训练不发散当然重要。
但稳定只是第一步。
一个算法可能:
- Loss 平稳下降;
- 梯度没有爆炸;
- Q 值范围正常;
- 回报曲线看起来缓慢上升;
却仍然学到错误策略。
原因可能包括:
- 奖励代理设计错误;
- 数据覆盖不足;
- 探索不够;
- 价值估计在关键区域失真;
- 环境变化;
- 测试分布不同。
因此,需要区分:
| 概念 | 含义 |
|---|---|
| 数值稳定 | 训练过程没有明显爆炸或崩溃 |
| 估计可靠 | 价值预测在关键区域足够准确 |
| 策略有效 | 智能体确实取得更好长期结果 |
| 目标正确 | 奖励提升真正代表真实意图改善 |
这些条件彼此相关,但不能混为一谈。
8. DQN 的稳定化机制在压住什么
DQN 不是靠单一公式工作,而是依赖多种稳定化机制。
8.1 Replay Buffer
作用:
- 打散时间相关性;
- 提高样本复用率;
- 增加 batch 多样性。
代价:
- 数据来自旧策略;
- 分布可能过时。
8.2 Target Network
作用:
- 减慢目标变化;
- 降低在线网络追逐自身预测的速度。
代价:
- 目标更稳定,但也更陈旧;
- 同步频率需要权衡。
8.3 Double DQN
作用:
- 分离动作选择与动作评价;
- 缓解最大化偏差。
代价:
- 不能消除所有估计错误;
- 仍然依赖网络与数据覆盖。
这些机制并没有推翻 Bellman 方程,而是在给反馈循环增加阻尼。
9. 为什么 PPO 也强调限制更新幅度
致命三角最常用于解释价值方法,但背后的系统直觉更广泛:
当策略、数据和估计器互相影响时,一次过大的更新可能改变下一轮学习条件。
PPO 使用概率比率:
$$r_t(\theta)= \frac{ \pi_\theta(a_t\mid s_t)}{ \pi_{\theta_{\mathrm{old}}}(a_t\mid s_t)}$$
并通过 Clip 限制更新不要走得太远。
RLHF 中的 KL 惩罚也有类似目的:
$$D_{\mathrm{KL}} ( \pi_\theta \parallel \pi_{\mathrm{ref}} )$$
它们不是在修复同一个数学细节,却体现了共同工程哲学:
当系统处在反馈循环中,更新步幅本身就是安全装置。
10. Offline RL 为什么更加敏感
Offline RL 使用固定数据集训练策略。
智能体不能随时回到环境中采集新数据纠正错误。
假设数据集几乎没有包含某个动作:
$$a_{\mathrm{rare}}$$
模型却因为函数逼近误差高估它:
$$Q(s,a_{\mathrm{rare}}) \mathrm{ 很高}$$
策略可能越来越倾向于选择这个动作。
但数据集又没有足够证据验证它。
这就是分布外动作带来的风险。
Offline RL 常采用保守估计,避免策略过度相信数据集中缺少覆盖的区域。
第 11 章讨论 On-Policy 与 Off-Policy 时会进一步展开。
11. 诊断训练时应该看什么
只看平均回报通常不够。
工程中还需要观察:
- Q 值或 V 值是否持续膨胀;
- TD Error 分布是否异常;
- 梯度范数是否爆炸;
- 新旧策略 KL 是否突然变大;
- Replay Buffer 中数据是否过时;
- 训练回报与评估回报是否分离;
- 不同随机种子结果是否差异巨大;
- 分布外状态上价值估计是否异常乐观。
这些指标不是为了制造更多仪表盘,而是为了回答:
反馈循环究竟在哪一个位置开始失控?
12. 边界:致命三角不是一句万能解释
训练不稳定时,把所有问题都归结为“致命三角”也不准确。
系统还可能因为以下原因失败:
- 奖励尺度不合理;
- 状态归一化错误;
- 终止状态处理错误;
- 探索不足;
- 学习率过高;
- 神经网络结构不适合;
- 实现中的 mask 或 batch 逻辑错误;
- 评估流程泄漏。
致命三角提供的是一种系统级视角:
当函数逼近、自举和 Off-Policy 同时存在时,需要对误差传播保持高度警惕。
它不是排除其他故障的借口。
13. 回归全景图(Callback)
| 坐标轴 | 致命三角如何进入全景图 | 尚未解决什么 |
|---|---|---|
| 目标 | 仍然优化长期回报 | 奖励代理是否可靠 |
| 时间 | 自举让误差沿时间回传 | 如何限制长链传播 |
| 更新 | Semi-Gradient、Target Network、Clip、KL 为更新增加阻尼 | 阻尼强度如何选择 |
| 估计 | 函数逼近让局部误差影响更多状态 | 如何判断关键区域估计可靠 |
| 数据 | Off-Policy 复用旧数据,也带来覆盖差异 | 如何处理分布外状态与动作 |
| 探索 | 探索决定数据覆盖 | 如何既覆盖未知,又避免危险区域 |
致命三角没有告诉我们停止使用函数逼近、自举或旧数据。它告诉我们:三种效率工具叠加后,系统已经进入反馈控制问题,必须主动增加稳定机制。
14. 本章小结
致命三角由三部分组成:
函数逼近 + 自举 + Off-Policy
函数逼近让一次更新影响大量状态。
自举让估计误差进入新的训练目标。
Off-Policy 让训练数据与当前策略关心的分布出现差异。
三者结合后,小误差可能沿循环放大。
下一部分,我们将专门讨论数据:
为什么强化学习最反直觉的地方之一,是学习者每更新一次,下一轮学习所面对的数据也随之改变?
第五部分:学习者改变了自己的数据
第 10 章:非平稳性:在移动的地面上学习
1. 学会一点,世界就变一点
监督学习通常假设训练数据来自某个相对固定的分布。
模型今天更新一次参数,明天数据集里的图片不会因此改变。猫仍然是猫,狗仍然是狗。
强化学习不同。
策略决定智能体去哪里、做什么、看到什么。策略一旦变化,下一批经验也会变化。
一个游戏智能体学会避开危险区域后,Replay Buffer 中会逐渐减少危险区域的新样本。一个推荐系统更加偏好某类内容后,用户看到的内容结构也会改变。一个语言模型经过偏好优化后,生成风格改变,Reward Model 接收到的输入分布也随之变化。
因此:
强化学习不是在固定数据集上学习,而是在自己不断改造的数据流上学习。
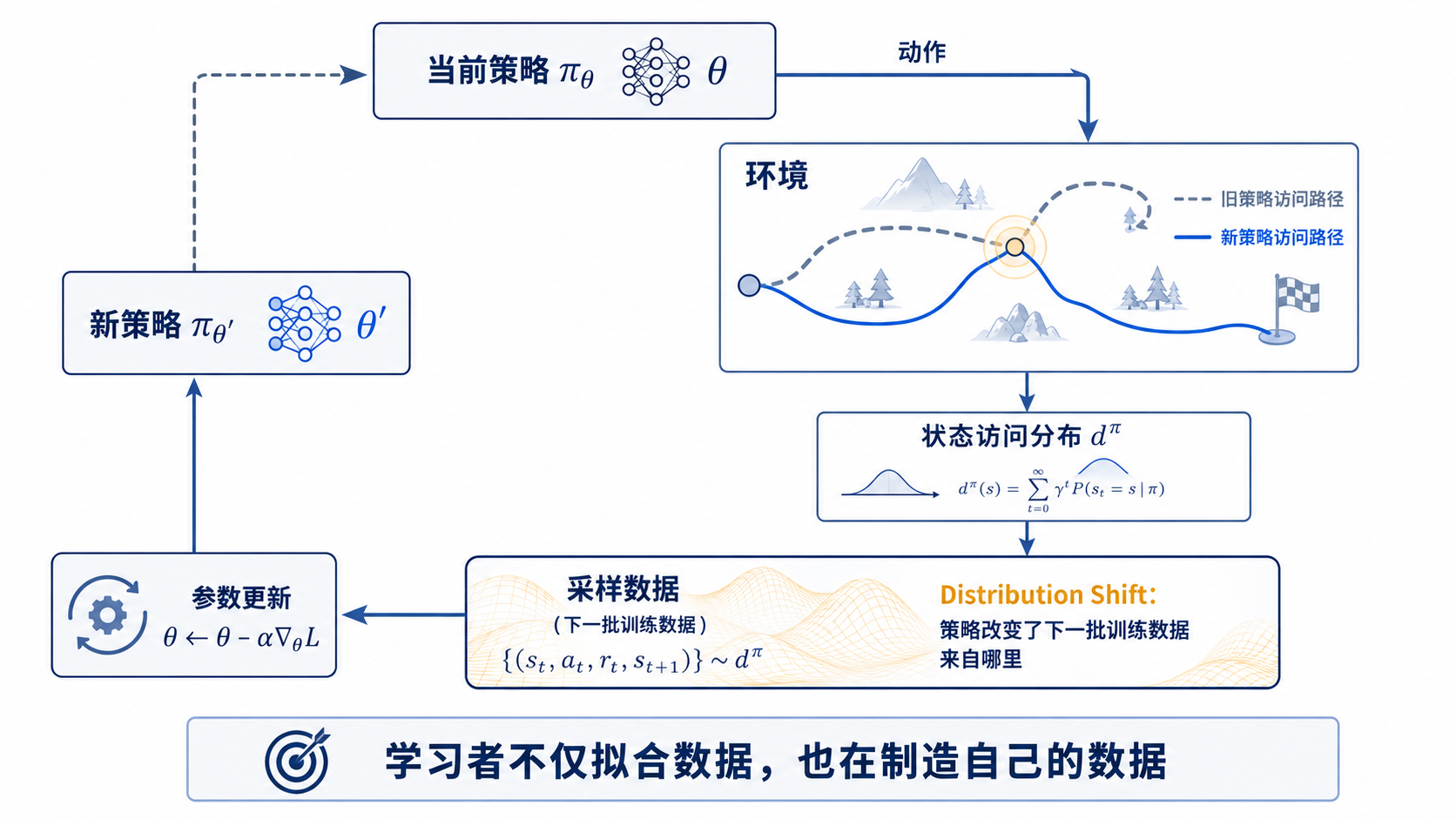
图 10-1:策略更新导致数据分布漂移
2. 状态访问分布
策略:
$$\pi(a\mid s)$$
不仅决定当前动作,也间接决定未来会访问哪些状态。
可以定义折扣状态访问分布:
$$d^\pi(s)= (1-\gamma)\sum_{t=0}^{\infty} \gamma^t P(S_t=s\mid\pi)$$
逐项解释:
| 符号 | 含义 |
|---|---|
d^π(s) |
策略 π 下访问状态 s 的折扣权重 |
P(S_t=s|π) |
遵循策略 π 时,第 t 步处于状态 s 的概率 |
γ^t |
越遥远时间步权重越小 |
1-γ |
归一化因子,使总权重便于解释为分布 |
状态动作访问分布可以写成:
$$d^\pi(s,a)= d^\pi(s)\pi(a\mid s)$$
它表示:
遵循策略
π时,状态动作对(s,a)被访问到的频率结构。
这条公式很重要。
当策略从:
$$\pi_{\mathrm{old}}$$
更新为:
$$\pi_{\mathrm{new}}$$
状态访问分布也可能变化:
$$d^{\pi_{\mathrm{old}}}(s,a)\neq d^{\pi_{\mathrm{new}}}(s,a)$$
数据分布不是背景条件,而是策略的一部分后果。
3. 一个迷宫例子
假设迷宫中有两片区域:
- 左侧区域安全,但奖励较低;
- 右侧区域风险更高,但可能找到更大奖励。
训练初期,策略接近随机。智能体会同时访问左右两侧。
随着学习推进,策略发现左侧更容易获得稳定回报,于是越来越少进入右侧。
这时,右侧区域的数据逐渐稀缺。
如果右侧深处其实存在更优路径,智能体也可能永远无法发现。
这里同时出现三个问题:
- 策略改变状态访问分布;
- 数据不足限制价值估计;
- 探索不足锁定局部最优。
这说明数据问题与探索问题天然相连。
4. 两种不同的非平稳性
“非平稳”经常被笼统使用,但至少要区分两类。
4.1 环境本身变化
例如:
- 用户兴趣随季节变化;
- 金融市场结构变化;
- 其他智能体改变策略;
- 机器人硬件磨损;
- 线上产品规则更新。
可以写成:
$$P_t(s',r\mid s,a)\neq P_{t+1}(s',r\mid s,a)$$
环境动力学本身随时间变化。
4.2 策略诱导的数据漂移
即使环境完全不变,策略更新也会改变数据分布:
$$\pi_{\mathrm{old}} \to \pi_{\mathrm{new}} \Rightarrow d^{\pi_{\mathrm{old}}} \to d^{\pi_{\mathrm{new}}}$$
环境规则没有变化,但智能体走过的路径变化了。
本章主要讨论第二类。
它是强化学习内生的非平稳性:
学习本身改变了下一轮学习所依赖的数据。
5. 自我更新循环
将过程写成闭环:
当前策略
→ 采取动作
→ 访问特定状态
→ 收集新数据
→ 估计价值或优势
→ 更新参数
→ 新策略
→ 访问新的状态分布
这就是序章中的自我更新循环。
监督学习更接近:
固定数据集
→ 更新模型
→ 仍然使用同一数据分布
强化学习则是:
策略
→ 生成数据
→ 数据更新策略
→ 新策略生成新数据
因此,训练稳定性不能只看优化器本身。
还要看策略改变数据的速度。
6. 为什么旧数据既宝贵又危险
旧经验很宝贵。
环境交互通常昂贵。如果机器人真实摔倒一次、线上系统展示一次内容、语言模型生成一批长回答,都要付出成本。
因此,我们希望复用转移样本:
$$(s_t,a_t,r_t,s_{t+1})$$
但旧数据来自旧策略:
$$\pi_{\mathrm{old}}$$
当前希望优化的是:
$$\pi_{\mathrm{new}}$$
两者可能不同。
如果差异很小,旧数据仍然有帮助。
如果差异很大,旧数据可能无法代表当前策略真正会访问的区域。
于是产生张力:
| 目标 | 代价 |
|---|---|
| 多复用旧数据 | 样本效率提高,但分布偏差增加 |
| 只使用新数据 | 分布更加一致,但成本更高 |
这将引出下一章:On-Policy 与 Off-Policy。
7. 语言模型后训练中的分布漂移
大模型后训练同样处在自我更新循环中。
假设初始模型为:
$$\pi_{\mathrm{ref}}$$
经过若干轮优化后,得到:
$$\pi_\theta$$
模型生成回答的分布会变化:
$$y \sim \pi_{\mathrm{ref}}(\cdot\mid x)$$
变为:
$$y \sim \pi_\theta(\cdot\mid x)$$
如果 Reward Model 主要在旧模型回答上训练,它面对新模型产生的回答时,可能进入分布外区域。
模型越擅长优化 Reward Model,越可能找到 Reward Model 不可靠的角落。
这就是为什么 RLHF 常加入 KL 约束:
$$D_{\mathrm{KL}} ( \pi_\theta \parallel \pi_{\mathrm{ref}} )$$
KL 不只是“保持语言风格”。
它还在限制分布漂移速度,避免策略一步跑到评价器缺少经验的区域。
8. 数据覆盖:没有访问,就很难知道
假设状态空间中有一片区域:
$$\mathcal{S}_{\mathrm{unseen}}$$
策略很少访问这里:
$$d^\pi(s)\approx0, \quad s\in\mathcal{S}_{\mathrm{unseen}}$$
那么价值网络在这片区域的输出主要依赖函数逼近的外推,而不是充足数据。
它可能给出任意估计。
如果策略随后被这些乐观估计吸引,就可能进入危险区域。
这在 Offline RL 中尤其突出,因为智能体无法随时回到环境中采集新数据纠正错误。
覆盖问题可以用一句话概括:
对从未认真看过的世界,模型仍然可以给出答案,但不一定值得相信。
9. 为什么更新不能太快
策略更新太快,会同时带来两种变化:
- 动作概率突变;
- 状态访问分布突变。
旧数据迅速过时,价值估计器来不及适应,新策略又继续生成更不同的数据。
因此,许多算法会限制更新幅度。
PPO 使用概率比率:
$$r_t(\theta)= \frac{ \pi_\theta(a_t\mid s_t)}{ \pi_{\theta_{\mathrm{old}}}(a_t\mid s_t)}$$
KL 约束则衡量新旧策略分布差异:
$$D_{\mathrm{KL}} ( \pi_\theta \parallel \pi_{\mathrm{old}} )$$
这些机制体现同一个工程判断:
数据分布会随着策略变化,因此策略不能在一次更新中跑得太远。
10. Replay Buffer 的时间尺度
Replay Buffer 中的数据越多,覆盖可能越广。
但数据也可能越旧。
假设 buffer 包含多个历史策略的数据:
$$\mathcal{D} = \bigcup_{k=1}^{K} \mathcal{D}_{\pi_k}$$
其中:
| 符号 | 含义 |
|---|---|
D_{π_k} |
策略 π_k 采集的数据 |
D |
历史经验集合 |
一个大 buffer 像一座经验仓库。
优点:
- 打散时间相关性;
- 保存低频经验;
- 提高样本复用率。
风险:
- 新旧策略混杂;
- 旧数据比例过高;
- 当前策略关心的区域覆盖不足;
- 环境变化后历史经验过时。
因此,Replay Buffer 也需要考虑时间尺度。
11. 边界:数据漂移不是错误,而是系统特征
数据分布变化并不一定意味着算法出错。
一个真正学习成功的智能体,本来就应该改变行为。
机器人学会走路后,摔倒数据会减少。游戏智能体学会规避危险后,危险区域访问会变化。语言模型学会更好回答后,生成分布也应变化。
问题不是消灭漂移,而是管理漂移。
需要问:
- 数据变化速度是否超过估计器适应速度?
- 旧数据是否仍然适用?
- 新策略是否进入缺少覆盖的区域?
- 评价器是否能可靠评价新分布?
- 探索是否仍然足够?
非平稳性不是附属问题,而是强化学习的运行方式。
12. 回归全景图(Callback)
| 坐标轴 | 非平稳性如何进入全景图 | 尚未解决什么 |
|---|---|---|
| 目标 | 策略仍然追求长期回报 | 奖励与评价器在新分布上是否可靠 |
| 时间 | 轨迹将策略影响延伸到未来状态 | 长期漂移如何累积 |
| 更新 | 参数更新改变策略,策略改变下一批样本 | 更新步幅应限制到什么程度 |
| 估计 | 价值网络可能在缺少覆盖的区域外推 | 如何识别不可靠估计 |
| 数据 | d^π(s,a) 随策略变化,旧数据既有价值又可能过时 |
On-Policy 与 Off-Policy 如何取舍 |
| 探索 | 探索决定覆盖范围 | 如何避免探索不足与危险探索 |
非平稳性不是一个等待修复的异常,而是强化学习的基本事实:学习者改变行为,行为改变数据,数据再次塑造学习者。
13. 本章小结
策略不仅决定动作,还决定数据分布。
折扣状态访问分布为:
$$d^\pi(s)= (1-\gamma)\sum_{t=0}^{\infty} \gamma^t P(S_t=s\mid\pi)$$
状态动作访问分布为:
$$d^\pi(s,a)= d^\pi(s)\pi(a\mid s)$$
策略变化后:
$$d^{\pi_{\mathrm{old}}} \neq d^{\pi_{\mathrm{new}}}$$
下一章将进入一个经典分叉:
应该只使用当前策略的新数据,还是允许复用其他策略留下的旧经验?
第 11 章:On-Policy 与 Off-Policy:旧经验还能用吗
1. 用昨天的经验训练今天的自己
假设一个机器人昨天还走得摇摇晃晃。
今天,它已经学会更稳定的步态。
昨天收集的大量经验还能不能继续训练今天的策略?
如果全部丢弃,交互成本很高。如果全部保留,旧经验又可能不再代表今天真正会遇到的状态。
这就是 On-Policy 与 Off-Policy 的分叉。
它不是一个术语分类游戏,而是在回答:
我们愿意为样本复用支付多少分布偏差?
2. 行为策略与目标策略
先区分两个策略。
行为策略(behavior policy)记为:
$$b(a\mid s)$$
它负责实际采集数据。
目标策略(target policy)记为:
$$\pi(a\mid s)$$
它是我们真正想评价或优化的策略。
如果:
$$b=\pi$$
数据由当前目标策略自己产生,称为 On-Policy。
如果:
$$b\neq\pi$$
使用另一个策略的数据学习目标策略,称为 Off-Policy。
3. On-Policy:数据新鲜,但价格昂贵
On-Policy 方法使用当前策略采集的数据更新当前策略。
过程可以写成:
当前策略 π
→ 采集新轨迹
→ 使用这些轨迹更新 π
→ 丢弃或弱化旧轨迹
→ 使用新策略继续采样
优点:
- 数据与当前策略匹配;
- 分布关系更清晰;
- 理论分析通常更直接。
代价:
- 旧数据很快过时;
- 样本利用率较低;
- 环境交互成本高。
PPO 通常被视为 On-Policy 方法。虽然一批数据可能被重复训练若干 epoch,但更新幅度受到限制,数据不会无限期复用。
4. Off-Policy:经验复用,但需要缴税
Off-Policy 方法允许使用旧策略或其他策略的数据。
过程可以写成:
行为策略 b 采集数据
→ 保存经验
→ 目标策略 π 使用这些数据学习
优点:
- 样本复用率高;
- 可以使用 Replay Buffer;
- 可以利用其他来源的数据;
- 更适合昂贵环境交互。
代价:
- 数据分布与当前策略不一致;
- 估计可能带偏;
- 分布外动作风险更高;
- 修正机制可能产生高方差。
Q-Learning、DQN、DDPG、TD3 和 SAC 都常采用 Off-Policy 数据。
5. SARSA 与 Q-Learning:一个关键分叉
SARSA 与 Q-Learning 的差异非常适合建立直觉。
5.1 SARSA
SARSA 更新为:
$$Q(s_t,a_t)\leftarrow Q(s_t,a_t)+\alpha [ r_t +\gamma Q(s_{t+1},a_{t+1})-Q(s_t,a_t) ]$$
其中,下一动作:
$$a_{t+1} \sim \pi(\cdot\mid s_{t+1})$$
SARSA 使用策略实际会采取的下一动作。
它学习:
按照当前行为继续走,长期价值是多少?
5.2 Q-Learning
Q-Learning 更新为:
$$Q(s_t,a_t)\leftarrow Q(s_t,a_t)+\alpha [ r_t +\gamma \max_{a'} Q(s_{t+1},a')-Q(s_t,a_t) ]$$
它不使用实际采样的下一动作,而是使用估计最优动作。
它学习:
即使采样时带有探索,未来如果选择最优动作,长期价值是多少?
SARSA 更贴近当前行为策略。
Q-Learning 则可以一边用探索策略采样,一边学习贪心目标策略。
这就是经典 Off-Policy 思想。
6. Importance Sampling:怎样修正分布差异
假设数据来自行为策略:
$$b(a\mid s)$$
但我们想估计目标策略:
$$\pi(a\mid s)$$
可以使用重要性采样比率:
$$\rho_t = \frac{ \pi(a_t\mid s_t)}{ b(a_t\mid s_t)}$$
逐项解释:
| 符号 | 含义 |
|---|---|
ρ_t |
当前动作的重要性权重 |
π(a_t|s_t) |
目标策略选择该动作的概率 |
b(a_t|s_t) |
行为策略实际采集该动作的概率 |
如果:
$$\rho_t>1$$
说明目标策略比行为策略更重视这个动作,样本权重应提高。
如果:
$$\rho_t<1$$
说明目标策略较少选择这个动作,样本权重应降低。
对于一段轨迹,权重可能连乘:
$$\rho_{t:T-1} = \prod_{k=t}^{T-1} \frac{ \pi(a_k\mid s_k)}{ b(a_k\mid s_k)}$$
这能修正分布,却可能产生新问题。
如果某一步:
$$b(a_k\mid s_k)$$
很小,而:
$$\pi(a_k\mid s_k)$$
较大,权重会非常大。
长轨迹连乘后,方差可能爆炸。
7. 手算一次 Importance Sampling
假设在某个状态:
$$b(a_1\mid s)=0.2$$
目标策略为:
$$\pi(a_1\mid s)=0.6$$
那么:
$$\rho = \frac{0.6}{0.2} =3$$
这条样本在目标策略下更重要,因此权重放大为 3。
如果另一个动作:
$$b(a_2\mid s)=0.8$$
$$\pi(a_2\mid s)=0.4$$
那么:
$$\rho = \frac{0.4}{0.8} =0.5$$
样本权重降低。
Importance Sampling 的思想朴素:
数据虽然来自别的策略,但可以按“目标策略有多重视这条样本”重新加权。
8. Coverage:分母不能为零
Importance Sampling 有一个重要前提:
行为策略必须覆盖目标策略可能选择的动作。
如果:
$$b(a\mid s)=0$$
但:
$$\pi(a\mid s)>0$$
那么:
$$\frac{ \pi(a\mid s)}{ b(a\mid s)}$$
无法计算。
更重要的是,数据中根本没有这种动作的经验。
这不是数学技巧能够弥补的。
Coverage 问题可以概括为:
没有见过的行为,无法仅靠重新加权获得可靠知识。
9. Clipping:不要让少数样本支配更新
由于 Importance Sampling 权重可能很大,常见做法是截断:
$$\bar{\rho}_t = \min ( c,\rho_t )$$
其中:
| 符号 | 含义 |
|---|---|
ρ_t |
原始重要性权重 |
c |
最大允许权重 |
ρ̄_t |
截断后的权重 |
截断降低方差,却引入偏差。
这再次回到上一章:
没有免费的估计。稳定与准确之间总有取舍。
PPO Clip 虽然语境不同,也体现相似工程直觉:不要让概率比率变化过大。
10. Replay Buffer:Off-Policy 的经验仓库
DQN 使用 Replay Buffer 保存历史经验:
$$\mathcal{D} = { (s_t,a_t,r_t,s_{t+1}) }$$
训练时采样:
$$(s,a,r,s') \sim \mathcal{D}$$
Buffer 中的数据来自多个历史策略。
它提高样本效率,也意味着:
$$\mathcal{D} \not\sim d^{\pi_{\mathrm{current}}}$$
当前策略访问分布与 buffer 数据分布并不完全一致。
因此,Replay Buffer 并不是普通数据集。
它是一段策略历史的混合物。
11. Offline RL:只有旧数据,没有重新试错机会
Offline RL 使用固定数据集:
$$\mathcal{D}_{\mathrm{offline}}$$
训练期间不能随时与环境交互采集新数据。
这很适合:
- 医疗;
- 自动驾驶;
- 真实机器人;
- 高成本工业系统;
- 已积累大量历史日志的产品。
但也更加危险。
如果策略开始偏好数据集缺少覆盖的动作,无法立即回到环境中验证。
价值网络可能在分布外区域给出过于乐观的估计。
因此,Offline RL 常强调保守性:
对没有足够数据支持的动作,不要轻易高估。
12. DPO 为什么不能简单等同于 Offline RL
DPO 使用固定偏好对数据:
$$(x,y_w,y_l)$$
它确实具有离线数据特征。
但更准确的说法是:
DPO 是基于离线偏好数据进行策略优化的方法,不应简单等同于完整意义上的 Offline RL。
原因是:
- 它依赖特定偏好建模与 KL 正则推导;
- 数据通常是回答偏好对,而不是一般 MDP 转移;
- 它不显式学习通用 Q 函数;
- 它将部分奖励与更新结构重新参数化。
但数据覆盖问题仍然存在。
如果偏好数据没有覆盖某类行为,DPO 也难以可靠判断。
矛盾没有消失,只是形式变化。
13. 如何选择 On-Policy 还是 Off-Policy
没有一种数据范式适用于所有任务。
可以问:
| 问题 | 更倾向的选择 |
|---|---|
| 环境交互是否昂贵? | 昂贵时更重视 Off-Policy 复用 |
| 数据分布变化是否剧烈? | 剧烈时更需要 On-Policy 新鲜数据 |
| 是否允许重新采样? | 不允许时进入 Offline RL |
| 价值估计是否容易外推失真? | 容易失真时更重视保守机制 |
| 策略更新是否可能很大? | 更新大时需要限制分布漂移 |
真正的工程系统经常处于连续谱上,而不是非黑即白。
14. 回归全景图(Callback)
| 坐标轴 | On/Off-Policy 如何进入全景图 | 尚未解决什么 |
|---|---|---|
| 目标 | 目标策略仍追求长期回报 | 行为数据是否足以支撑目标 |
| 时间 | 转移样本承载 Bellman 与 TD 更新 | 长轨迹修正权重可能高方差 |
| 更新 | Importance Sampling、Clipping、Replay 改变样本权重 | 修正强度如何选择 |
| 估计 | Off-Policy 提高复用率,也增加分布偏差 | 分布外动作如何保守估计 |
| 数据 | On-Policy 重视新鲜度,Off-Policy 重视复用率 | Coverage 不足无法凭空补齐 |
| 探索 | 行为策略决定覆盖范围 | 如何采到有价值又足够安全的数据 |
On-Policy 与 Off-Policy 没有谁绝对优越。它们分别在数据新鲜度、样本复用率、估计偏差和交互成本之间选择不同位置。
15. 本章小结
行为策略负责采样:
$$b(a\mid s)$$
目标策略负责评价或优化:
$$\pi(a\mid s)$$
On-Policy 满足:
$$b=\pi$$
Off-Policy 允许:
$$b\neq\pi$$
重要性采样比率为:
$$\rho_t = \frac{ \pi(a_t\mid s_t)}{ b(a_t\mid s_t)}$$
它修正分布差异,也可能带来高方差。
下一章将把多个稳定机制放在同一张工具图中:
Replay、Target Network、Clip 与 KL 看起来形式不同,它们分别在稳定什么?
第 12 章:经验回放、目标网络与更新约束:稳定化工具箱
1. 不要把所有“补丁”混成一类
强化学习代码中常出现许多稳定化机制:
- Replay Buffer;
- Target Network;
- Gradient Clipping;
- Advantage Normalization;
- Trust Region;
- PPO Clip;
- KL Penalty;
- Entropy Bonus。
它们很容易被统称为“工程补丁”。
但这种说法过于粗糙。
这些机制并不是在修复同一种故障。它们分别控制:
- 样本相关性;
- 目标漂移;
- 梯度尺度;
- 策略突变;
- 参考分布偏离;
- 探索强度。
理解稳定化机制的关键不是背名字,而是问:
它究竟压住了反馈循环中的哪一个位置?
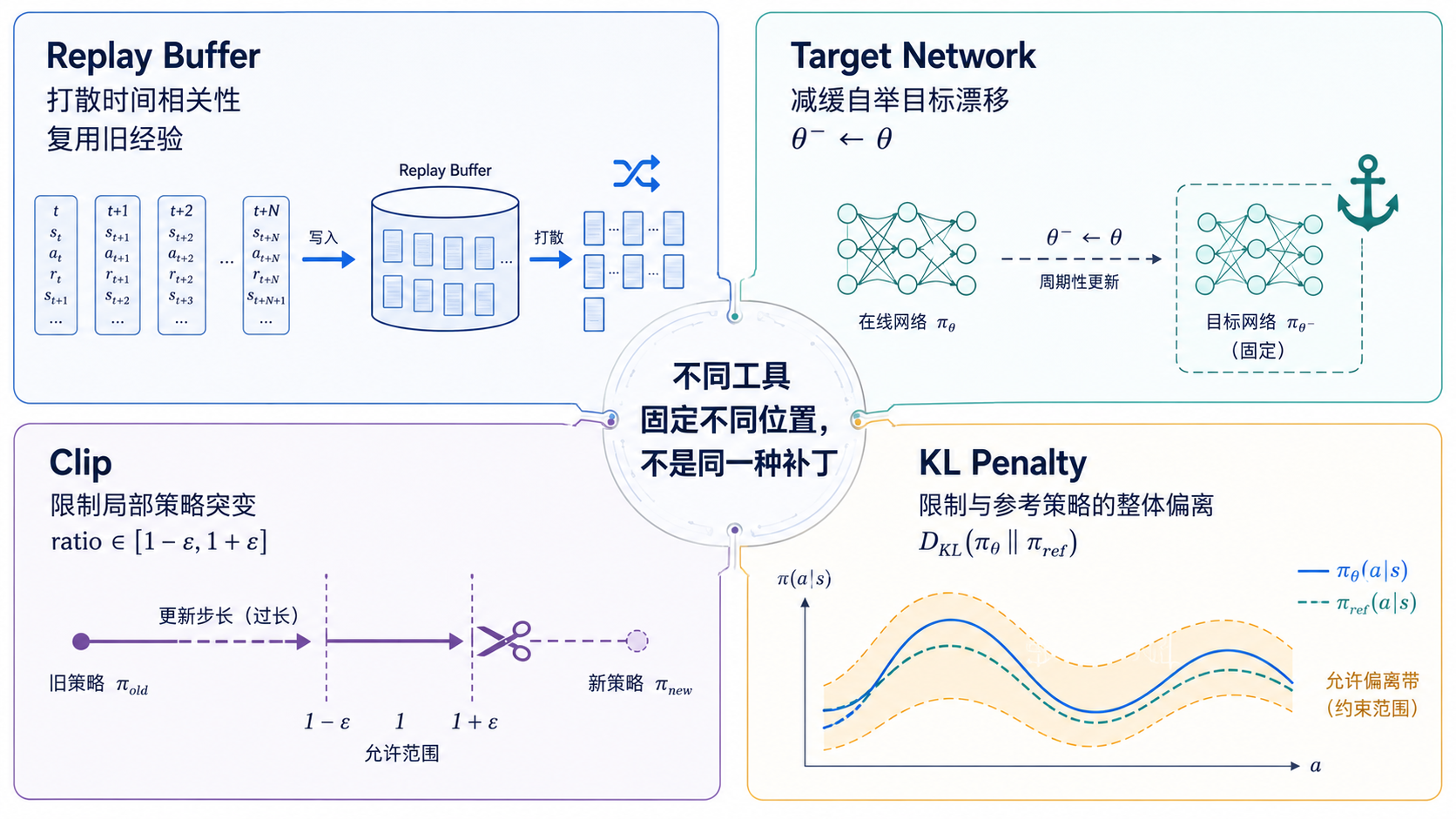
图 12-1:稳定化工具箱
2. Replay Buffer:打散相关性,复用经验
Replay Buffer 保存历史转移:
$$\mathcal{D} = { (s_t,a_t,r_t,s_{t+1}) }$$
训练时随机采样:
$$(s,a,r,s') \sim \mathcal{D}$$
它主要解决两个问题。
2.1 打散时间相关性
连续时间步通常高度相关。
如果机器人连续十步都走在同一条走廊,直接按顺序训练,batch 会缺少多样性。
随机回放将不同时间、不同轨迹的数据混合起来。
2.2 提高样本利用率
一次昂贵交互不必只用一次。
旧经验可以反复进入训练。
2.3 Replay 的代价
旧经验来自旧策略。
因此:
$$\mathcal{D} \not\sim d^{\pi_{\mathrm{current}}}$$
Replay Buffer 在提高样本效率的同时,也引入 Off-Policy 分布差异。
它压住了样本成本,却增加了数据漂移压力。
3. Target Network:让目标慢一点移动
DQN Target 为:
$$y_t = r_t +\gamma \max_{a'} Q_{\theta^-}(s_{t+1},a')$$
其中:
θ:在线网络参数;θ^-:目标网络参数。
在线网络根据 Loss 更新:
$$L(\theta)= \frac{1}{2} [ y_t -Q_\theta(s_t,a_t) ]^2$$
目标网络暂时固定。
3.1 Hard Update
每隔若干步同步一次:
$$\theta^- \leftarrow \theta$$
优点:简单。
代价:同步瞬间目标可能突变。
3.2 Soft Update
缓慢移动:
$$\theta^- \leftarrow \tau\theta +(1-\tau)\theta^-$$
其中:
$$0<\tau\ll1$$
目标网络像一个低通滤波器,不立即追随在线网络。
Target Network 控制的是:
自举目标变化速度。
4. Gradient Clipping:限制单次梯度冲击
如果梯度过大,一次更新可能破坏已经学到的结构。
梯度裁剪写成:
$$g \leftarrow g \cdot \min ( 1,; \frac{c}{|g|} )$$
其中:
| 符号 | 含义 |
|---|---|
g |
原始梯度 |
||g|| |
梯度范数 |
c |
最大允许范数 |
如果:
$$|g|\leq c$$
梯度保持不变。
如果:
$$|g|>c$$
梯度被缩小到允许范围。
Gradient Clipping 控制的是数值冲击。
它不会自动修正错误方向。
5. Advantage Normalization:让更新尺度更可控
策略更新常使用 Advantage:
$$\hat{A}_t$$
一个 batch 中,数值尺度可能差异很大。
归一化写成:
$$\hat{A}_t^{\mathrm{norm}} = \frac{ \hat{A}_t-\mu_A}{ \sigma_A+\varepsilon}$$
其中:
| 符号 | 含义 |
|---|---|
μ_A |
batch 中 Advantage 平均值 |
σ_A |
batch 中 Advantage 标准差 |
ε |
防止除零的小常数 |
它让优化器更容易处理尺度变化。
但要注意:
归一化改变的是相对尺度,不是奖励本身是否正确。
6. Trust Region:新策略不要离旧策略太远
策略梯度希望提高回报。
但如果一次更新太大,旧数据很快失效,新策略可能落入价值估计不可靠区域。
Trust Region 的核心思想是:
在一个局部可信区域内更新策略。
一种约束形式为:
$$\max_\theta ; \mathbf{E}_t [ r_t(\theta)\hat{A}_t ]$$
满足:
$$\mathbf{E}t [ D{\mathrm{KL}} ( \pi_{\theta_{\mathrm{old}}} \parallel \pi_\theta ) ] \leq \delta$$
其中:
| 符号 | 含义 |
|---|---|
r_t(θ) |
新旧策略概率比率 |
Â_t |
Advantage 估计 |
D_KL |
新旧策略分布差异 |
δ |
允许的最大平均 KL |
TRPO 尝试较严格地实现这一思想。
7. PPO Clip:将 Trust Region 做得更实用
PPO 使用概率比率:
$$r_t(\theta)= \frac{ \pi_\theta(a_t\mid s_t)}{ \pi_{\theta_{\mathrm{old}}}(a_t\mid s_t)}$$
并定义:
$$L_{\mathrm{PPO}}^{\mathrm{clip}}(\theta)= \mathbf{E}_t [ \min ( r_t(\theta)\hat{A}_t,; \operatorname{clip} ( r_t(\theta), 1-\epsilon, 1+\epsilon )\hat{A}_t ) ]$$
clip 将比率限制在:
$$[1-\epsilon,;1+\epsilon]$$
附近。
PPO 的直觉是:
如果某个动作概率已经改变很多,就不要继续因为同一批旧数据而获得过多收益。
PPO Clip 控制的是:
局部策略更新幅度。
它不是严格等同于 KL 约束,也不是对所有更新提供绝对保证。
8. KL Penalty:用分布锚点限制整体偏离
KL Divergence 衡量两个分布的差异:
$$D_{\mathrm{KL}}(p \parallel q)= \sum_x p(x)\log \frac{p(x)}{q(x)}$$
策略优化中,可加入惩罚:
$$L_{\mathrm{total}} = L_{\mathrm{reward}} +\beta D_{\mathrm{KL}} ( \pi_\theta \parallel \pi_{\mathrm{ref}} )$$
其中:
| 符号 | 含义 |
|---|---|
π_θ |
当前策略 |
π_ref |
参考策略 |
β |
KL 惩罚强度 |
在 RLHF 中,参考模型通常来自 SFT 模型。
KL 像一根弹性绳:
- 策略可以移动;
- 但偏离越远,代价越大。
它控制的是:
相对参考分布的整体漂移。
9. Entropy Bonus:不要过早失去探索
策略熵定义为:
$$\mathcal{H} ( \pi(\cdot\mid s))= - \sum_a \pi(a\mid s)\log \pi(a\mid s)$$
如果策略集中在少数动作上,熵较低。
如果动作概率更分散,熵较高。
可以在目标中加入熵奖励:
$$J_{\mathrm{total}} = J_{\mathrm{reward}} +\alpha \mathbf{E} [ \mathcal{H} ( \pi(\cdot\mid s)) ]$$
Entropy Bonus 鼓励策略保留一定随机性。
它控制的是:
探索强度与策略塌缩。
第 13 章会详细展开。
10. 一张工具箱对照表
| 工具 | 主要控制对象 | 它没有解决什么 |
|---|---|---|
| Replay Buffer | 样本相关性、复用效率 | 旧数据分布偏差 |
| Target Network | 自举目标漂移速度 | 奖励错误、覆盖不足 |
| Gradient Clipping | 梯度数值冲击 | 梯度方向错误 |
| Advantage Normalization | 更新尺度 | 估计是否准确 |
| Trust Region | 新旧策略差异 | 代理奖励是否合理 |
| PPO Clip | 局部概率比率变化 | 全局策略距离保证 |
| KL Penalty | 相对参考模型的整体偏离 | 参考模型是否足够好 |
| Entropy Bonus | 探索与策略塌缩 | 探索方向是否有价值 |
这张表是本章最重要的结论。
不要问:
哪一个技巧最好?
而要问:
系统现在是哪一种循环转得太快?应该在哪个位置增加阻尼?
11. 边界:稳定化也会限制能力
稳定机制不是越强越好。
Replay 过多使用旧数据,策略可能难以快速适应新分布。
Target Network 更新过慢,目标可能过于陈旧。
PPO Clip 过强,策略几乎无法前进。
KL 惩罚过大,模型只能停留在参考策略附近。
Entropy Bonus 过大,策略可能长期保持随机,无法充分利用已知经验。
稳定性与能力提升之间同样存在张力:
系统需要足够稳定,才能学习;也需要允许适度变化,才能成长。
12. 回归全景图(Callback)
| 坐标轴 | 稳定化工具如何进入全景图 |
|---|---|
| 目标 | 稳定化机制不应替代真实目标 |
| 时间 | Target Network 减慢自举目标变化 |
| 更新 | Gradient Clipping、Trust Region、PPO Clip、KL 控制更新步幅 |
| 估计 | Advantage Normalization 控制尺度,但不保证估计正确 |
| 数据 | Replay Buffer 提高复用率,也混合历史策略分布 |
| 探索 | Entropy Bonus 保留随机性,避免过早塌缩 |
稳定化工具没有消除反馈循环。它们像阻尼器、锚点和护栏,让系统能够在循环中继续学习,而不是因为一次更新失控。
13. 本章小结
本章将常见机制拆开归类。
Replay Buffer 管理经验:
$$(s,a,r,s') \sim \mathcal{D}$$
Target Network 减慢目标漂移:
$$\theta^- \leftarrow \tau\theta +(1-\tau)\theta^-$$
PPO Clip 限制局部概率比率:
$$\operatorname{clip} ( r_t(\theta), 1-\epsilon, 1+\epsilon )$$
KL Penalty 限制整体分布偏离:
$$D_{\mathrm{KL}} ( \pi_\theta \parallel \pi_{\mathrm{ref}} )$$
下一部分进入探索问题:
如果智能体只做当前看来最好的事情,它为什么可能永远找不到真正更好的选择?
第六部分:探索未知,也承担风险
第 13 章:探索与利用:为什么不能总选当前最优
1. 一家熟悉的小店,还是一条未知街道
假设你出差到一座陌生城市,需要选择晚餐。
街角有一家已经吃过的小店。味道不错,大概能得到 7 分。远处还有许多没去过的餐厅,其中一些可能更差,也可能有一家能得到 10 分。
如果今晚只想稳妥吃饭,选择熟悉小店很合理。
但如果要在这座城市生活一年,永远只去同一家店就可能错过更好的选择。
这就是探索与利用(exploration versus exploitation)。
- 利用:选择当前看来最好的动作,获得已知收益;
- 探索:尝试尚未充分了解的动作,获得新信息。
强化学习无法绕开这个矛盾。
只利用,智能体可能困在局部最优。
只探索,智能体又无法稳定获得收益。
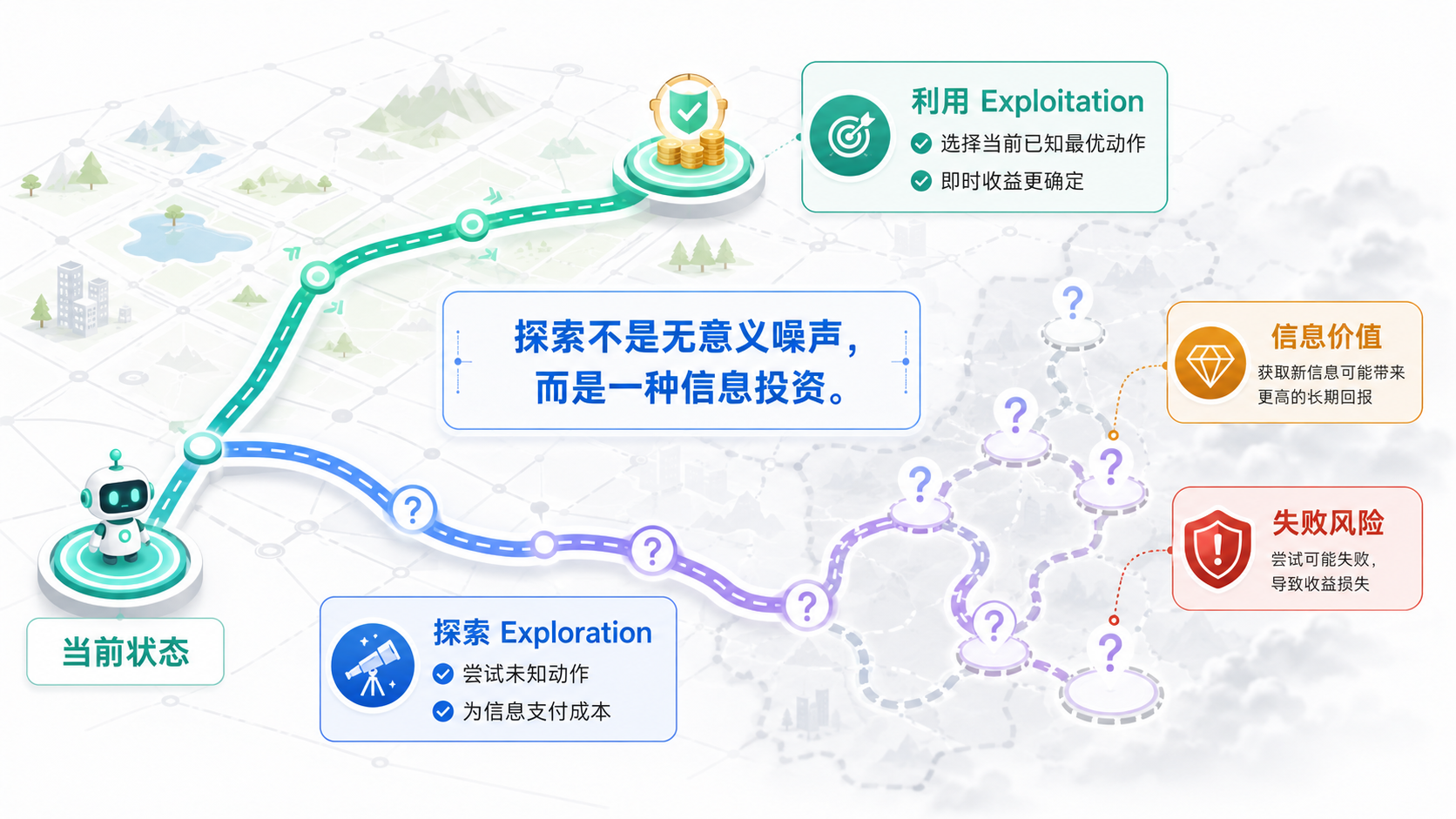
图 13-1:探索与利用
2. Multi-Armed Bandit:最小化的探索实验室
探索问题最简单的版本称为多臂老虎机(Multi-Armed Bandit)。
假设有 K 台老虎机。每台机器对应一个动作:
$$a\in{1,2,\ldots,K}$$
选择动作 a 后,会得到随机奖励:
$$R_t$$
每个动作的真实期望奖励为:
$$q_*(a) = \mathbf{E} [ R_t \mid A_t=a ]$$
其中:
| 符号 | 含义 |
|---|---|
A_t |
第 t 次选择的动作 |
R_t |
第 t 次得到的奖励 |
q_*(a) |
动作 a 的真实期望奖励 |
问题是:
智能体不知道
q_*(a),只能一边尝试,一边估计。
Bandit 没有复杂状态转移,却保留了探索的核心矛盾。
3. 动作价值估计
设动作 a 已经被选择:
$$N_t(a)$$
次。
经验平均奖励为:
$$Q_t(a)= \frac{ \sum_{i=1}^{t-1} R_i \mathbf{1}(A_i=a)}{ N_t(a)}$$
其中:
| 符号 | 含义 |
|---|---|
Q_t(a) |
截至时刻 t,对动作 a 的价值估计 |
N_t(a) |
动作 a 被选择的次数 |
1(A_i=a) |
如果第 i 次选择了动作 a,取 1;否则取 0 |
也可以使用增量更新:
$$Q_{n+1} = Q_n +\frac{1}{n} [ R_n-Q_n ]$$
这条公式与前面价值更新形式非常相似:
新估计 = 旧估计 + 步长 × 新证据与旧估计之差
4. 贪心策略为什么会被早期运气锁死
最直接的策略是:
$$A_t = \arg\max_a Q_t(a)$$
这称为贪心策略。
它总是选择当前估计价值最高的动作。
问题在于,早期样本很少,估计噪声很大。
假设:
- 动作 A 的真实期望为
6; - 动作 B 的真实期望为
8。
第一次尝试时:
- A 偶然得到
7; - B 偶然得到
3。
贪心策略会继续选择 A。
如果之后不再尝试 B,智能体永远不会发现 B 才是真正更好的动作。
局部最优并不总是来自复杂地形。
它有时只是来自早期运气。
5. ε-greedy:故意偶尔做一点“不理性”的事
一种简单方法是 ε-greedy。
策略定义为:
$$P(A_t=a)= \begin{cases} 1-\epsilon+\frac{\epsilon}{K}, & a=\arg\max_{a'}Q_t(a') \ \frac{\epsilon}{K}, & \mathrm{其他动作} \end{cases}$$
其中:
| 符号 | 含义 |
|---|---|
ε |
探索概率 |
K |
动作数量 |
1-ε |
主要利用当前最佳动作 |
ε |
随机尝试动作 |
直觉是:
大多数时候相信当前判断,偶尔故意尝试其他选择。
5.1 手算一次
假设:
$$\epsilon=0.1$$
并且有:
$$K=4$$
个动作。
当前最佳动作被选中的概率为:
$$1-0.1+\frac{0.1}{4} =0.925$$
其他每个动作被选中的概率为:
$$\frac{0.1}{4} =0.025$$
ε-greedy 很简单,却表达了一个深刻事实:
为了发现最优策略,智能体必须允许自己暂时不做当前看起来最优的事情。
6. ε 应该固定还是衰减
训练初期,价值估计不可靠,通常需要更多探索。
训练后期,估计更加稳定,可以逐渐增加利用。
因此,常见做法是让:
$$\epsilon_t$$
随时间衰减。
例如:
$$\epsilon_t = \max ( \epsilon_{\min}, \epsilon_0\lambda^t )$$
其中:
| 符号 | 含义 |
|---|---|
ε_0 |
初始探索率 |
λ |
衰减比例,通常小于 1 |
ε_min |
最低探索率 |
探索率过快下降,智能体可能过早锁死。
探索率过慢下降,智能体可能长期浪费收益。
探索不是一个开关,而是一种时间安排。
7. Softmax Exploration:价值差异应该影响探索概率
ε-greedy 将非最优动作近似平等对待。
但一个估计价值略低的动作,与一个明显很差的动作,不一定应该获得相同探索机会。
Softmax 策略写成:
$$\pi(a\mid s)= \frac{ \exp ( Q(s,a)/\tau )}{ \sum_{a'} \exp ( Q(s,a')/\tau )}$$
其中:
| 符号 | 含义 |
|---|---|
τ |
温度参数 |
exp |
指数函数 |
Q(s,a) |
动作价值估计 |
当:
$$\tau\to0$$
策略越来越接近贪心。
当:
$$\tau$$
较大时,动作概率更加均匀。
温度控制:
策略对价值差异有多敏感。
语言模型生成中的 temperature,也体现类似直觉。
8. Entropy Bonus:把随机性写入目标
策略熵定义为:
$$\mathcal{H} ( \pi(\cdot\mid s))= - \sum_a \pi(a\mid s)\log \pi(a\mid s)$$
熵较高,说明策略更分散。
熵较低,说明策略集中在少数动作。
可以将熵加入目标:
$$J_{\mathrm{total}} = J_{\mathrm{reward}} +\alpha \mathbf{E} [ \mathcal{H} ( \pi(\cdot\mid s)) ]$$
其中:
| 符号 | 含义 |
|---|---|
J_reward |
原始奖励目标 |
H(π) |
策略熵 |
α |
熵奖励强度 |
Entropy Bonus 鼓励策略保留多样性。
它不是为了永远随机,而是避免过早塌缩。
9. Optimism:对未知保持适度乐观
另一条路线是:
没有充分尝试过的动作,不应该过早判死刑。
可以将初始价值设得较高:
$$Q_0(a)=Q_{\mathrm{optimistic}}$$
如果一个动作尚未充分尝试,它会因为乐观估计而被选择。
随着实际奖励出现,估计逐渐回落到现实。
这种方法称为乐观初始化。
它鼓励探索,却依赖任务尺度。
如果初始值太高,可能浪费大量尝试;如果太低,又不足以推动探索。
10. UCB:奖励高,还不够;不确定性也值钱
Upper Confidence Bound,简称 UCB。
它不只看平均奖励,还考虑不确定性。
一种常见形式为:
$$A_t = \arg\max_a [ Q_t(a)+c \sqrt{ \frac{ \ln t}{ N_t(a)}} ]$$
逐项解释:
| 符号 | 含义 |
|---|---|
Q_t(a) |
当前平均奖励估计 |
N_t(a) |
动作 a 被尝试次数 |
ln t |
随总时间缓慢增长 |
c |
探索强度 |
| 根号项 | 对低频动作的不确定性奖励 |
UCB 将动作价值分成两部分:
当前已知收益 + 尚未充分了解的潜在价值
当某个动作尝试次数很少:
$$N_t(a)$$
较小,探索奖励较大。
尝试次数增加后,不确定性奖励逐渐下降。
10.1 手算一次
假设:
$$t=100$$
$$c=1$$
动作 A:
$$Q(A)=7,\quad N(A)=50$$
动作 B:
$$Q(B)=6.5,\quad N(B)=2$$
动作 A 的 UCB 为:
$$7+ \sqrt{ \frac{\ln100}{50}} \approx 7.30$$
动作 B 的 UCB 为:
$$6.5+ \sqrt{ \frac{\ln100}{2}} \approx 8.02$$
虽然 B 当前平均奖励较低,但因为尚未充分尝试,它值得继续探索。
11. Thompson Sampling:按照不确定性采样
Thompson Sampling 使用贝叶斯视角。
对每个动作的未知价值维护一个后验分布:
$$p ( q(a)\mid \mathcal{D} )$$
每次决策时:
- 从每个动作后验分布中采样一个可能价值;
- 选择采样值最高的动作;
- 观察奖励;
- 更新后验。
写成:
$$\tilde{q}(a)\sim p ( q(a)\mid \mathcal{D} )$$
然后:
$$A_t = \arg\max_a \tilde{q}(a)$$
Thompson Sampling 的直觉是:
不确定性不是附加噪声,而是决策的一部分。
12. Contextual Bandit:当选择取决于场景
普通 Bandit 没有状态。
现实中,选择通常依赖上下文:
- 不同用户偏好不同内容;
- 不同时间适合不同推荐;
- 不同提示词适合不同回答策略。
Contextual Bandit 引入上下文:
$$x_t$$
动作价值变为:
$$q_*(a\mid x_t)$$
策略根据上下文选择动作:
$$A_t \sim \pi(\cdot\mid x_t)$$
Contextual Bandit 仍然没有完整长时序状态转移,却已经连接推荐系统、广告投放和在线决策。
13. 探索不是噪声,而是信息投资
许多探索机制看起来像故意制造随机性:
ε-greedy;- Softmax temperature;
- Entropy Bonus;
- 乐观初始化;
- UCB;
- Thompson Sampling。
但探索不应被简单理解为“加一点噪声”。
更准确的说法是:
智能体暂时牺牲一部分眼前收益,以换取关于未知世界的信息。
信息本身具有未来价值。
一次看似吃亏的尝试,可能改善后续许多决策。
14. 边界:简单探索在长序列中会失效
在 Bandit 中,随机尝试一个动作就能直接观察结果。
但在长序列任务中,真正有价值的发现可能需要连续做出一系列特定动作。
例如:
先拿钥匙
→ 穿过走廊
→ 避开守卫
→ 打开隐藏门
→ 获得奖励
ε-greedy 在每一步随机尝试,很难偶然完成整条链。
探索需要更深的时间结构。
下一章将讨论:
当奖励极其稀疏,随机试错为什么不够?智能体如何主动寻找新颖状态和有信息的路径?
15. 回归全景图(Callback)
| 坐标轴 | 探索与利用如何进入全景图 | 尚未解决什么 |
|---|---|---|
| 目标 | 探索暂时牺牲即时收益,争取更高长期回报 | 信息价值如何准确衡量 |
| 时间 | 当前探索可能在未来才产生收益 | 长序列探索如何组织 |
| 更新 | ε、temperature、entropy coefficient 控制策略随机性 |
调度参数如何选择 |
| 估计 | UCB、Thompson Sampling 显式考虑不确定性 | 深度网络中的不确定性估计更难 |
| 数据 | 探索扩展状态动作覆盖 | 危险或昂贵环境中不能任意采样 |
| 探索 | 利用已知与发现未知之间持续取舍 | 如何进行深度探索 |
探索没有消灭不确定性。它承认不确定性,并把一部分行动预算投入到减少不确定性上。
16. 本章小结
ε-greedy 使用:
$$P(A_t=a)= \begin{cases} 1-\epsilon+\frac{\epsilon}{K}, & a=\arg\max_{a'}Q_t(a') \ \frac{\epsilon}{K}, & \mathrm{其他动作} \end{cases}$$
Softmax 使用温度控制分布:
$$\pi(a\mid s)= \frac{ \exp ( Q(s,a)/\tau )}{ \sum_{a'} \exp ( Q(s,a')/\tau )}$$
UCB 将不确定性写入选择:
$$A_t = \arg\max_a [ Q_t(a)+c \sqrt{ \frac{ \ln t}{ N_t(a)}} ]$$
下一章继续深入:
如果发现奖励需要连续做对许多步,简单随机探索为什么远远不够?
第 14 章:深度探索:从随机试错到主动寻找信息
1. 随机走一步,不等于真正探索
上一章讨论了 ε-greedy。
它让智能体偶尔随机尝试其他动作。
但在很多任务中,真正有价值的奖励藏得很深。
例如:
离开起点
→ 拿到钥匙
→ 穿过走廊
→ 找到隐藏门
→ 打开宝箱
→ 获得奖励
如果每一步都只靠低概率随机动作,完整走通这条链的概率会非常小。
假设每一步正确探索动作的概率为:
$$p$$
连续走对 n 步的概率为:
$$p^n$$
如果:
$$p=0.1$$
并且:
$$n=6$$
那么:
$$p^n = 0.1^6 = 0.000001$$
仅靠局部随机噪声,很难发现长链奖励。
这就是深度探索(deep exploration)问题。
2. 稀疏奖励为什么让学习陷入沉默
假设奖励只有抵达终点时才出现:
$$r_t = \begin{cases} 1, & \mathrm{抵达目标}\ 0, & \mathrm{其他情况} \end{cases}$$
训练初期,大量轨迹都是:
$$(0,0,0,\ldots,0)$$
无论智能体向左走还是向右走,无论发现新房间还是原地打转,奖励看起来都一样。
外部奖励没有告诉它:
哪一种尝试更值得继续?
于是,探索问题变成信息问题:
即使尚未得到任务奖励,能否鼓励智能体访问新颖、有信息、可能带来未来突破的状态?
3. Intrinsic Motivation:给好奇心一点奖励
外部环境提供的奖励称为外在奖励:
$$r_t^{\mathrm{ext}}$$
为了鼓励探索,可以加入内在奖励:
$$r_t^{\mathrm{int}}$$
总奖励写成:
$$r_t = r_t^{\mathrm{ext}} +\beta r_t^{\mathrm{int}}$$
其中:
| 符号 | 含义 |
|---|---|
r_t^ext |
任务真正关心的外部奖励 |
r_t^int |
为探索提供的内部奖励 |
β |
内在奖励权重 |
内在奖励不是最终目的。
它像路灯,在外部奖励稀疏时帮助智能体继续前进。
但路灯也可能把智能体带偏。
4. Count-Based Exploration:少见的状态更值得看
最直观的内在奖励来自访问次数。
设状态 s 被访问次数为:
$$N(s)$$
可以定义探索奖励:
$$r^{\mathrm{int}}(s)= \frac{1}{ \sqrt{ N(s)}}$$
访问次数少时,奖励较大。
访问次数增加后,奖励逐渐下降。
例如:
N(s) |
r_int(s) |
|---|---|
1 |
1 |
4 |
0.5 |
100 |
0.1 |
直觉是:
第一次看见某个状态很有价值,第一百次再看就没那么新鲜。
4.1 高维状态的问题
图像、机器人姿态和语言上下文几乎每次都不同。
直接统计:
$$N(s)$$
很难奏效。
因此,需要伪计数、状态哈希、密度模型或表示学习。
5. Curiosity:预测不准的地方值得探索
另一种思路是:
如果世界模型难以预测某个转移,说明那里还有新信息。
设特征编码器为:
$$\phi(s)$$
前向模型尝试预测下一状态特征:
$$\hat{\phi}(s_{t+1})= f_\theta ( \phi(s_t),a_t )$$
可以将预测误差作为内在奖励:
$$r_t^{\mathrm{int}} = \frac{1}{2} | \phi(s_{t+1})- \hat{\phi}(s_{t+1}) |^2$$
逐项解释:
| 符号 | 含义 |
|---|---|
φ(s_t) |
当前状态的特征表示 |
f_θ |
预测下一状态特征的模型 |
φ̂(s_{t+1}) |
模型预测 |
φ(s_{t+1}) |
实际观察 |
| 误差平方 | 新奇程度或预测困难程度 |
预测误差越大,内在奖励越高。
这鼓励智能体前往模型尚未理解的区域。
6. Noisy TV Problem:不可预测不等于有价值
Curiosity 有一个经典陷阱。
假设房间里有一台电视,每次播放随机噪声。
智能体无论看多少次,都难以预测下一帧。
于是:
$$r_t^{\mathrm{int}}$$
持续很高。
智能体可能沉迷于电视噪声,而不是完成真正任务。
这称为 Noisy TV Problem。
它提醒我们:
不可预测性不等于有价值的信息。
有些噪声是无法学习的随机性,不值得反复探索。
好的探索机制需要区分:
- 尚未理解;
- 原理上不可预测;
- 与任务无关。
7. Random Network Distillation
Random Network Distillation,简称 RND。
它使用两个网络:
- 固定随机目标网络:
$$f_{\mathrm{target}}(s)$$
- 可训练预测网络:
$$f_\theta(s)$$
内在奖励为:
$$r_t^{\mathrm{int}} = | f_\theta(s_t)- f_{\mathrm{target}}(s_t) |^2$$
如果状态经常出现,预测网络逐渐学会匹配固定目标,误差下降。
如果状态新颖,预测误差较大,内在奖励较高。
RND 的直觉是:
新状态还没有被预测网络“背熟”,因此值得继续关注。
它避免显式统计每个高维状态的访问次数。
但 RND 同样依赖状态表示、归一化和奖励尺度。
8. Information Gain:探索是减少不确定性
更一般地,探索可以理解为减少模型不确定性。
假设模型参数为:
$$\theta$$
已有数据为:
$$\mathcal{D}$$
观察新样本后:
$$\mathcal{D}' = \mathcal{D} \cup { (s_t,a_t,r_t,s_{t+1}) }$$
信息增益可以写成后验变化:
$$I_t = D_{\mathrm{KL}} ( p(\theta\mid\mathcal{D}')\parallel p(\theta\mid\mathcal{D}))$$
其中:
| 符号 | 含义 |
|---|---|
p(θ|D) |
观察旧数据后的模型参数后验 |
p(θ|D') |
加入新经验后的后验 |
D_KL |
新经验让认知改变了多少 |
信息增益高,说明新经验显著改变了模型对世界的理解。
这比单纯“预测误差大”更加接近探索本质。
但真实深度网络中,可靠计算后验通常很困难。
9. Hierarchical RL:把长路径拆成子目标
如果奖励需要几十步甚至几百步才能获得,逐步探索非常困难。
一种方法是引入层级结构。
高层策略选择子目标:
$$g_t \sim \pi_{\mathrm{high}} (\cdot\mid s_t)$$
低层策略选择动作:
$$a_t \sim \pi_{\mathrm{low}} (\cdot\mid s_t,g_t)$$
其中:
| 符号 | 含义 |
|---|---|
g_t |
子目标 |
π_high |
高层策略 |
π_low |
完成子目标的低层策略 |
例如:
高层:先去厨房
低层:向前、左转、开门
高层:再拿钥匙
低层:接近桌子、伸手、抓取
层级策略把长时间探索拆成更短任务。
它提高可搜索性,也引入子目标设计与层级信用分配问题。
10. MCTS:在行动之前先展开可能未来
另一条路线是搜索。
Monte Carlo Tree Search,简称 MCTS。
它不只依赖当前网络直接选动作,而是在决策前模拟多条可能未来。
MCTS 常包含四步:
- Selection:根据已有统计选择节点;
- Expansion:展开新节点;
- Evaluation:估计叶子节点价值;
- Backup:将结果向上回传。
节点动作选择常使用类似 UCB 的规则:
$$a = \arg\max_a [ Q(s,a)+c \sqrt{ \frac{ \ln N(s)}{ N(s,a)}} ]$$
其中:
| 符号 | 含义 |
|---|---|
Q(s,a) |
当前动作价值估计 |
N(s) |
状态节点访问次数 |
N(s,a) |
状态动作边访问次数 |
| 根号项 | 对尚未充分搜索动作的探索奖励 |
搜索将探索从“真实环境中的试错”部分转移到“决策前的模拟展开”。
11. AlphaGo 与 AlphaZero:学习与搜索互相增强
AlphaGo 系列的重要启示不是某个单独公式,而是学习与搜索之间的循环。
策略网络提供候选动作先验。
价值网络估计局面。
MCTS 使用网络缩小搜索空间。
搜索结果反过来生成更强监督信号。
可以概括为:
神经网络
→ 引导搜索
→ 搜索改进决策
→ 产生更好的训练目标
→ 改进神经网络
这是一种新的自我更新循环。
它不是单纯增加随机噪声,而是在内部模拟中主动分配计算预算。
12. Model-Based Exploration:先学习世界,再在想象中试错
如果能够学习环境模型:
$$\hat{P}\theta(s{t+1}\mid s_t,a_t)$$
智能体可以在模型中模拟未来。
真实环境交互昂贵,模型中的“想象轨迹”成本较低。
但模型可能不准确。
模型误差会沿模拟轨迹累积。
因此:
想象扩大了探索范围,也可能扩大错误世界观。
第 19 章会详细讨论 Model-Based RL。
13. 大模型推理中的探索
大模型生成多个候选回答,也是一种有限探索。
对于同一个提示词:
$$x$$
采样多个回答:
$${ y_1,y_2,\ldots,y_G }$$
再使用 Verifier 或奖励模型评价:
$$R(x,y_i)$$
选择更好的回答,或使用组内相对优势更新策略。
这与 GRPO、Best-of-N、搜索和推理时采样都有联系。
探索不再表现为机器人随机走动,而是:
在语言空间中生成不同推理轨迹,再通过评价筛选或学习。
但候选多样性、采样温度、验证器可靠性和计算成本仍然构成边界。
14. 边界:探索奖励也会被优化
内在奖励仍然是奖励。
只要它可以被优化,就可能被投机。
可能出现:
- 反复访问随机噪声;
- 制造不可预测状态;
- 追求新颖而忽略任务;
- 在模型盲区中循环;
- 过度扩散,无法形成稳定技能。
因此,内在奖励通常需要:
- 权重衰减;
- 与外部奖励组合;
- 状态表示约束;
- 随机噪声过滤;
- episodic novelty;
- 安全边界。
探索机制没有摆脱奖励设计问题。
它只是将奖励设计扩展到了“信息价值”。
15. 回归全景图(Callback)
| 坐标轴 | 深度探索如何进入全景图 | 尚未解决什么 |
|---|---|---|
| 目标 | 内在奖励为外部目标提供探索路标 | 内在奖励是否会偏离任务 |
| 时间 | 长链奖励需要持续多步探索 | 如何把发现归因给早期动作 |
| 更新 | β、新颖度、搜索统计影响策略更新 |
探索奖励尺度如何校准 |
| 估计 | Curiosity、RND、信息增益估计未知程度 | 随机噪声与有价值未知如何区分 |
| 数据 | 探索扩展覆盖范围,搜索与模型生成额外轨迹 | 模拟数据是否可靠 |
| 探索 | 从局部随机转向新颖性、子目标、搜索和模型想象 | 如何控制现实成本与风险 |
深度探索没有取消试错。它重新组织试错:将随机行动转化为对新颖状态、信息增益、子目标和模拟未来的主动投资。
16. 本章小结
Count-Based Exploration 使用:
$$r^{\mathrm{int}}(s)= \frac{1}{ \sqrt{ N(s)}}$$
Curiosity 使用预测误差:
$$r_t^{\mathrm{int}} = \frac{1}{2} | \phi(s_{t+1})- f_\theta ( \phi(s_t),a_t ) |^2$$
RND 使用随机目标网络:
$$r_t^{\mathrm{int}} = | f_\theta(s_t)- f_{\mathrm{target}}(s_t) |^2$$
MCTS 则在真实行动之前展开可能未来。
下一章进入现实边界:
当试错可能造成真实伤害、昂贵成本或不可逆后果时,探索还应该怎样进行?
第 15 章:探索的边界:安全、成本与可控性
1. 游戏里可以重来,现实中未必
在电子游戏中,智能体失败一次,最多损失一局。
但真实世界并不总允许廉价试错。
- 机器人摔倒可能损坏设备;
- 自动驾驶探索危险动作可能伤害行人;
- 医疗策略不能随意尝试未知剂量;
- 推荐系统可能损害用户信任;
- 大模型探索越过安全边界,可能生成危险内容或利用评价漏洞。
探索仍然重要。
没有探索,智能体无法突破已有能力。
但探索不能再被理解为:
随机做点不一样的事情,看看会发生什么。
现实系统必须问:
哪些尝试可以发生?哪些尝试代价过高?如何在不越过底线的情况下继续学习?
2. 奖励最大化之外,还有约束
标准强化学习目标为:
$$\max_\pi J_R(\pi)$$
其中:
$$J_R(\pi) = \mathbf{E}\pi [ \sum{t=0}^{\infty} \gamma^t r_t ]$$
但安全任务通常还有成本:
$$c_t$$
例如:
- 碰撞;
- 违反规则;
- 能耗超限;
- 风险暴露;
- 有害输出。
累计成本定义为:
$$J_C(\pi) = \mathbf{E}\pi [ \sum{t=0}^{\infty} \gamma^t c_t ]$$
安全约束可以写成:
$$J_C(\pi) \leq d$$
其中:
| 符号 | 含义 |
|---|---|
J_R(π) |
策略的期望累计奖励 |
J_C(π) |
策略的期望累计成本 |
d |
可接受的成本上限 |
于是问题变为:
$$\max_\pi J_R(\pi)\quad \mathrm{subject to} \quad J_C(\pi)\leq d$$
这类问题称为 Constrained MDP。
它不再只问“收益多高”,还问“代价是否越界”。
3. 拉格朗日方法:给违规行为定价
约束优化常使用拉格朗日乘子。
定义:
$$\mathcal{L} (\pi,\lambda)= J_R(\pi)- \lambda [ J_C(\pi)-d ]$$
其中:
$$\lambda\geq0$$
逐项解释:
| 符号 | 含义 |
|---|---|
λ |
对违反成本约束的惩罚强度 |
J_C(π)-d |
超出安全预算多少 |
L(π,λ) |
同时考虑收益与约束的目标 |
如果成本超标:
$$J_C(\pi)>d$$
惩罚增大。
如果成本低于预算,策略有更多空间追求收益。
拉格朗日方法像动态定价:
越接近安全边界,继续冒险的价格越高。
4. Reward Penalty 与硬约束并不相同
一种简单做法是将成本写进奖励:
$$r_t' = r_t -\beta c_t$$
这很常见,也很实用。
但它与硬约束不同。
如果收益足够高,策略仍可能接受严重违规:
$$\mathrm{高奖励} - \mathrm{有限惩罚} > 0$$
在某些任务中,这不可接受。
例如:
- 不能用更高运输效率交换少量严重碰撞;
- 不能用更高点击率交换系统性欺骗;
- 不能用更高回答奖励交换危险行为。
因此,要区分:
| 机制 | 含义 |
|---|---|
| Reward Penalty | 违规有代价,但仍允许权衡 |
| Hard Constraint | 某些边界原则上不可越过 |
| Shield | 在执行前直接拦截危险动作 |
5. Safe Exploration:探索也要有护栏
安全探索的目标不是停止探索,而是控制探索范围。
可以定义安全动作集合:
$$\mathcal{A}_{\mathrm{safe}}(s)$$
策略只能从中选择:
$$a_t \in \mathcal{A}_{\mathrm{safe}}(s_t)$$
或者在策略给出动作后,由安全层修正:
$$a_t^{\mathrm{exec}} = \Pi_{\mathcal{A}_{\mathrm{safe}}} ( a_t )$$
其中:
| 符号 | 含义 |
|---|---|
a_t |
原始策略建议的动作 |
A_safe(s_t) |
当前状态允许的安全动作集合 |
Π |
投影或安全修正 |
a_t^exec |
实际执行的动作 |
这像一道防护栏:
策略仍然可以探索,但不能轻易跨过不可接受边界。
6. 仿真器:将危险试错转移到更便宜的世界
真实交互昂贵时,可以先在仿真器中训练。
设真实环境动力学为:
$$P_{\mathrm{real}} (s'\mid s,a)$$
仿真环境为:
$$P_{\mathrm{sim}} (s'\mid s,a)$$
理想情况下:
$$P_{\mathrm{sim}} \approx P_{\mathrm{real}}$$
但两者通常存在差异。
这称为 Sim-to-Real Gap。
仿真器降低了现实成本,却引入模型偏差:
智能体可能学会利用模拟器,而不是适应真实世界。
因此,需要:
- 域随机化;
- 真实数据校准;
- 保守部署;
- 分阶段验证;
- 安全监控。
风险没有消失,只是从真实试错转移到模型误差。
7. Offline RL:不在真实环境中随意探索
当真实试错不可接受时,可以使用历史数据:
$$\mathcal{D}_{\mathrm{offline}}$$
训练策略。
优点:
- 不需要在线尝试危险动作;
- 可以利用已有日志;
- 更适合高成本场景。
但 Offline RL 面临覆盖问题。
数据集中没有出现过的动作,无法可靠评价。
如果策略偏离数据分布太远:
$$\pi(a\mid s)\gg b(a\mid s)$$
估计风险增大。
因此,Offline RL 常强调:
只在数据能够支持的范围内改进。
这与 RLHF 中 KL 约束参考模型的直觉相通。
8. Conservative Learning:对未知保持谨慎
如果某个动作缺少数据,不应因为网络偶然给出高值就盲目相信。
保守学习倾向于压低分布外动作价值。
一种抽象写法是:
$$L_{\mathrm{total}} = L_{\mathrm{Bellman}} +\alpha L_{\mathrm{conservative}}$$
其中:
| 符号 | 含义 |
|---|---|
L_Bellman |
保持价值递归一致性的损失 |
L_conservative |
惩罚缺少数据支持的乐观估计 |
α |
保守强度 |
保守性降低风险,也可能限制能力上限。
如果过于保守,策略永远停留在已有数据附近,无法发现真正更好的行为。
9. Human-in-the-Loop:让人类留在循环中
在高风险系统中,人类不一定应该完全退出。
Human-in-the-Loop 可以表现为:
- 人工审核危险动作;
- 人工批准部署阶段;
- 人类提供偏好数据;
- 人类标注异常样本;
- 人类设置不可越过的规则;
- 人类在不确定性高时接管。
可以定义接管条件:
$$u(s_t) > \delta$$
其中:
| 符号 | 含义 |
|---|---|
u(s_t) |
当前状态不确定性或风险评分 |
δ |
人工接管阈值 |
当风险过高时,系统不继续自动探索。
人类参与降低自治程度,却提高可控性。
10. 大模型中的安全探索
大模型后训练同样需要探索。
例如,GRPO 对同一提示词生成多个候选回答:
$${ y_1,y_2,\ldots,y_G }$$
这些回答提供有限探索。
但探索范围受到多种机制控制:
- 采样温度;
- Top-p;
- KL 约束;
- 内容过滤;
- Verifier;
- 规则奖励;
- 人工审核;
- 红队测试。
如果模型过于贴近参考策略,能力突破可能受限。
如果偏离太快,Reward Model 或 Verifier 可能进入不可靠区域。
因此,大模型后训练同样在问:
怎样让模型产生足够多的新行为,又不让评价系统失去控制?
11. 风险敏感目标
期望回报不能表达全部风险。
假设两种策略期望相同:
$$\mathbf{E}[G^A] = \mathbf{E}[G^B] =5$$
但:
- A 稳定得到
5; - B 一半概率得到
20,一半概率得到-10。
在高风险场景中,可能更偏好 A。
可以考虑方差惩罚:
$$J_{\mathrm{risk}} = \mathbf{E}[G] - \beta \operatorname{Var}(G)$$
或者使用 CVaR 等风险度量。
这说明:
安全不是在奖励最大化之后附加一条规则,而是可能改变“什么叫好策略”本身。
12. 边界:安全与突破之间没有永久答案
探索越强,越可能发现新能力。
探索越强,也越可能进入未知风险。
约束越强,系统越稳定。
约束越强,也越可能锁死上限。
因此,工业系统常采用分阶段策略:
- 在模拟器中广泛探索;
- 在离线数据上保守训练;
- 在受控环境中小规模在线验证;
- 使用监控、回滚和人工接管;
- 逐步扩大部署范围。
安全不是一个单独超参数,而是一套制度设计。
13. 回归全景图(Callback)
| 坐标轴 | 安全探索如何进入全景图 | 尚未解决什么 |
|---|---|---|
| 目标 | 奖励目标外加入成本、风险和约束 | 多目标权重与硬边界如何确定 |
| 时间 | 当前探索可能造成延迟风险 | 长期安全后果如何评价 |
| 更新 | 拉格朗日惩罚、Shield、KL、保守正则限制更新 | 约束强度如何调节 |
| 估计 | 风险模型、模拟器和不确定性估计决定安全判断 | 模型误差如何被发现 |
| 数据 | Offline RL、仿真、人工审核降低在线风险 | 数据覆盖不足如何突破 |
| 探索 | 探索被限制在可接受边界内 | 如何保留能力增长空间 |
安全探索没有消灭风险。它将风险显式化、预算化、分阶段化,并为不可接受的后果设置护栏。
14. 本章小结
安全强化学习不仅优化奖励:
$$\max_\pi J_R(\pi)$$
还要满足成本约束:
$$J_C(\pi) \leq d$$
拉格朗日目标为:
$$\mathcal{L} (\pi,\lambda)= J_R(\pi)- \lambda [ J_C(\pi)-d ]$$
安全层还可以限制执行动作:
$$a_t^{\mathrm{exec}} = \Pi_{\mathcal{A}_{\mathrm{safe}}} ( a_t )$$
至此,六个核心问题已经全部展开。
下一部分不再按时间顺序介绍算法,而是回到全景图:
DQN、策略梯度、Actor-Critic 与 Model-Based RL 分别是如何组合这些矛盾的?
第七部分:把算法放回全景图
第 16 章 综合案例一:价值方法如何一步步长成 DQN
如果只看最终形式,DQN 很容易被误解成“用神经网络拟合一个 Q 函数”。这句话不能算错,却漏掉了真正重要的部分。
DQN 不是突然出现的技巧集合。它背后有一条清晰的演化路径:
- Bellman 方程把长期回报拆成当前奖励与未来价值;
- 动态规划在已知环境中反复执行评估与改进;
- Monte Carlo 方法放弃环境模型,直接从完整轨迹学习;
- SARSA 用一步自举提高更新效率;
- Q-Learning 允许学习者使用旧策略采集的数据;
- DQN 用神经网络表示价值函数,再用经验回放与目标网络压住由此产生的不稳定。
每一步都在解决一个真实问题,也都在引入新的代价。
这一章不是算法年表,而是一场组装实验。我们要观察:当目标、时间、更新、估计、数据和探索逐步叠加时,一个现代价值方法是如何长出来的。
一、从 Bellman 方程重新出发
本章起,综合案例采用教材中更常见的 $R_{t+1}$ 记号:执行动作 $A_t$ 后获得奖励 $R_{t+1}$。前文使用的 $r_t$ 表示同一条转移上的奖励。两种记号只是索引约定不同,不应在同一条公式中混用。
在状态 $s$ 下执行动作 $a$,策略 $\pi$ 的动作价值函数定义为:
$$Q^\pi(s,a) = \mathbf{E}\pi [ \sum{k=0}^{\infty} \gamma^k R_{t+k+1} \mid S_t=s,A_t=a ]$$
其中:
| 符号 | 含义 |
|---|---|
| $Q^\pi(s,a)$ | 在状态 $s$ 先执行动作 $a$,之后遵循策略 $\pi$ 时的期望长期回报 |
| $R_{t+k+1}$ | 从时刻 $t+k$ 到 $t+k+1$ 获得的奖励 |
| $\gamma$ | 折扣因子,控制未来奖励在当前判断中的权重 |
| $\mathbf{E}_\pi$ | 对环境随机性和策略随机性取期望 |
Bellman 方程把这段无限长的未来压缩为一步递归:
$$Q^\pi(s,a)= \mathbf{E} [ R_{t+1} + \gamma \sum_{a'} \pi(a'\mid S_{t+1})Q^\pi(S_{t+1},a') \mid S_t=s,A_t=a ]$$
它表达的是:
当前动作的价值,等于眼前奖励,加上下一状态中未来行动价值的折扣期望。
如果寻找的是最优动作价值函数,则有 Bellman 最优方程:
$$Q^(s,a)= \mathbf{E} [ R_{t+1} + \gamma \max_{a'} Q^(S_{t+1},a') \mid S_t=s,A_t=a ]$$
这里最关键的变化是:
$$\sum_{a'}\pi(a'\mid s')Q^\pi(s',a')\quad\longrightarrow\quad \max_{a'}Q^*(s',a')$$
前者问:“按照当前策略行动,未来大概会怎样?”
后者问:“如果未来每一步都选择最有价值的动作,当前动作值多少?”
这就是价值方法的核心野心:不必直接存储一个复杂策略,只要估计好每个动作的长期价值,就可以通过
$$\pi(s)=\arg\max_a Q(s,a)$$
得到行动规则。
二、已知环境时:动态规划在迭代什么
假设环境转移概率 $p(s',r\mid s,a)$ 已知,状态和动作数量也足够小。此时可以直接使用动态规划。
1. Policy Evaluation:评估当前策略
给定策略 $\pi$,反复更新:
$$V_{k+1}(s)= \sum_a \pi(a\mid s)\sum_{s',r} p(s',r\mid s,a)[ r+\gamma V_k(s') ]$$
其中:
| 符号 | 含义 |
|---|---|
| $V_k(s)$ | 第 $k$ 轮迭代时,对状态 $s$ 的价值估计 |
| $\pi(a\mid s)$ | 当前策略在状态 $s$ 选择动作 $a$ 的概率 |
| $p(s',r\mid s,a)$ | 执行动作后到达 $s'$ 并获得奖励 $r$ 的概率 |
每一次迭代,都用上一轮的价值估计重新计算当前状态价值。它已经包含自举。
2. Policy Improvement:让策略偏向更优动作
完成评估后,可以根据动作价值改进策略:
$$\pi_{\mathrm{new}}(s)= \arg\max_a \sum_{s',r} p(s',r\mid s,a)[ r+\gamma V^\pi(s') ]$$
策略评估和策略改进交替进行,构成 Policy Iteration。
3. Value Iteration:把评估和改进压在一起
如果不等待策略被完整评估,而是直接朝最优价值函数迭代:
$$V_{k+1}(s)= \max_a \sum_{s',r} p(s',r\mid s,a)[ r+\gamma V_k(s') ]$$
就得到 Value Iteration。
动态规划揭示了强化学习的基本骨架:
先估计未来,再根据估计改进决策;决策变化后,再重新估计未来。
但动态规划有一个苛刻前提:环境模型必须已知。现实中的机器人、游戏玩家或推荐系统,通常无法提前获得完整的 $p(s',r\mid s,a)$。
于是问题变成:能否只依靠亲自经历过的轨迹学习?
三、Monte Carlo Control:不用自举,先相信完整结局
Monte Carlo 方法等待一个 episode 结束,再计算某个时刻之后真正发生的回报:
$$G_t = R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + \cdots$$
然后用它更新动作价值:
$$Q(S_t,A_t)\leftarrow Q(S_t,A_t)+ \alpha [ G_t-Q(S_t,A_t) ]$$
其中:
| 符号 | 含义 |
|---|---|
| $G_t$ | 从时刻 $t$ 开始实际观察到的完整折扣回报 |
| $\alpha$ | 学习率 |
| $G_t-Q(S_t,A_t)$ | 真实回报与当前估计之间的误差 |
假设一次游戏轨迹中,某个动作之后得到奖励:
$$0,\quad 0,\quad 1$$
取 $\gamma=0.9$,则该动作的回报为:
$$G_t = 0+0.9\times 0+0.9^2\times 1 = 0.81$$
Monte Carlo 方法的优点很直观:它不需要环境模型,也不需要用一个尚未学好的价值估计去教另一个价值估计。
它的缺点同样直观:
- 必须等轨迹结束后才能更新;
- 轨迹越长,回报随机性越大;
- 很难及时把新经验转化为学习信号。
它用“等待完整结局”换取了较少的自举偏差,却付出了高方差和低更新频率。
四、SARSA:每走一步,就更新一步
如果不想等待结局,可以使用一步 TD 目标:
$$Y_t^{\mathrm{SARSA}} = R_{t+1} + \gamma Q(S_{t+1},A_{t+1})$$
更新规则为:
$$Q(S_t,A_t)\leftarrow Q(S_t,A_t)+ \alpha [ R_{t+1} + \gamma Q(S_{t+1},A_{t+1})- Q(S_t,A_t) ]$$
SARSA 的名字来自这五个量:
$$S_t,\ A_t,\ R_{t+1},\ S_{t+1},\ A_{t+1}$$
它在用下一步真实选择的动作 $A_{t+1}$ 更新当前动作价值。
这意味着:如果当前策略带有探索,例如有一定概率随机行动,那么 SARSA 评估的正是这个带探索行为的策略。
悬崖边的差别
想象一个网格世界。最短路径沿着悬崖边缘前进,但探索动作偶尔会让智能体跌落悬崖。
SARSA 会把这种风险计入价值:
$$\mathrm{未来动作可能探索失误} \quad\Rightarrow\quad \mathrm{悬崖边路径价值下降}$$
因此它往往学出更稳妥的路线。
SARSA 是 On-Policy 方法:产生数据的策略和被学习的策略基本一致。
五、Q-Learning:学习一个比行为更贪心的目标
Q-Learning 把下一步真实动作换成最大动作价值:
$$Y_t^{\mathrm{Q}} = R_{t+1} + \gamma \max_{a'} Q(S_{t+1},a')$$
更新规则为:
$$Q(S_t,A_t)\leftarrow Q(S_t,A_t)+ \alpha [ R_{t+1} + \gamma \max_{a'} Q(S_{t+1},a')- Q(S_t,A_t) ]$$
SARSA 与 Q-Learning 的差别只有一处:
$$Q(S_{t+1},A_{t+1})\quad\mathrm{与}\quad \max_{a'}Q(S_{t+1},a')$$
但这处差别改变了问题的性质。
| 方法 | 数据由谁产生 | 更新目标假设未来如何行动 |
|---|---|---|
| SARSA | 当前带探索策略 | 继续按照当前策略行动 |
| Q-Learning | 可以是带探索的行为策略 | 未来选择当前估计中最优的动作 |
Q-Learning 是 Off-Policy 方法。它允许学习者一边用带探索的行为策略采集数据,一边学习一个更贪心的目标策略。
这提高了数据利用的灵活性,却也引入两个风险:
- 最大化操作可能放大估计误差;
- 数据分布与目标策略不再完全一致。
前文讨论过的最大化偏差和分布漂移,已经开始进入系统。
六、从表格走向神经网络
如果状态空间很小,可以为每个 $(s,a)$ 存储一格数值:
| 状态 | 动作左 | 动作右 |
|---|---|---|
| $s_1$ | 0.4 | 0.7 |
| $s_2$ | 0.1 | 0.9 |
但面对图像输入,这种表格迅速失效。屏幕上像素稍有变化,就可能形成一个新状态。
DQN 使用神经网络近似动作价值函数:
$$Q(s,a;\theta)$$
其中:
| 符号 | 含义 |
|---|---|
| $s$ | 当前状态,例如一帧或多帧游戏画面 |
| $a$ | 候选动作 |
| $\theta$ | 神经网络参数 |
| $Q(s,a;\theta)$ | 网络对动作长期价值的估计 |
对离散动作空间,网络通常一次输出所有动作的价值:
$$[ Q(s,a_1;\theta), Q(s,a_2;\theta), \ldots, Q(s,a_m;\theta) ]$$
这让不同状态之间共享表示成为可能。网络不必逐格记忆,它可以学习“前方出现障碍”“角色接近目标”等可复用特征。
但函数逼近也让风险扩大了。
更新一个样本,不再只修改表格中的一格;它会通过共享参数改变许多状态的估计。一个局部误差可能沿着网络参数扩散到整个价值空间。
七、DQN 的损失函数
DQN 使用如下目标:
$$Y_t^{\mathrm{DQN}} = R_{t+1} + \gamma \max_{a'} Q(S_{t+1},a';\theta^-)$$
再最小化平方 TD 误差:
$$\mathcal{L}(\theta)= \mathbf{E}{(s,a,r,s')\sim \mathcal{D}} [ ( r+\gamma\max{a'}Q(s',a';\theta^-)- Q(s,a;\theta))^2 ]$$
其中:
| 符号 | 含义 |
|---|---|
| $\mathcal{D}$ | 经验回放缓冲区 |
| $\theta$ | 正在被梯度下降更新的在线网络参数 |
| $\theta^-$ | 暂时冻结的目标网络参数 |
| $r+\gamma\max_{a'}Q(s',a';\theta^-)$ | 用于训练当前网络的自举目标 |
| $Q(s,a;\theta)$ | 当前网络对已执行动作的估计 |
梯度更新为:
$$\theta \leftarrow \theta - \alpha \nabla_\theta \mathcal{L}(\theta)$$
表面上看,这与监督学习很像:有输入、有目标、有平方误差。
但 DQN 的标签并不是固定答案。标签中的
$$Q(s',a';\theta^-)$$
仍然来自学习者自己的估计。
因此它不是在拟合静态真值,而是在用一个暂时冻结的自己训练另一个自己。
八、经验回放压住什么不稳定
在线交互产生的数据通常高度相关:
$$(S_t,A_t,R_{t+1},S_{t+1}), (S_{t+1},A_{t+1},R_{t+2},S_{t+2}), \ldots$$
连续画面彼此相似,连续动作也受同一段情境影响。如果直接按顺序训练,网络会被近期经验牵着走。
DQN 把转移存入经验回放缓冲区:
$$\mathcal{D} = { (s_i,a_i,r_i,s'i) }{i=1}^{N}$$
训练时随机抽取小批量样本:
$$(s,a,r,s')\sim \operatorname{Uniform}(\mathcal{D})$$
它主要缓解两件事:
- 打散时间相关性;
- 重复利用旧数据,提高样本效率。
但经验回放也会把问题推向 Off-Policy:
缓冲区中的经验来自过去的策略,而当前网络已经发生变化。
于是旧经验既是资产,也是分布漂移的来源。
九、目标网络压住什么不稳定
如果训练目标和被训练的预测都由同一组参数产生:
$$( r+\gamma\max_{a'}Q(s',a';\theta)- Q(s,a;\theta))^2$$
那么每次更新 $\theta$,预测会变化,目标也会变化。学习者像是在追逐一个同步移动的靶子。
DQN 复制出一组目标网络参数:
$$\theta^- \leftarrow \theta$$
但只每隔若干步更新一次。两次同步之间,$\theta^-$ 保持不变。
这样,当前网络暂时拥有一个相对稳定的训练目标:
$$r+\gamma\max_{a'}Q(s',a';\theta^-)$$
目标网络没有消除自举。它只是降低了自举目标变化的速度。
这一区分很重要:
稳定化工具通常不是删除矛盾,而是让矛盾在可控的时间尺度上发生。
十、DQN 中的致命三角
DQN 同时拥有:
- 函数逼近:使用神经网络 $Q(s,a;\theta)$;
- 自举:用下一状态的估计更新当前估计;
- Off-Policy 学习:从经验回放中的旧数据学习。
这正是致命三角。
它不是说 DQN 必然失败,而是说系统具备不稳定的条件。经验回放和目标网络之所以重要,是因为它们分别在不同位置降低风险。
| 风险来源 | 可能发生的问题 | DQN 的应对方式 |
|---|---|---|
| 连续样本相关 | 网络过度追随近期经验 | 随机经验回放 |
| 自举目标快速变化 | 学习目标漂移 | 冻结目标网络 |
| 最大化偏差 | 高估动作价值 | Double DQN 等后续改进 |
| 旧数据分布不一致 | 学到过时或覆盖不足的行为 | 缓冲区设计、探索策略与更新控制 |
DQN 不是终点。它是一种平衡:允许系统在复杂状态空间中学习,同时尽量不让误差传播失控。
十一、价值方法的适用范围与局限
价值方法尤其适合:
- 动作空间离散且规模不太大;
- 能够通过比较动作价值直接选出动作;
- 希望充分复用历史数据;
- 环境交互成本较高,需要较强样本利用率。
它也有明显局限。
1. 连续动作难以直接最大化
如果动作是机械臂关节角度、汽车方向盘角度或连续控制信号,那么:
$$\arg\max_a Q(s,a)$$
本身可能成为困难的优化问题。
2. 随机策略不是自然产物
价值方法通常通过 $\epsilon$-greedy 等外部机制加入探索。策略的随机性更像附加层,而不是目标函数中的原生组成部分。
3. 价值误差会直接变成行动误差
策略通过
$$\arg\max_a Q(s,a)$$
产生。哪怕多个动作价值只差一点,估计顺序一旦出错,行动就会突然切换。
这会把我们带到下一章:
如果不再先学习“每个动作值多少”,而是直接学习“应该如何行动”,会怎样?
十二、演化路径:每一次进步都转移了矛盾
| 方法 | 主要解决的问题 | 引入或暴露的新代价 |
|---|---|---|
| 动态规划 | 在已知模型中计算长期价值 | 需要完整环境模型 |
| Monte Carlo Control | 摆脱已知模型 | 必须等待结局,高方差 |
| SARSA | 允许逐步在线更新 | 使用自举目标,仍受当前探索策略影响 |
| Q-Learning | 可用探索数据学习更贪心的目标策略 | 最大化偏差与 Off-Policy 风险 |
| DQN | 用神经网络处理高维状态 | 函数逼近、自举和旧数据共同放大不稳定 |
| Replay + Target Network | 降低相关性和目标漂移 | 仍未消除分布偏移与估计误差 |
理解这一张表,比背诵算法步骤更重要。
回归全景图(Callback)
现在把 DQN 放回六个坐标轴。
| 维度 | DQN 的回答 | 它没有消除的矛盾 |
|---|---|---|
| 目标 | 最大化折扣累计奖励 | 奖励设计不当仍会把策略带向错误方向 |
| 时间 | 用 Bellman 最优方程把未来压回当前 | 长期信用仍依赖自举估计 |
| 更新 | 最小化平方 TD 误差 | 损失下降不等于真实长期回报必然提高 |
| 估计 | 用目标网络构造 TD 目标 | 目标仍然来自学习者自身,最大化仍可能放大误差 |
| 数据 | 从经验回放中复用历史转移 | 旧数据与当前策略的数据分布不完全一致 |
| 探索 | 常用 $\epsilon$-greedy 采集新经验 | 简单随机探索在稀疏奖励任务中可能效率很低 |
再看三条反馈循环:
| 反馈循环 | DQN 中的具体形式 |
|---|---|
| 外部交互循环 | $\epsilon$-greedy 策略行动,环境返回新转移,新转移进入回放缓冲区 |
| 时间回报循环 | 下一状态最大动作价值通过 Bellman 自举回流到当前动作 |
| 自我更新循环 | 缓冲区样本构造 TD 目标,更新网络,网络改变行为策略,又改变之后采集的数据 |
DQN 的价值不在于消灭了强化学习的困难,而在于把多个困难压缩到一个可以运行、可以调试、可以扩展的工程结构中。
本章小结
价值方法的发展可以概括为一句话:
为了更早更新、更充分利用数据并处理更复杂的状态,学习者逐步接受了自举、Off-Policy 和函数逼近;随后又不得不发明稳定化工具,管理这些选择带来的风险。
DQN 是前文多个主题的第一次完整汇合:
- Bellman 方程负责连接现在与未来;
- TD 误差负责把长期目标变成一次更新;
- Q-Learning 允许行为策略与目标策略分离;
- 神经网络负责跨状态泛化;
- 经验回放与目标网络负责降低不稳定;
- 探索策略负责持续制造新数据。
下一章,我们将换一条路线:不再把策略藏在 $\arg\max Q$ 后面,而是直接学习策略本身。
第 17 章 综合案例二:为什么要直接学习策略
价值方法的行动规则很自然:
$$\pi(s)=\arg\max_a Q(s,a)$$
先估计每个动作值多少,再选价值最高的动作。
但这不是唯一道路。在很多任务中,我们更希望直接学习:
$$\pi_\theta(a\mid s)$$
也就是:在状态 $s$ 下,动作 $a$ 应该以多大概率被选择。
这种路线称为策略梯度方法。它不再把策略藏在动作价值函数后面,而是让策略成为优化对象本身。
这一步看似只是换了一个输出形式,实际上改变了整个学习结构。
一、为什么 $\arg\max Q$ 并不总是理想答案
1. 连续动作空间中的最大化很困难
假设机器人手臂的动作由多个连续关节角度构成:
$$a= [ a_1,a_2,\ldots,a_d ] \in \mathbb{R}^d$$
若使用价值方法,每次行动前都要解:
$$a^* = \arg\max_a Q(s,a)$$
离散动作只有几个按钮时,逐个比较并不困难。但连续动作有无限多种取值,寻找最大值本身就可能是一个昂贵的优化问题。
如果策略网络直接输出动作或动作分布,行动会更简单:
$$a \sim \pi_\theta(\cdot\mid s)$$
2. 某些最优策略本来就需要随机性
在石头剪刀布中,如果永远选择当前看起来最好的动作,对手很快就能利用这种规律。
理想策略不是固定输出一个动作,而是保持某种概率分布:
$$\pi(\mathrm{石头})= \pi(\mathrm{剪刀})= \pi(\mathrm{布})= \frac{1}{3}$$
随机策略不是偶然噪声,而可能是解的一部分。
3. 动作价值的微小误差会造成决策突变
假设两个动作的估计值为:
$$Q(s,a_1)=1.01, \qquad Q(s,a_2)=1.00$$
策略选择 $a_1$。
如果估计略微变化:
$$Q(s,a_1)=0.99, \qquad Q(s,a_2)=1.00$$
动作会突然切换到 $a_2$。
$\arg\max$ 是离散跳变。直接参数化策略则可以让行为变化更加平滑。
二、参数化策略:直接描述如何行动
用参数 $\theta$ 表示策略:
$$\pi_\theta(a\mid s)= \Pr(A_t=a\mid S_t=s;\theta)$$
对离散动作,策略网络通常输出 logits:
$$z_\theta(s) = [ z_1,z_2,\ldots,z_m ]$$
再通过 Softmax 得到动作概率:
$$\pi_\theta(a_i\mid s)= \frac{ \exp(z_i)}{ \sum_{j=1}^{m}\exp(z_j)}$$
其中:
| 符号 | 含义 |
|---|---|
| $z_i$ | 动作 $a_i$ 的未归一化分数 |
| $\exp(z_i)$ | 将分数变为正数 |
| $\sum_j\exp(z_j)$ | 归一化项 |
| $\pi_\theta(a_i\mid s)$ | 最终动作概率 |
例如:
$$z_\theta(s)=[1,2]$$
则:
$$\pi_\theta(a_1\mid s) = \frac{e1}{e1+e^2} \approx 0.269$$
$$\pi_\theta(a_2\mid s) = \frac{e2}{e1+e^2} \approx 0.731$$
策略网络不是直接宣布“动作二价值更高”,而是给出“动作二更可能被选择”。
三、我们究竟要优化什么
一条轨迹记为:
$$\tau = (S_0,A_0,R_1,S_1,A_1,R_2,\ldots)$$
轨迹回报可以写成:
$$R(\tau) = \sum_{t=0}^{T-1} \gamma^t R_{t+1}$$
策略优化目标为:
$$J(\theta) = E_{\tau \sim \pi_\theta} [ R(\tau) ]$$
这句话的含义很直接:
调整策略参数,使它产生的轨迹拥有更高的期望长期回报。
展开期望:
$$J(\theta)= \sum_\tau p_\theta(\tau)R(\tau)$$
其中,$p_\theta(\tau)$ 是策略 $\pi_\theta$ 产生轨迹 $\tau$ 的概率。
对参数求梯度:
$$\nabla_\theta J(\theta)= \sum_\tau \nabla_\theta p_\theta(\tau)R(\tau)$$
真正的难点出现了:环境可能不可微,轨迹又是随机采样出来的。如何得到可用梯度?
四、Log-Derivative Trick:把概率梯度写成对数概率梯度
利用恒等式:
$$\nabla_\theta p_\theta(\tau)= p_\theta(\tau)\nabla_\theta \log p_\theta(\tau)$$
可以改写目标梯度:
$$\nabla_\theta J(\theta)= \sum_\tau p_\theta(\tau)\nabla_\theta \log p_\theta(\tau)R(\tau)$$
也就是:
$$\nabla_\theta J(\theta)=E_{\tau \sim \pi_\theta}\big[\nabla_\theta \log p_\theta(\tau) R(\tau)\big]$$
轨迹概率可以拆成:
$$p_\theta(\tau)= \rho_0(S_0)\prod_{t=0}^{T-1} \pi_\theta(A_t\mid S_t)p(S_{t+1}\mid S_t,A_t)$$
其中:
| 因子 | 含义 |
|---|---|
| $\rho_0(S_0)$ | 初始状态分布 |
| $\pi_\theta(A_t\mid S_t)$ | 策略选择动作的概率 |
| $p(S_{t+1}\mid S_t,A_t)$ | 环境转移概率 |
取对数后,乘法变成加法:
$$\log p_\theta(\tau)= \log\rho_0(S_0)+ \sum_{t=0}^{T-1} \log \pi_\theta(A_t\mid S_t)+ \sum_{t=0}^{T-1} \log p(S_{t+1}\mid S_t,A_t)$$
对 $\theta$ 求梯度时,初始状态分布与环境转移概率都不依赖策略参数,因此消失:
$$\nabla_\theta \log p_\theta(\tau)= \sum_{t=0}^{T-1} \nabla_\theta \log \pi_\theta(A_t\mid S_t)$$
代回原式:
$$\nabla_\theta J(\theta) = E_{\tau \sim \pi_\theta} [ \sum_{t=0}^{T-1} \nabla_\theta \log \pi_\theta(A_t | S_t) R(\tau) ]$$
这是一个关键结果:
即使不知道环境如何求导,也可以通过“动作的对数概率”与“轨迹回报”的乘积,估计策略更新方向。
五、REINFORCE:奖励好的动作,提高其出现概率
REINFORCE 使用从当前时刻开始的回报:
$$G_t = \sum_{k=t}^{T-1} \gamma^{k-t}R_{k+1}$$
梯度估计写成:
$$\widehat{\nabla_\theta J(\theta)} = \sum_{t=0}^{T-1} \gamma^t G_t \nabla_\theta \log \pi_\theta(A_t\mid S_t)$$
参数沿梯度上升方向更新:
$$\theta \leftarrow \theta + \alpha \sum_{t=0}^{T-1} \gamma^t G_t \nabla_\theta \log \pi_\theta(A_t\mid S_t)$$
其中:
| 符号 | 含义 |
|---|---|
| $G_t$ | 动作 $A_t$ 之后实际观察到的回报 |
| $\log \pi_\theta(A_t\mid S_t)$ | 当前策略赋予已执行动作的对数概率 |
| $\nabla_\theta\log \pi_\theta(A_t\mid S_t)$ | 怎样调整参数才能提高该动作的概率 |
| $\alpha$ | 学习率 |
这里显式保留了 $\gamma^t$,因为本章从起点时刻的折扣目标 $R(\tau)$ 出发。在另一种常见写法中,时间权重会被状态采样分布吸收,因此也经常看到省略 $\gamma^t$ 的形式。
如果 $G_t$ 较大,就增强该动作在相似状态下出现的概率。
如果 $G_t$ 较小甚至为负,就削弱该动作的概率。
在代码中,常常把梯度上升改写成最小化负号形式的代理损失:
$$L_{REIN}(\theta)=-E[\gamma^t G_t \log \pi_\theta(A_t|S_t)]$$
这又一次说明:强化学习中的“损失函数”往往是更新装置,不是最终目标本身。
六、为什么直接使用回报会有高方差
考虑两条几乎相同的轨迹。它们在早期都执行了动作 $a$,但因为后续环境随机性不同,最终回报分别为:
$$G_t^{(1)}=10, \qquad G_t^{(2)}=-2$$
同一个早期动作,第一次被大力鼓励,第二次又被明显抑制。
问题在于:
完整回报不仅包含当前动作的贡献,也混合了之后所有动作和环境随机性的影响。
REINFORCE 不使用自举,减少了一类估计偏差,却承受了较高方差。
这与 Monte Carlo 价值估计面临的是同一种代价。
七、Baseline:只奖励“比预期更好”的动作
可以从回报中减去一个只依赖状态的基线 $b(S_t)$:
$$\widehat{\nabla_\theta J(\theta)} = \sum_t \gamma^t [ G_t-b(S_t)] \nabla_\theta \log \pi_\theta(A_t\mid S_t)$$
最常见选择是状态价值函数:
$$b(S_t)=V^\pi(S_t)$$
于是:
$$G_t-V^\pi(S_t)$$
表示这次行动结果比通常预期好多少。
Baseline 为什么不会改变期望梯度
关键是 $b(s)$ 不依赖当前动作。对固定状态 $s$:
$$\mathbf{E}{A \sim \pi\theta} [ b(s)\nabla_\theta \log \pi_\theta(A\mid s) ]$$
$$= b(s)\sum_a \pi_\theta(a\mid s)\nabla_\theta \log \pi_\theta(a\mid s)$$
由于:
$$\pi_\theta(a\mid s)\nabla_\theta \log \pi_\theta(a\mid s)= \nabla_\theta \pi_\theta(a\mid s)$$
所以:
$$b(s)\sum_a \nabla_\theta \pi_\theta(a\mid s)= b(s)\nabla_\theta \sum_a \pi_\theta(a\mid s)$$
而动作概率之和恒为 $1$:
$$\sum_a\pi_\theta(a\mid s)=1$$
因此:
$$b(s)\nabla_\theta 1=0$$
baseline 不会改变期望梯度,只会降低梯度估计的方差。
这是一种很漂亮的工程思想:
不改变长期目标,只减少更新中的无谓摇摆。
八、Advantage Function:相对好坏比绝对分数更重要
优势函数定义为:
$$A^\pi(s,a)= Q\pi(s,a)-V\pi(s)$$
其中:
| 符号 | 含义 |
|---|---|
| $Q^\pi(s,a)$ | 在状态 $s$ 执行动作 $a$ 后的长期价值 |
| $V^\pi(s)$ | 在状态 $s$ 按当前策略行动的平均长期价值 |
| $A^\pi(s,a)$ | 动作 $a$ 相对当前平均水平好多少 |
假设某个状态中:
$$V^\pi(s)=8$$
两个动作价值为:
$$Q^\pi(s,a_1)=10, \qquad Q^\pi(s,a_2)=7$$
则:
$$A^\pi(s,a_1)=2$$
$$A^\pi(s,a_2)=-1$$
动作 $a_1$ 应该被鼓励,动作 $a_2$ 应该被抑制。
策略梯度定理常写为:
$$\nabla_\theta J(\theta)\propto \mathbf{E}{S\sim d^\pi,\ A \sim \pi\theta} [ Q^\pi(S,A)\nabla_\theta \log \pi_\theta(A\mid S) ]$$
减去 baseline 后,也可以写成:
$$\nabla_\theta J(\theta)\propto \mathbf{E} [ A^\pi(S,A)\nabla_\theta \log \pi_\theta(A\mid S) ]$$
其中 $d^\pi$ 表示当前策略诱导出的状态访问分布。
这条公式揭示了策略梯度的核心:
提高优势为正的动作概率,降低优势为负的动作概率。
九、连续动作空间:策略可以直接输出分布
对连续动作,可以令策略输出高斯分布参数:
$$\pi_\theta(a\mid s)= \mathcal{N} ( a; \mu_\theta(s), \sigma_\theta^2(s))$$
其中:
| 符号 | 含义 |
|---|---|
| $\mu_\theta(s)$ | 状态 $s$ 下动作分布的均值 |
| $\sigma_\theta(s)$ | 动作分布的标准差 |
| $\mathcal{N}$ | 高斯概率密度 |
例如,机械臂在当前状态下输出:
$$\mu_\theta(s)=0.4, \qquad \sigma_\theta(s)=0.1$$
策略会在 $0.4$ 附近采样动作,而不是从无限多动作中重新求解一次 $\arg\max$。
标准差还天然表达探索强度:
$$\sigma_\theta(s)\ \mathrm{较大} \quad\Rightarrow\quad \mathrm{尝试范围更广}$$
$$\sigma_\theta(s)\ \mathrm{较小} \quad\Rightarrow\quad \mathrm{行动更集中}$$
探索不再只是外挂的随机按钮,而可以成为策略表示的一部分。
十、策略梯度解决了什么,又牺牲了什么
| 方面 | 直接学习策略的优势 | 对应代价 |
|---|---|---|
| 连续动作 | 可以直接输出连续动作分布 | 策略更新可能不稳定 |
| 随机策略 | 随机性天然进入策略表示 | 需要管理探索强度与熵 |
| 优化形式 | 可以直接朝期望长期回报优化 | 梯度估计通常方差较高 |
| 数据利用 | On-Policy 形式清晰 | 旧数据不容易直接复用 |
| 行为变化 | 概率分布可平滑调整 | 步长过大仍可能造成性能突然下降 |
尤其需要注意最后一点。
策略决定数据分布。当参数变化后:
$$\theta \longrightarrow \pi_\theta \longrightarrow d^{\pi_\theta}$$
新的策略会访问新的状态,采集新的数据。如果一次更新太激进,策略可能离开熟悉区域,进入估计器并不了解的状态空间。
因此,后续方法会反复讨论一个主题:
如何让策略改进足够明显,但又不要一步走得太远?
十一、边界:策略梯度不是“对真实回报直接反向传播”
策略梯度容易引发一种误解:既然最终目标是长期回报,那么是不是可以像监督学习一样,从最终奖励一路反向传播到每个动作?
通常不能。
环境转移未必可微,动作采样也可能是离散的。策略梯度使用的是概率技巧:
$$\nabla_\theta\log \pi_\theta(A_t\mid S_t)$$
它并没有要求对环境本身求导。
另一种误解是:策略梯度绕过了价值估计。
最基础的 REINFORCE 确实可以只使用实际回报。但为了降低方差,实际系统通常会引入 baseline、优势函数或 Critic。于是价值估计会重新回到系统中。
它没有消失,而是换了位置。
回归全景图(Callback)
把策略梯度放回六个坐标轴:
| 维度 | 策略梯度的回答 | 它没有消除的矛盾 |
|---|---|---|
| 目标 | 直接最大化策略产生轨迹的期望回报 $J(\theta)$ | 奖励是否真正表达意图仍然是外部问题 |
| 时间 | 用完整回报或优势把未来结果分配给早期动作 | 长期轨迹会带来高方差和信用分配困难 |
| 更新 | 用 $\nabla_\theta\log \pi_\theta(a\mid s)$ 构造代理梯度 | 代理损失下降不保证每次策略更新都提高真实性能 |
| 估计 | REINFORCE 可使用 Monte Carlo 回报,baseline 可降低方差 | 低偏差往往伴随高方差,引入价值估计后又会增加偏差 |
| 数据 | 通常使用当前策略采集的数据 | On-Policy 数据更新后迅速过时,样本利用率有限 |
| 探索 | 随机策略和动作分布天然表达探索 | 探索程度仍需设计,过强与过弱都会损害学习 |
再看三条反馈循环:
| 反馈循环 | 策略梯度中的具体形式 |
|---|---|
| 外部交互循环 | 策略采样动作,环境返回轨迹和奖励 |
| 时间回报循环 | 轨迹后段的奖励通过 $G_t$ 或优势回到早期动作 |
| 自我更新循环 | 回报加权对数概率梯度更新策略,策略变化后重新定义未来数据分布 |
策略梯度把策略放到了舞台中央,却没有摆脱估计问题。恰恰相反,它很快提出一个新需求:
能否专门训练一个评价者,帮助行动者更稳定地判断哪些动作值得加强?
本章小结
直接学习策略的逻辑可以浓缩为四步:
- 用 $\pi_\theta(a\mid s)$ 描述行动概率;
- 用长期回报 $J(\theta)$ 定义最终目标;
- 用 Log-Derivative Trick 把不可微环境中的轨迹采样变成可估计的策略梯度;
- 用 baseline 或 advantage 降低更新方差。
它解决了连续动作和随机策略的表达问题,也让策略本身可以被直接优化。
但 REINFORCE 的梯度仍然摇摆很大,数据利用率也不高。
下一章,Actor-Critic 会把两条路线重新合并:Actor 负责行动,Critic 负责判断行动相对预期究竟好不好。
第 18 章 综合案例三:Actor-Critic 如何让行动者与评价者合作
策略梯度提供了一种直接而优雅的想法。忽略可由采样约定吸收的时间权重,单步更新可以简写为:
$$\theta \leftarrow \theta + \alpha G_t \nabla_\theta \log \pi_\theta(A_t\mid S_t)$$
如果一次行动之后的回报较高,就增加这类行动再次发生的概率。
但完整回报 $G_t$ 混合了太多因素:后续动作、环境随机性、轨迹长度和奖励噪声都会让更新剧烈摇摆。
于是,一个自然问题出现了:
能否安排一个评价者,专门判断当前动作比通常水平好多少,再由行动者根据这个判断调整策略?
这就是 Actor-Critic。
- Actor 是行动者:负责输出策略;
- Critic 是评价者:负责估计价值或优势;
- Actor 根据 Critic 的反馈更新;
- Critic 又根据 Actor 采集的新数据更新。
这不是单向流水线,而是一个相互依赖的反馈系统。
图 18-1:Actor-Critic 双循环
一、为什么 Actor 需要 Critic
在 REINFORCE 中,动作的权重可以使用完整回报:
$$G_t = R_{t+1} + \gamma R_{t+2} + \cdots + \gamma^{T-t-1}R_T$$
如果 episode 很长,学习者必须等待很久,才能知道早期动作是否值得鼓励。
Critic 尝试提前回答这个问题。
它可以估计状态价值:
$$V_w(s)\approx V^\pi(s)$$
其中 $w$ 是 Critic 的参数。
也可以估计动作价值:
$$Q_w(s,a)\approx Q^\pi(s,a)$$
或直接估计优势:
$$A_w(s,a)\approx A^\pi(s,a)$$
Critic 的作用不是替代奖励,而是把延迟奖励翻译成更及时的学习信号。
二、一步 TD 误差:把 Critic 的判断压缩成一个数
如果 Critic 估计状态价值,可以构造一步 TD 目标:
$$Y_t = R_{t+1} + \gamma V_w(S_{t+1})$$
TD 误差为:
$$\delta_t = R_{t+1} + \gamma V_w(S_{t+1})- V_w(S_t)$$
其中:
| 项 | 含义 |
|---|---|
| $R_{t+1}$ | 当前动作带来的即时奖励 |
| $\gamma V_w(S_{t+1})$ | 对下一状态未来价值的折扣估计 |
| $V_w(S_t)$ | 行动前对当前状态的预期 |
| $\delta_t$ | 实际进展相对原先预期好多少 |
如果:
$$\delta_t>0$$
说明结果比预期好,当前动作应被鼓励。
如果:
$$\delta_t<0$$
说明结果比预期差,当前动作应被抑制。
在适当条件下,一步 TD 误差可以看作优势函数的带噪估计:
$$\delta_t \approx A^\pi(S_t,A_t)$$
于是 Actor 可以更新:
$$\theta \leftarrow \theta + \alpha_\theta \delta_t \nabla_\theta \log \pi_\theta(A_t\mid S_t)$$
Critic 则最小化价值误差:
$$\mathcal{L}{\mathrm{critic}}(w)= \frac{1}{2} [ R{t+1} + \gamma V_w(S_{t+1})- V_w(S_t) ]^2$$
更新:
$$w \leftarrow w - \alpha_w \nabla_w \mathcal{L}_{\mathrm{critic}}(w)$$
Actor 和 Critic 在同一条转移上各自学习,但承担不同职责。
三、Critic 如何降低方差
假设一个状态的平均回报大约为:
$$V^\pi(s)=100$$
两次轨迹得到:
$$G_t^{(1)}=102, \qquad G_t^{(2)}=98$$
如果直接使用完整回报,更新权重是 $102$ 和 $98$。两次都像是很强的正向信号。
减去状态价值后:
$$G_t^{(1)} - V^\pi(s) = 2$$
$$G_t^{(2)} - V^\pi(s) = -2$$
含义清楚多了:第一次略好于预期,第二次略差于预期。
Critic 将绝对分数变成相对改进信号,使 Actor 不必被回报整体尺度牵着走。
如果使用一步 TD 误差,更新还可以更及时:
$$\delta_t = R_{t+1} + \gamma V_w(S_{t+1})- V_w(S_t)$$
不用等待完整轨迹结束,走一步就能学一步。
代价也随之出现:$V_w(S_{t+1})$ 是估计值,不是真实未来。
四、Critic 的误差如何误导 Actor
假设某个动作真实优势为:
$$A^\pi(s,a)=-1$$
它其实比平均水平差。
但 Critic 因为样本不足或函数逼近误差,给出:
$$\widehat{A}(s,a)=+3$$
Actor 就会错误地提高这个动作的概率:
$$\theta \leftarrow \theta + \alpha_\theta \cdot 3 \cdot \nabla_\theta \log \pi_\theta(a\mid s)$$
新策略会更频繁地执行坏动作,又会采集到一批受错误策略影响的数据。
于是形成反馈:
$$\mathrm{Critic 估计偏差} \longrightarrow \mathrm{Actor 错误更新} \longrightarrow \mathrm{数据分布变化} \longrightarrow \mathrm{Critic 继续在偏移后的数据上学习}$$
Actor-Critic 提高了效率,也让估计误差拥有了更短的传播路径。
因此,学习率、目标网络、优势估计、策略更新约束和数据采样方式都不是次要细节。它们决定双循环能否保持稳定。
五、n 步回报与 GAE:在偏差和方差之间选位置
一步 TD 误差更新及时,但依赖较强自举:
$$\delta_t = R_{t+1} + \gamma V(S_{t+1})- V(S_t)$$
完整回报自举少,但方差较高。
可以使用 $n$ 步回报:
$$G_t^{(n)} = R_{t+1} + \gamma R_{t+2} + \cdots + \gamma^{n-1}R_{t+n} + \gamma^n V(S_{t+n})$$
其中:
| 选择 | 特点 |
|---|---|
| $n=1$ | 更新快,自举强,方差较低,偏差可能较大 |
| $n$ 较大 | 使用更多真实奖励,偏差通常降低,方差通常提高 |
| 直到轨迹结束 | 退化为 Monte Carlo 回报 |
PPO 等方法常使用广义优势估计 GAE:
$$\hat A_t^{GAE(\gamma,\lambda)} = \sum_{l=0}^\infty (\gamma\lambda)^l \delta_{t+l}$$
其中:
| 符号 | 含义 |
|---|---|
| $\delta_{t+l}$ | 从时刻 $t+l$ 开始的一步 TD 误差 |
| $\gamma$ | 折扣因子 |
| $\lambda$ | 在短期 TD 与长期回报之间调节权衡 |
$\lambda$ 较小时,更依赖短期自举;$\lambda$ 较大时,更接近较长回报。
GAE 没有发明一条没有代价的估计。它只是提供了一只更精细的旋钮。
六、A2C 与 A3C:并行采样改变了什么
Actor-Critic 的一个现实问题是:连续轨迹中的样本高度相关。
A3C 使用多个异步工作者:
$$\mathrm{Worker}_1,\mathrm{Worker}_2,\ldots,\mathrm{Worker}_n$$
每个工作者在自己的环境副本中采样,然后异步更新共享参数。
不同环境副本产生的轨迹可以降低数据相关性,也提高采样吞吐量。
A2C 可以理解为同步版本:多个工作者并行采样一段轨迹,再汇总梯度统一更新。
| 方法 | 更新方式 | 直观特点 |
|---|---|---|
| A3C | 异步更新 | 更新更灵活,但并发带来参数时延 |
| A2C | 同步批量更新 | 工程结构更规整,更适合批量计算 |
它们没有改变 Actor-Critic 的基本原理,只是重新组织数据产生与参数更新的节奏。
七、DDPG:连续控制中的确定性 Actor
对于连续动作,可以让 Actor 直接输出确定性动作:
$$a=\mu_\theta(s)$$
Critic 估计:
$$Q_w(s,a)$$
Actor 的目标是选择能让 Critic 给出高价值的动作:
$$J(\theta)=E_{s \sim D}[Q_w(s,\mu_\theta(s))]$$
利用链式法则:
$$\nabla_{\theta} J(\theta) \approx E_{s \sim D}( \nabla_{a} Q_{w}(s, \mu_{\theta}(s)) \nabla_{\theta} \mu_{\theta}(s) )$$
这条公式表达:
- Critic 告诉 Actor,动作朝哪个方向变化会提高价值;
- Actor 再调整参数,让输出动作沿该方向移动。
DDPG 还使用经验回放和目标网络,因此可以复用旧数据。
它适合连续控制,却也较敏感:如果 Critic 对某些动作过度乐观,Actor 会主动追逐这些估计漏洞。
八、TD3:防止 Actor 追逐价值幻觉
TD3 针对 DDPG 的价值高估问题加入多项修正,其中最具代表性的是双 Critic:
$$Q_{w_1}(s,a), \qquad Q_{w_2}(s,a)$$
构造目标时取较小值:
$$Y_t^{\mathrm{TD3}} = R_{t+1} + \gamma \min_{i\in{1,2}} Q_{w_i^-} ( S_{t+1}, \mu_{\theta^-}(S_{t+1})+\epsilon )$$
其中:
| 符号 | 含义 |
|---|---|
| $w_i^-$ | 第 $i$ 个目标 Critic 参数 |
| $\theta^-$ | 目标 Actor 参数 |
| $\epsilon$ | 加在目标动作上的小扰动 |
| $\min$ | 取两个估计中更保守的一个 |
为什么取较小值?
如果其中一个 Critic 对某个动作产生偶然高估,另一个 Critic 未必同时犯同样错误。取较小值可以减少 Actor 追逐虚假高峰的机会。
TD3 还会延迟 Actor 更新,让 Critic 多学习几步之后再指导策略变化。
它没有让估计变成真值,而是限制错误估计影响 Actor 的速度。
九、SAC:把探索写进目标函数
SAC 使用最大熵目标:
$$J(\pi) = E_{\tau \sim \pi}( \sum_{t=0}^{T-1} \gamma^{t} ( R_{t+1} + \alpha \mathcal{H}( \pi(\cdot | S_{t}) ) ) )$$
其中:
| 符号 | 含义 |
|---|---|
| $\mathcal{H}(\pi(\cdot\mid S_t))$ | 状态 $S_t$ 下策略分布的熵 |
| $\alpha$ | 奖励与熵之间的权衡系数 |
策略熵定义为:
$$\mathcal{H} ( \pi(\cdot\mid s))= - \mathbf{E}_{a \sim \pi} [ \log \pi(a\mid s) ]$$
SAC 不只鼓励高奖励动作,还鼓励策略在有价值的区域保留多样性。
直观地说,它希望策略做到:
既追求收益,也不要过早变得僵硬。
这对连续控制和多峰动作空间尤其有帮助。
但熵奖励也带来新问题:$\alpha$ 太大,策略可能长期过于随机;$\alpha$ 太小,又可能过早收缩。
十、PPO:用局部约束限制策略突变
策略梯度面临一个核心风险:一次更新太大,策略就会离开旧数据能够可靠解释的区域。
PPO 使用新旧策略概率比:
$$r_t(\theta)= \frac{ \pi_\theta(A_t\mid S_t)}{ \pi_{\theta_{\mathrm{old}}}(A_t\mid S_t)}$$
如果:
$$r_t(\theta)=1$$
说明新旧策略对已执行动作赋予相同概率。
如果:
$$r_t(\theta)>1$$
说明新策略提高了该动作概率。
PPO 的裁剪代理目标为:
$$\mathcal{L}^{\mathrm{CLIP}}(\theta)= \mathbf{E}_t [ \min ( r_t(\theta)\widehat{A}_t, \operatorname{clip} ( r_t(\theta), 1-\epsilon, 1+\epsilon )\widehat{A}_t ) ]$$
其中:
| 符号 | 含义 |
|---|---|
| $\widehat{A}_t$ | 动作相对预期好坏的优势估计 |
| $r_t(\theta)$ | 新旧策略对该动作概率的比值 |
| $\epsilon$ | 允许概率比变化的局部范围 |
| $\operatorname{clip}$ | 把比值截断在 $[1-\epsilon,1+\epsilon]$ 区间内 |
例如:
$$\epsilon=0.2$$
则裁剪区间为:
$$[0.8,1.2]$$
当优势为正时,算法希望提高该动作概率;但提高到一定程度后,继续增大概率不再获得额外收益。
当优势为负时,算法希望降低该动作概率;但降低太多同样会被截断。
PPO 的思想不是禁止策略变化,而是:
在旧数据仍然有解释力的局部范围内,完成一轮有限度的改进。
十一、为什么 Actor-Critic 成为主流框架
Actor-Critic 不是某一个算法,而是一类架构。
它能容纳许多选择:
| 设计位置 | 可选方案 |
|---|---|
| Actor 形式 | 离散随机策略、连续高斯策略、确定性策略 |
| Critic 形式 | $V(s)$、$Q(s,a)$、双 Q 网络 |
| 优势估计 | 一步 TD、$n$ 步回报、GAE |
| 数据方式 | On-Policy 采样、经验回放、并行环境 |
| 探索机制 | 策略随机性、熵奖励、动作噪声 |
| 更新约束 | 目标网络、延迟更新、概率比裁剪 |
这也是它广泛适用的原因:行动与评价被拆开后,每个部分都能针对具体任务调整。
但模块化不等于简单化。
Actor-Critic 的真正难点是:多个组件通过反馈循环耦合。任意一个环节的误差,都可能被另一个环节放大。
十二、边界:协作并不意味着彼此可信
Actor 和 Critic 的名字容易让人产生拟人化想象:一个负责行动,一个负责给出可靠评价。
实际上,Critic 并不天然可靠。它只是一个同样处于训练过程中的估计器。
Actor 也不是被动接受建议。它会主动寻找 Critic 认为价值高的动作。如果 Critic 的价值地形存在漏洞,Actor 往往会发现并利用它们。
所以 Actor-Critic 的关系更接近:
一个不断变化的行动者,与一个尚未完全学会评价的评价者,在共同制造的数据上互相塑造。
这正是强化学习最典型的反馈系统。
回归全景图(Callback)
把 Actor-Critic 放回六个坐标轴:
| 维度 | Actor-Critic 的回答 | 它没有消除的矛盾 |
|---|---|---|
| 目标 | Actor 朝更高长期回报更新,SAC 等方法还加入熵目标 | 奖励、熵和约束之间仍需权衡 |
| 时间 | Critic 用 TD、$n$ 步回报或 GAE 进行信用分配 | 短期自举与长期高方差之间仍无免费答案 |
| 更新 | Actor 使用优势加权策略梯度,Critic 最小化价值误差 | 两个更新过程彼此耦合,学习率和更新节奏很重要 |
| 估计 | Critic 把延迟奖励转为及时反馈 | Critic 偏差会直接误导 Actor |
| 数据 | A2C/A3C 使用并行 On-Policy 数据,DDPG/TD3/SAC 可复用旧数据 | 不同数据机制分别面临样本效率或分布漂移问题 |
| 探索 | 随机策略、动作噪声或熵正则提供探索 | 探索强度仍可能过早收缩或过度发散 |
再看三条反馈循环:
| 反馈循环 | Actor-Critic 中的具体形式 |
|---|---|
| 外部交互循环 | Actor 采取动作,环境返回奖励与下一状态,新数据反过来改变 Actor 和 Critic |
| 时间回报循环 | Critic 用未来价值估计构造 TD 信号,回传到当前动作 |
| 自我更新循环 | Critic 评价 Actor,Actor 改变数据分布,新数据又重塑 Critic |
Actor-Critic 没有彻底消解任何根本矛盾。它的贡献是重新分工:
- Actor 专门承担“如何行动”;
- Critic 专门承担“如何估计”;
- 稳定化工具专门管理两者之间的误差传播。
本章小结
Actor-Critic 是前面两条路线的汇合:
- 价值方法提供评价能力;
- 策略梯度提供直接优化行动的能力;
- TD 误差与优势函数连接两者;
- GAE 在偏差与方差之间调节位置;
- TD3 降低 Actor 追逐价值幻觉的风险;
- SAC 把探索写入目标;
- PPO 限制策略一次走得太远。
它强大,不是因为它没有矛盾,而是因为它能把矛盾分解到不同模块中分别管理。
下一章,我们再向外看一步:如果智能体不仅学习策略和价值,还学习一个可以用于推演的世界模型,会发生什么?
第 19 章 综合案例四:学习策略,还是学习世界
前面的算法大多在做一件事:从真实交互中学习如何行动。
DQN 学习动作价值:
$$Q(s,a)$$
策略梯度学习行动概率:
$$\pi_\theta(a\mid s)$$
Actor-Critic 同时学习策略与价值:
$$\pi_\theta(a\mid s), \qquad V_w(s)\ \mathrm{或}\ Q_w(s,a)$$
但还有另一条道路:
与其只学习“在这个世界中怎样行动”,能否同时学习“这个世界如何运转”?
如果智能体拥有一个近似环境模型,它就可以在真正行动之前,先在内部推演多个未来。
这就是 Model-Based Reinforcement Learning 的基本想法。
一、Model-Free 与 Model-Based 的分界
环境可以用状态转移和奖励机制描述:
$$p(s',r\mid s,a)$$
它回答:
在状态 $s$ 执行动作 $a$ 后,以多大概率到达状态 $s'$ 并获得奖励 $r$?
Model-Free 方法不显式学习这个环境模型。它直接学习价值函数或策略:
$$Q(s,a)\quad\mathrm{或}\quad \pi(a\mid s)$$
Model-Based 方法则尝试学习近似模型:
$$\widehat{p}_\phi(s',r\mid s,a)$$
其中 $\phi$ 是模型参数。
为了便于理解,也可以拆成两部分:
$$\widehat{s}' = f_\phi(s,a)$$
$$\widehat{r} = g_\phi(s,a)$$
其中:
| 符号 | 含义 |
|---|---|
| $f_\phi$ | 预测执行动作后的下一状态 |
| $g_\phi$ | 预测执行动作后的奖励 |
| $\widehat{s}'$ | 模型想象出的下一状态 |
| $\widehat{r}$ | 模型想象出的奖励 |
两类方法的核心区别不在于是否使用神经网络,而在于:
学习者是否显式构造了一个可用于预测或规划的环境模型。
二、为什么学习环境模型可能提高样本效率
真实交互通常很贵。
- 机器人摔倒会损坏硬件;
- 自动驾驶测试需要安全保障;
- 工业控制试错可能造成生产损失;
- 与真人用户交互需要时间和成本。
如果每次策略更新都必须重新向真实环境索取大量数据,学习会非常昂贵。
一个近似模型可以让经验被重复利用。
给定状态 $s_t$ 和候选动作 $a_t$,模型可以预测:
$$\hat s_{t+1}\sim \hat p_\phi(\cdot|s_t,a_t)$$
再从 $\widehat{s}_{t+1}$ 继续推演:
$$\hat s_{t+2}\sim \hat p_\phi(\cdot|\hat s_{t+1},a_{t+1})$$
这样,学习者可以在内部比较多种行动序列:
$$(a_t,a_{t+1},\ldots,a_{t+H-1})$$
而不是每一种方案都亲自执行一次。
模型的价值在于:
它把一部分现实试错变成内部推演。
三、Planning:先推演,再行动
假设已知或学到了模型,可以使用近似 Bellman 更新:
$$\widehat{Q}(s,a)= \widehat{r}(s,a)+ \gamma \sum_{s'} \widehat{p}(s'\mid s,a)\max_{a'} \widehat{Q}(s',a')$$
这个公式与前面的 Bellman 最优方程结构相同,只是环境模型换成了估计值。
在连续或复杂空间中,通常不会穷举全部未来,而会有限深度推演:
$$\hat G_{t:t+H}=\sum_{k=0}^{H-1} \gamma^k \hat R_{t+k+1}+\gamma^H V(\hat S_{t+H})$$
其中:
| 符号 | 含义 |
|---|---|
| $H$ | 想象轨迹的规划深度 |
| $\widehat{R}_{t+k+1}$ | 模型预测的奖励 |
| $\widehat{S}_{t+H}$ | 模型推演到第 $H$ 步的状态 |
| $V(\widehat{S}_{t+H})$ | 在推演末端使用价值函数补上更远未来 |
这又是一种截断:
- 前 $H$ 步依靠模型显式推演;
- $H$ 步之后依靠价值函数近似压缩。
规划不是凭空预知未来,而是在计算预算与估计误差之间选择一个推演深度。
四、Dyna:真实经验与模拟经验一起训练
Dyna 提供了一种经典组合方式。
每当智能体获得一条真实转移:
$$(S_t,A_t,R_{t+1},S_{t+1})$$
它做三件事:
- 用真实转移更新价值函数或策略;
- 用真实转移更新环境模型;
- 从模型中生成模拟转移,继续更新价值函数或策略。
可以写成:
$$\mathrm{真实经验} \longrightarrow \begin{cases} \mathrm{更新策略或价值}\ \mathrm{更新环境模型} \end{cases}$$
$$\mathrm{环境模型} \longrightarrow \mathrm{模拟经验} \longrightarrow \mathrm{继续更新策略或价值}$$
假设真实环境只提供了一次经验:
$$(s_1,a_1,r=1,s_2)$$
模型学到这条转移后,可以在后续规划阶段重复使用它,甚至把它和其他已学转移组合起来,推演更长路径。
Dyna 的关键不在于某个特定网络,而在于它把两种数据放进同一个学习系统:
| 数据类型 | 来源 | 优点 | 风险 |
|---|---|---|---|
| 真实经验 | 环境交互 | 可信度较高 | 昂贵、数量有限 |
| 模拟经验 | 学到的模型 | 便宜、可重复生成 | 可能携带模型偏差 |
五、Model Bias:想象为什么可能把策略带偏
模型式方法最危险的地方也来自它最诱人的地方:模型可以生成大量模拟经验。
如果模型存在一点误差:
$$\widehat{s}{t+1} = s{t+1} + \varepsilon_t$$
下一步预测会建立在已经偏移的状态上:
$$\widehat{s}{t+2} = f\phi ( s_{t+1}+\varepsilon_t, a_{t+1} )$$
随着推演变长,误差可能累积。
设单步误差规模大致为 $\varepsilon$,在最简单的直观近似下,$H$ 步推演误差可能随深度增加:
$$\mathrm{累计误差} \approx O(H\varepsilon)$$
在非线性系统中,它甚至可能增长得更快。
更麻烦的是,策略会主动寻找模型中的高回报路径。
如果模型错误地认为某个现实中不可行的动作序列收益很高,规划器可能反复选择这条路径。
于是形成:
$$\mathrm{模型微小漏洞} \longrightarrow \mathrm{规划器主动放大} \longrightarrow \mathrm{策略偏向虚假高回报区域}$$
这与 Actor 追逐 Critic 的价值幻觉非常相似。
模型不是世界本身。它只是另一个估计器。
六、Imagination Rollout:想象多远才合适
想象轨迹可以用于更新策略或价值函数:
$$\widehat{\tau} = ( \widehat{S}_0, A_0, \widehat{R}_1, \widehat{S}_1, A_1, \ldots, \widehat{S}_H )$$
但推演深度 $H$ 不是越大越好。
| 推演深度 | 收益 | 代价 |
|---|---|---|
| 较短 | 模型误差较少 | 能利用的未来信息有限 |
| 较长 | 可以比较更长行动后果 | 误差累积,可能进入模型不熟悉区域 |
一种常见思路是:
- 使用较短模型 rollout;
- 在末端接上价值函数;
- 对模型不确定区域降低信任;
- 定期用真实交互校正模型。
公式上仍然是:
$$\widehat{G}{t:t+H} = \sum{k=0}^{H-1} \gamma^k\widehat{R}{t+k+1} + \gamma^H V(\widehat{S}{t+H})$$
但工程关键变成:如何选择 $H$,以及何时相信 $\widehat{S}$。
七、Model Predictive Control:只执行推演出的第一步
一种稳妥方式是滚动规划。
在时刻 $t$,先比较若干候选动作序列:
$$(a_t,a_{t+1},\ldots,a_{t+H-1})$$
选出模型预测回报最高的一条:
$$(a_t*,a_{t+1},\ldots,a_{t+H-1}^)$$
但只在真实环境中执行第一步:
$$A_t=a_t^*$$
获得真实新状态 $S_{t+1}$ 后,再重新规划。
这称为 Model Predictive Control,简称 MPC。
它承认模型会出错,因此不一次性执行整段计划。每走一步,就用现实重新校准起点。
八、MuZero:不必重建世界的每一个细节
传统直觉会认为:环境模型必须预测下一帧画面。
例如,在棋盘或视频游戏中:
$$\widehat{o}{t+1} \approx o{t+1}$$
但对决策而言,精确还原每一个像素未必必要。
MuZero 学习一个适合规划的潜在状态。其核心可以抽象为三个组件:
1. 表示函数
$$s^0 = h_\phi(o_1,\ldots,o_t)$$
它把历史观测压缩为潜在状态 $s^0$。
2. 动态函数
$$(r^{k}, s^{k}) = g_{\phi}(s^{k-1}, a^{k})$$
它在潜在空间中预测执行动作后的奖励与新潜在状态。
3. 预测函数
$$(p^{k}, v^{k}) = f_{\phi}(s^{k})$$
它从潜在状态预测策略分布 $p^k$ 和价值 $v^k$。
其中:
| 符号 | 含义 |
|---|---|
| $o_t$ | 真实观测 |
| $s^k$ | 用于规划的潜在状态 |
| $r^k$ | 模型预测奖励 |
| $p^k$ | 候选动作的策略先验 |
| $v^k$ | 潜在状态价值 |
MuZero 的重要思想是:
模型不一定要完整重建世界,只要保留对决策有用的结构。
这把“学习世界”重新定义为“学习一个足够支持规划的世界表示”。
九、World Model:在潜在空间中想象未来
现实观测可能非常高维,例如图像:
$$o_t\in\mathbb{R}^{H\times W\times C}$$
直接预测未来像素成本高,也容易把计算浪费在与决策无关的细节上。
World Model 常把观测压缩到潜在变量:
$$z_t = e_\phi(o_t)$$
再学习潜在动态:
$$\hat z_{t+1}\sim p_\phi(z_{t+1}|z_t,a_t)$$
以及奖励预测:
$$\hat r_{t+1}=g_\phi(z_t,a_t)$$
策略可以在潜在空间中训练或规划:
$$a_t \sim \pi_\theta(\cdot\mid z_t)$$
潜在表示的好处是压缩:
- 不必保留每个像素;
- 可以在较小空间内推演;
- 可以聚焦于控制相关因素。
但潜在空间也可能丢失关键细节。模型认为“不重要”的信息,可能恰好决定安全边界。
十、搜索、模型与策略如何结合
模型式方法不是要求系统在“策略”和“模型”之间二选一。
现代系统常常把它们组合起来:
| 组件 | 作用 |
|---|---|
| 模型 | 预测候选行动可能带来的后果 |
| 价值函数 | 在有限深度推演末端估计更远未来 |
| 策略网络 | 提供更值得搜索的候选动作 |
| 搜索 | 在决策时临时比较不同未来 |
| 真实交互 | 校正模型、价值和策略 |
以树搜索为例,策略网络可以告诉搜索器哪些动作更值得优先展开,价值网络可以评估叶子节点,模型则负责向前推演状态。
于是行动不再只由一个网络瞬间决定,而是由“已学知识 + 当前搜索”共同决定。
十一、模型式方法的适用范围与边界
Model-Based 方法尤其有吸引力的场景包括:
- 真实交互成本高;
- 环境具有可学习结构;
- 决策前允许一定计算时间;
- 需要在行动前比较多个未来;
- 安全性要求促使系统减少现实试错。
它也并不适合所有问题。
1. 世界可能过于复杂
如果环境变化极快、观测不完整或隐藏因素很多,模型可能难以获得足够准确的预测。
2. 规划有计算成本
Model-Free 策略通常可以一次前向传播直接行动。模型式方法在决策时可能需要大量 rollout 或搜索。
3. 模型误差会被规划主动利用
策略并不会平均地访问所有模型区域。它会寻找预测回报最高的位置,而这些位置恰恰可能是模型最不可靠的边缘区域。
4. 表示学习决定模型看见什么
潜在世界模型只保留被训练目标认为重要的信息。如果目标设计不完整,关键变量可能被压缩掉。
因此,学习世界不等于拥有世界。
十二、边界:模型是另一种估计器,不是上帝视角
Model-Based RL 很容易诱发一种过度乐观的想象:既然智能体能预测未来,它是不是终于摆脱了盲目试错?
并没有。
它只是把一部分试错移动到了模型内部。
原本的问题是:
$$\mathrm{怎样从有限真实经验中学好策略?}$$
加入模型后,问题变成:
$$\mathrm{怎样从有限真实经验中学好模型,并防止策略利用模型误差?}$$
矛盾没有消失,而是转移到了世界表示、预测误差和规划深度上。
回归全景图(Callback)
把 Model-Based RL 放回六个坐标轴:
| 维度 | Model-Based RL 的回答 | 它没有消除的矛盾 |
|---|---|---|
| 目标 | 在真实或模拟未来中寻找更高长期回报 | 模型中的高回报未必在现实中成立 |
| 时间 | 用 rollout、搜索与末端价值连接当前行动和未来后果 | 推演越长,模型误差越可能累积 |
| 更新 | 用真实经验和模拟经验共同更新模型、价值或策略 | 多个学习模块的误差会互相影响 |
| 估计 | 显式学习转移、奖励或潜在动态模型 | 模型只是近似,规划会主动放大模型漏洞 |
| 数据 | 将有限真实经验扩展为大量模拟经验 | 模拟数据便宜,但不一定可信 |
| 探索 | 可优先探索模型不确定或潜在收益高的区域 | 不确定性估计错误时,探索也会被带偏 |
再看三条反馈循环:
| 反馈循环 | Model-Based RL 中的具体形式 |
|---|---|
| 外部交互循环 | 策略在真实环境中行动,真实转移校正模型与策略 |
| 时间回报循环 | 模型 rollout、搜索和末端价值共同把未来压回当前决策 |
| 自我更新循环 | 模型生成模拟数据,模拟数据改变策略,策略又决定接下来采集哪些真实数据 |
模型式方法带来一种更高层的能力:智能体不仅从经验中学,还在内部重组经验,构造尚未真实发生的未来。
但这种能力始终受一个边界约束:
想象必须定期回到现实接受检验。
本章小结
Model-Free 与 Model-Based 不是高低之分,而是两种不同的代价结构。
Model-Free 方法把复杂性集中在策略或价值函数中,行动快,但更依赖真实交互。
Model-Based 方法学习环境动态,在内部进行 rollout 或搜索,提高样本效率,却引入模型偏差和规划成本。
Dyna 让真实经验与模拟经验协作;MPC 每走一步就回到现实重新规划;MuZero 说明模型未必需要重建所有细节;World Model 则把想象搬到潜在空间。
至此,我们已经从六个根本问题出发,重新组装了四类算法路线。
下一部分将进入一个看似全新的场景:大模型后训练。我们会看到,语言模型、奖励模型、PPO、DPO 和 GRPO 背后仍然是熟悉的六个问题,只是状态、动作、奖励和反馈的形式发生了变化。
第八部分:当强化学习进入大模型
第 20 章 当语言模型成为策略
大语言模型看起来与机器人、棋类程序或游戏智能体差别很大。
机器人移动关节,游戏智能体点击按钮,语言模型却是在生成文字。它没有明显的物理环境,也没有一眼可见的奖励。
但如果把生成过程放慢来看,熟悉的强化学习结构会重新出现。
给定一段上下文,语言模型选择下一个 Token;新 Token 被追加到上下文中,模型再选择下一个 Token;直到生成终止符或达到长度上限。
这就是一条序列决策轨迹。
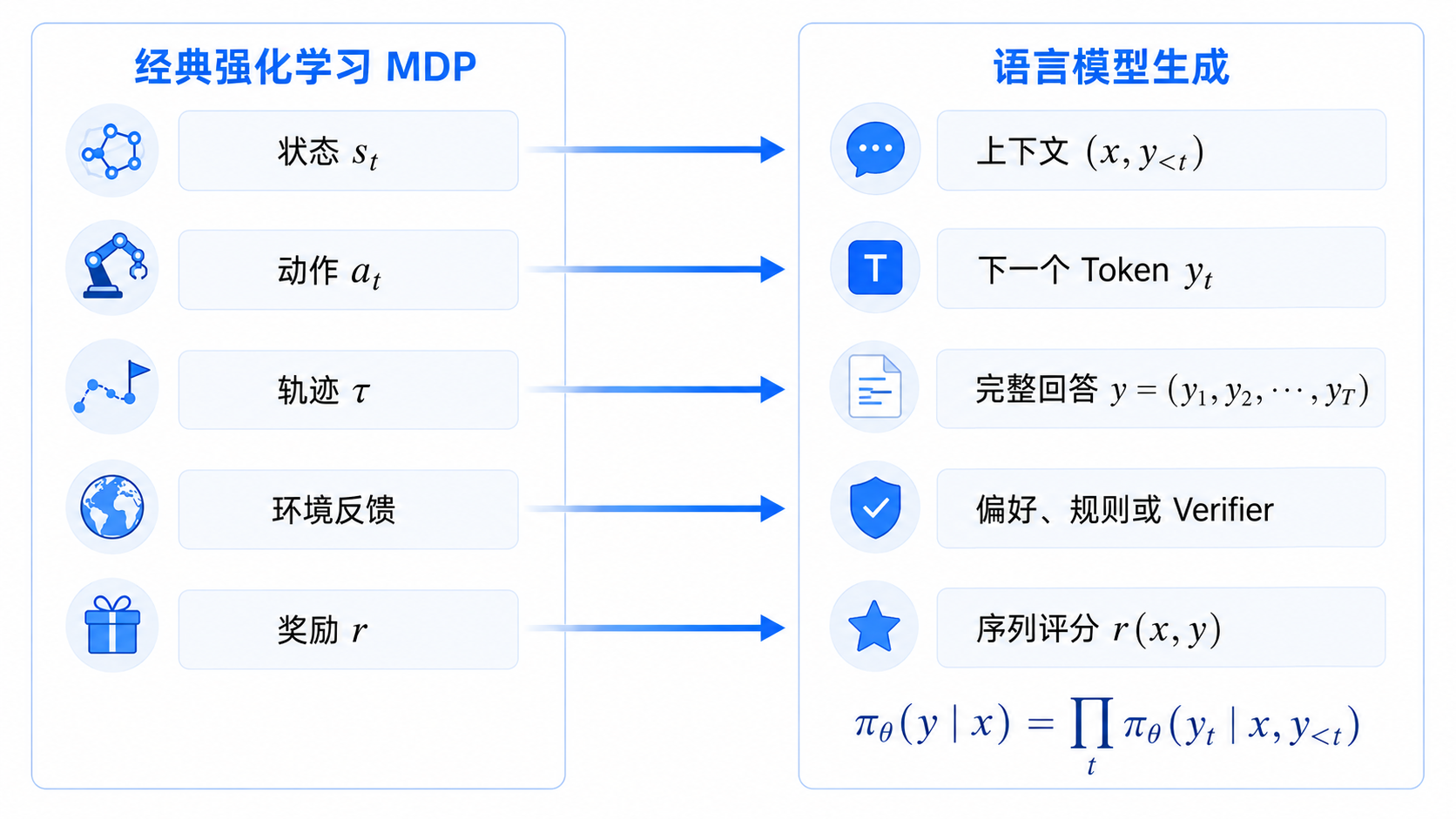
图 20-1:从 MDP 到语言模型
一、Token 作为动作
设用户提示为:
$$x$$
模型已经生成前缀:
$$y_{<t} = (y_1,y_2,\ldots,y_{t-1})$$
在第 $t$ 步,语言模型输出下一个 Token 的概率分布:
$$\pi_\theta ( y_t \mid x,y_{<t} )$$
其中:
| 符号 | 含义 |
|---|---|
| $x$ | 用户提示、系统指令或其他输入上下文 |
| $y_{<t}$ | 第 $t$ 步之前已经生成的 Token 前缀 |
| $y_t$ | 当前准备生成的下一个 Token |
| $\pi_\theta$ | 参数为 $\theta$ 的语言模型策略 |
经典 RL 中,策略写成:
$$\pi_\theta(a_t\mid s_t)$$
语言模型中,对应关系是:
$$a_t \longleftrightarrow y_t$$
也就是:
每生成一个 Token,语言模型就执行了一次动作。
二、上下文作为状态
经典 MDP 中,状态 $s_t$ 应该包含做出当前决策所需的信息。
语言模型在第 $t$ 步看到的是:
$$s_t = (x,y_{<t})$$
每生成一个 Token,状态就会更新:
$$s_{t+1} = (x,y_{<t},y_t)$$
这个转移几乎是确定性的:把刚刚选择的 Token 追加到序列尾部。
因此可以写成:
$$s_{t+1} = f(s_t,y_t)$$
其中 $f$ 表示“把新 Token 接到上下文后面”。
语言模型的环境看似简单,因为状态转移规则只是字符串追加。但真正的复杂性藏在后续评价中:
- 哪种回答更有帮助?
- 哪种回答更准确?
- 哪种回答更安全?
- 哪种回答风格更符合用户需求?
这些问题并不由字符串追加规则自动回答。
三、序列生成作为轨迹
一条完整回答记为:
$$y = (y_1,y_2,\ldots,y_T)$$
对应轨迹:
$$\tau = (s_1,y_1,s_2,y_2,\ldots,s_T,y_T)$$
给定提示 $x$,回答 $y$ 的生成概率为:
$$\pi_\theta(y\mid x)= \prod_{t=1}^{T} \pi_\theta ( y_t \mid x,y_{<t} )$$
这就是自回归分解。
取对数后:
$$\log \pi_\theta(y\mid x)= \sum_{t=1}^{T} \log \pi_\theta ( y_t \mid x,y_{<t} )$$
乘积变成求和非常重要。它让一个完整回答的概率,可以被拆回每个 Token 的对数概率之和。
后面的 DPO 目标正会使用这个结构。
四、终止符 [EOS]:模型何时停止行动
语言模型不仅要决定说什么,还要决定什么时候停止。
终止符 [EOS] 可以看成一个特殊动作:
$$y_t=[\mathrm{EOS}]$$
一旦模型选择它,轨迹结束。
此外,系统通常还会设定最大生成长度:
$$T\leq T_{\max}$$
这意味着语言模型任务存在两种结束方式:
- 模型主动生成
[EOS]; - 达到长度上限后被外部截断。
这个细节会影响奖励与训练。
如果奖励模型偏爱更长、更详细的回答,策略可能推迟 [EOS];如果长度惩罚过强,模型又可能过早停止。
停止动作不是排版细节,而是策略的一部分。
五、序列级奖励:完整回答最后才被评价
很多语言任务没有天然的逐 Token 奖励。
评价者往往在回答生成完成后,才给出一个整体分数:
$$r(x,y)$$
其中:
| 符号 | 含义 |
|---|---|
| $x$ | 提示 |
| $y$ | 完整回答 |
| $r(x,y)$ | 对完整回答的序列级评分 |
经典 RL 的长期目标可以写成:
$$J(\theta)= \mathbf{E}{x \sim \mathcal{D},\ y \sim \pi\theta(\cdot\mid x)} [ r(x,y) ]$$
其中 $\mathcal{D}$ 表示提示分布。
它表达:
对真实提示进行采样,让策略生成回答,并提高这些回答的期望评分。
表面上,语言模型的环境没有复杂物理反馈。但奖励延迟问题反而非常突出:
$$y_1,y_2,\ldots,y_T \longrightarrow r(x,y)$$
一个整体评分需要反过来影响数十、数百甚至更多 Token。
六、Token 级信用分配
假设一个回答最终得到高分。哪些 Token 应该被鼓励?
- 开头是否准确理解了问题?
- 中间推理是否清楚?
- 某个关键事实是否正确?
- 结尾是否简洁?
- 是否只是篇幅较长,因此更容易被评价器偏爱?
如果只有序列级奖励:
$$r(x,y)$$
最粗略的做法是把同一个结果信号作用到整条轨迹。
策略梯度可以写成:
$$\nabla_\theta J(\theta)\approx \mathbf{E} [ r(x,y)\sum_{t=1}^{T} \nabla_\theta \log \pi_\theta ( y_t\mid x,y_{<t} ) ]$$
这意味着:回答分数较高时,提高整条回答中已生成 Token 的概率;回答分数较低时,降低这些 Token 的概率。
但这是一种粗粒度归因。
假设一个回答前 95% 都正确,只在最后给出错误结论。序列级低分可能会压低整条轨迹的概率,而不仅是错误位置附近的 Token。
语言模型后训练仍然面对经典信用分配问题,只是动作数量更多、动作空间更大、奖励常常更稀疏。
七、自回归模型就是策略网络
预训练语言模型通常通过下一个 Token 预测学习:
$$L_{NTP}(\theta)=-\sum_{t=1}^T\log\pi_\theta(y_t|x,y_{<t})$$
其中 NTP 表示 Next-Token Prediction。
这个损失鼓励模型提高训练语料中真实 Token 的概率。
进入后训练后,同一个模型可以被看作策略:
$$\pi_\theta(y_t\mid x,y_{<t})$$
变化不在网络结构,而在训练信号。
| 阶段 | 模型在学习什么 | 数据来自哪里 |
|---|---|---|
| 预训练 | 预测语料中下一个 Token | 大规模文本 |
| SFT | 模仿高质量示范回答 | 人工或筛选后的指令回答 |
| 偏好优化或 RLHF | 提高更受偏好的回答概率 | 偏好数据、奖励模型或可验证反馈 |
同一个自回归模型,在不同训练阶段扮演不同角色。
八、语言空间为何比传统动作空间更复杂
传统控制任务的动作可能只有几个:
$$\mathcal{A} = { \mathrm{左}, \mathrm{右}, \mathrm{跳跃} }$$
语言模型每一步的动作空间则是词表:
$$\mathcal{A} = \mathcal{V}$$
其中 $\mathcal{V}$ 可能包含数万甚至更多 Token。
更重要的是,完整回答空间随长度指数增长。长度为 $T$ 的序列数量近似为:
$$|\mathcal{V}|^T$$
即使:
$$|\mathcal{V}|=50{,}000, \qquad T=100$$
候选序列数量也极其巨大。
这让“探索”获得新的形式:
- 调整采样温度;
- 使用 top-$k$ 或 top-$p$ 采样;
- 对同一提示生成多个候选回答;
- 使用搜索、验证器或重排序器筛选;
- 通过参考模型约束避免进入语言分布的陌生区域。
语言模型不会穷举全部回答。它只能在极大的组合空间中,保留有限的生成多样性。
九、采样温度:控制生成分布的平滑程度
设模型对 Token 的 logit 为:
$$z_i$$
使用温度 $\tau>0$ 后,采样概率为:
$$\pi_\tau(y_t=i\mid s_t)= \frac{ \exp(z_i/\tau)}{ \sum_j \exp(z_j/\tau)}$$
其中:
| 情况 | 效果 |
|---|---|
| $\tau<1$ | 分布更尖锐,更倾向高概率 Token |
| $\tau=1$ | 使用原始 Softmax 分布 |
| $\tau>1$ | 分布更平坦,增加低概率 Token 被采样的机会 |
温度不是奖励函数,也不是策略训练目标。它是在生成阶段调节探索程度的工程旋钮。
这一区分很重要:
改变训练目标、改变策略参数和改变采样方式,是三件不同的事。
十、语言模型中的“环境”去了哪里
在游戏中,智能体执行动作后,环境会返回新的画面和奖励。
在文本生成中,下一状态主要由前缀追加决定:
$$s_{t+1} = (s_t,y_t)$$
环境似乎退到了幕后。
但只要模型与外部世界互动,环境就会重新出现:
- 用户会继续追问;
- 工具调用会返回结果;
- 搜索系统会提供新信息;
- 代码执行器会报告成功或失败;
- 数学验证器会判断答案是否正确;
- 多轮对话会改变后续上下文。
因此,语言模型可以处于两种不同设置中:
| 设置 | 主要特征 |
|---|---|
| 单轮离线回答 | 状态转移多为 Token 追加,奖励通常在回答结束后给出 |
| Agent 式交互 | 模型动作会改变外部环境,环境反馈又进入下一轮上下文 |
不要把两者混为一谈。单轮偏好优化已经可以用 RL 视角理解,但带工具和多轮任务会更接近经典序列决策环境。
十一、从 MDP 到语言模型:逐项映射
| 经典强化学习概念 | 语言模型中的对应物 |
|---|---|
| 状态 $S_t$ | 提示与已生成 Token 构成的上下文 $(x,y_{<t})$ |
| 动作 $A_t$ | 下一个 Token $y_t$ |
| 策略 $\pi_\theta(a\mid s)$ | 自回归语言模型 $\pi_\theta(y_t\mid x,y_{<t})$ |
| 轨迹 $\tau$ | 完整回答或多轮交互过程 |
| 终止动作 | [EOS] 或外部长度截断 |
| 奖励 | 偏好评分、奖励模型分数、规则验证结果或外部任务反馈 |
| 探索 | 采样温度、多候选生成、搜索与重排序 |
| 数据分布 | 提示分布与策略生成回答的分布 |
这张表不是为了把所有语言模型训练都强行叫作强化学习。
它的作用是说明:
一旦训练信号开始评价模型生成的序列,并据此改变生成策略,经典 RL 的六个问题就会重新出现。
十二、边界:不是所有语言模型训练都是 RL
预训练通常最小化下一个 Token 的交叉熵:
$$L_{NTP}(\theta)=-E_{y\sim D}\big[\sum_t \log\pi_\theta(y_t|y_{<t})\big]$$
监督微调通常模仿示范回答:
$$L_{SFT}(\theta)=-E_{(x,y)\sim D_{SFT}}[\sum_t\log\pi_\theta(y_t|x,y_{<t})]$$
它们都使用语言模型概率,但数据中的目标 Token 已经给定。
强化学习或偏好优化关心的则是:
$$\mathrm{模型产生什么回答} \longrightarrow \mathrm{回答被怎样评价} \longrightarrow \mathrm{策略怎样改变}$$
区别不只在公式形式,更在反馈循环是否进入训练。
回归全景图(Callback)
当动作变成 Token,六个问题并没有消失:
| 维度 | 语言模型中的新形式 | 仍需追问的问题 |
|---|---|---|
| 目标 | 提高回答质量、偏好分数或任务成功率 | 评分是否真正代表人的意图? |
| 时间 | 完整回答由许多 Token 构成,评价常在结尾出现 | 最终评分应该怎样分配给不同 Token? |
| 更新 | 使用 SFT、策略梯度或偏好损失改变 Token 概率 | 代理损失怎样连接到真实回答质量? |
| 估计 | 可能使用奖励模型、Critic、验证器或隐式偏好模型 | 哪个评价器可信,在哪些分布上可信? |
| 数据 | 模型生成的回答成为新的训练候选 | 策略变化会怎样改变回答分布? |
| 探索 | 通过采样、多候选生成和搜索产生不同回答 | 多样性、成本与安全如何权衡? |
再看三条反馈循环:
| 反馈循环 | 语言模型中的对应形式 |
|---|---|
| 外部交互循环 | 提示进入模型,模型生成回答,用户、奖励模型或验证器返回反馈 |
| 时间回报循环 | 完整回答的结果回流到此前生成的 Token |
| 自我更新循环 | 生成回答被评价,评价信号更新模型,新模型又生成新的回答分布 |
语言模型不是强化学习的例外。它只是把动作从“推动世界”换成了“延续序列”,把环境反馈从即时物理变化换成了更复杂的人类评价与任务结果。
本章小结
语言模型可以自然地被看作自回归策略:
$$\pi_\theta(y_t\mid x,y_{<t})$$
上下文是状态,Token 是动作,完整回答是轨迹,[EOS] 是终止动作,回答评分是序列级奖励。
这种映射让大模型后训练回到了熟悉的问题:
- 奖励从哪里来?
- 延迟评价如何分配给不同 Token?
- 怎样稳定地更新策略?
- 如何避免评价器漏洞?
- 新模型生成的新分布会不会离开评价器熟悉的区域?
- 采样多样性应该保留到什么程度?
下一章,RLHF 会给出一种经典回答:用人类偏好训练奖励模型,再用 PPO 在参考模型附近谨慎地优化策略。
第 21 章 RLHF:把偏好变成优化信号
经典强化学习常常假设奖励来自环境。
游戏得分、机器人是否到达目标、控制系统消耗多少能源,都可以转成数字。
但语言模型面对的问题更模糊:
- 哪个回答更有帮助?
- 哪个回答更符合事实?
- 哪个回答更安全?
- 哪种表达方式更符合人的真实需求?
这些标准很难被一条简单规则完整表达。
RLHF,也就是 Reinforcement Learning from Human Feedback,尝试把人的偏好转化为可优化信号。
它的经典流程可以概括为:
$$\mathrm{示范数据} \longrightarrow \mathrm{SFT} \longrightarrow \mathrm{偏好比较} \longrightarrow \mathrm{Reward Model} \longrightarrow \mathrm{PPO 更新}$$
但不要被这条流水线迷惑。每一个箭头都包含新的估计与新的假设。
图 21-1:RLHF 全链路
一、第一步:Supervised Fine-Tuning
预训练模型擅长续写文本,却不一定擅长按照指令回答问题。
Supervised Fine-Tuning,简称 SFT,使用高质量示范数据:
$$\mathcal{D}{\mathrm{SFT}} = { (x_i,y_i) }{i=1}^{N}$$
其中:
| 符号 | 含义 |
|---|---|
| $x_i$ | 第 $i$ 个提示 |
| $y_i$ | 对应的高质量示范回答 |
| $N$ | 示范样本数量 |
训练目标为:
$$L_{SFT}(\theta)=-E_{(x,y)\sim D_{SFT}}[\sum_{t=1}^T \log\pi_\theta(y_t|x,y_{<t})]$$
直观地说:
对给定提示,提高示范回答中每个 Token 的概率。
SFT 是模仿学习。它让模型学会回答的基本形式,但仍然受示范数据限制。
如果一个问题有多个合理回答,SFT 通常只展示其中少数几种。它告诉模型“可以怎样做”,却没有充分表达“多个可行答案中,人更喜欢哪个”。
二、第二步:收集偏好数据
给定同一个提示 $x$,让模型生成两个或多个候选回答:
$$y_1,\ y_2,\ldots,y_K \sim \pi(\cdot\mid x)$$
由标注者比较质量。
最简单的偏好对写成:
$$(x,y_w,y_l)$$
其中:
| 符号 | 含义 |
|---|---|
| $x$ | 提示 |
| $y_w$ | preferred response,标注者更偏好的回答 |
| $y_l$ | rejected response,标注者相对不偏好的回答 |
这里的 $w$ 表示 winner,$l$ 表示 loser。
偏好数据通常不是绝对评分,而是相对比较:
$$y_w \succ y_l$$
为什么比较常常比绝对打分容易?
因为人不一定能稳定回答“这段回复是 7.3 分还是 7.8 分”,但往往更容易判断“两个回答中哪个更好”。
相对比较降低了标注难度,却也带来局限:
- 标注标准可能不一致;
- 不同人对“更好”的理解不同;
- 两个候选都很差时,偏好仍然只是相对结果;
- 偏好数据覆盖不到的回答,系统仍然缺少可靠评价。
三、第三步:训练 Reward Model
Reward Model,简称 RM,接收提示与完整回答,并输出一个标量分数:
$$r_\phi(x,y) \in \mathbb{R}$$
其中 $\phi$ 是 Reward Model 的参数。
分数越高,模型越认为人类偏好这个回答。
对偏好对 $(x,y_w,y_l)$,可以使用 Bradley-Terry 形式:
$$\Pr ( y_w \succ y_l \mid x )= \sigma ( r_\phi(x,y_w)- r_\phi(x,y_l))$$
其中:
$$\sigma(z) = \frac{1}{1+e^{-z}}$$
是 Sigmoid 函数。
| 项 | 含义 |
|---|---|
| $r_\phi(x,y_w)$ | Reward Model 对偏好回答的评分 |
| $r_\phi(x,y_l)$ | Reward Model 对较差回答的评分 |
| $r_\phi(x,y_w)-r_\phi(x,y_l)$ | 两个回答之间的分数差 |
| $\sigma(\cdot)$ | 把分数差压缩到 $0$ 与 $1$ 之间 |
如果:
$$r_\phi(x,y_w)- r_\phi(x,y_l) = 2$$
则:
$$\sigma(2) \approx 0.881$$
Reward Model 认为 $y_w$ 优于 $y_l$ 的概率约为 $88.1%$。
训练损失为:
$$\mathcal{L}{\mathrm{RM}}(\phi)= - \mathbf{E}{(x,y_w,y_l)\sim \mathcal{D}{\mathrm{pref}}} [ \log \sigma ( r\phi(x,y_w)- r_\phi(x,y_l)) ]$$
这个损失鼓励 Reward Model 给偏好回答更高分。
四、Reward Model 不是人的价值观
训练完成后,Reward Model 可以快速为大量回答打分。
这很有用,因为真人不可能在每次策略更新时都实时评价数百万条生成结果。
但必须明确:
$$r_\phi(x,y) \neq \mathrm{人的真实意图}$$
Reward Model 只是从有限偏好样本中训练出的代理。
它可能学到:
- 较长回答通常得分更高;
- 使用某种固定结构更像“高质量回答”;
- 某些语气容易得到标注者青睐;
- 在训练分布内有效的模式,在分布外并不可靠。
这与前文的奖励塑形问题完全一致:
一旦代理指标可以被优化,策略就会寻找代理指标中的捷径。
五、第四步:用 PPO 优化语言模型策略
Reward Model 给出回答分数后,可以让语言模型生成回答,并提高高分回答的概率。
简化目标为:
$$max_\theta E_{x\sim D,y\sim\pi_\theta(\cdot|x)}[r_\phi(x,y)]$$
但如果只追求 Reward Model 分数,策略可能快速偏离原有语言分布,产生 Reward Model 没见过的奇怪文本。
因此,通常加入与参考模型之间的 KL 约束:
$$max_\theta E_{x,y\sim\pi_\theta}\big[r_\phi(x,y)-\beta\log\frac{\pi_\theta(y|x)}{\pi_{ref}(y|x)}\big]$$
更一般地,也可以写成:
$$max_\theta E_{x\sim D}\big[E_{y\sim\pi_\theta(\cdot|x)}[r_\phi(x,y)]-\beta D_{KL}(\pi_\theta(\cdot|x)||\pi_{ref}(\cdot|x))\big]$$
其中:
| 符号 | 含义 |
|---|---|
| $\pi_\theta$ | 正在更新的语言模型策略 |
| $\pi_{\mathrm{ref}}$ | 冻结的参考模型,通常来自 SFT 模型 |
| $r_\phi(x,y)$ | Reward Model 给完整回答的评分 |
| $D_{\mathrm{KL}}$ | 新策略与参考策略之间的 KL 散度 |
| $\beta$ | 偏好奖励与策略偏离惩罚之间的权衡系数 |
这个目标表达:
提高偏好奖励,但不要离原来可靠的语言分布太远。
六、为什么 Reference Model 像一只锚
KL 散度定义为:
$$D_{KL}(\pi_\theta||\pi_{ref})=E_{y\sim\pi_\theta}\big[\log\frac{\pi_\theta(y|x)}{\pi_{ref}(y|x)}\big]$$
如果新策略和参考模型接近,KL 较小。
如果新策略大幅提高了某些参考模型认为极不常见的回答概率,KL 会变大。
假设某个回答:
$$\pi_\theta(y\mid x)=0.2$$
$$\pi_{\mathrm{ref}}(y\mid x)=0.02$$
则对数概率比为:
$$\log \frac{0.2}{0.02} = \log 10 \approx 2.303$$
如果:
$$\beta=0.1$$
对应惩罚约为:
$$0.1\times 2.303 = 0.2303$$
Reference Model 并不告诉策略什么是绝对正确。它提供的是一个保守基线:
可以改进,但不要在一次优化中离开已知分布太远。
它与 DQN 的 Target Network 不完全相同,但有相似的稳定化气质:冻结一个参照物,限制另一个快速变化的系统。
七、PPO 如何限制策略突变
语言模型 RLHF 中,PPO 仍然使用新旧策略概率比:
$$\rho_t(\theta)= \frac{ \pi_\theta(y_t\mid x,y_{<t})}{ \pi_{\theta_{\mathrm{old}}}(y_t\mid x,y_{<t})}$$
PPO 裁剪目标为:
$$\mathcal{L}^{\mathrm{CLIP}}(\theta)= \mathbf{E}_t [ \min ( \rho_t(\theta)\widehat{A}_t, \operatorname{clip} ( \rho_t(\theta), 1-\epsilon, 1+\epsilon )\widehat{A}_t ) ]$$
其中:
| 符号 | 含义 |
|---|---|
| $\rho_t(\theta)$ | 新旧策略对当前 Token 概率的比值 |
| $\widehat{A}_t$ | Token 级优势估计 |
| $\epsilon$ | PPO 允许的局部更新区间 |
| $\operatorname{clip}$ | 把概率比裁剪在有限区间 |
RLHF 中常同时使用两种限制:
| 机制 | 参照对象 | 作用 |
|---|---|---|
| PPO Clip | 上一轮策略 $\pi_{\theta_{\mathrm{old}}}$ | 限制单轮更新幅度 |
| KL Penalty | 冻结参考模型 $\pi_{\mathrm{ref}}$ | 限制长期偏离程度 |
这两个约束不要混为一谈。
一个管理局部步长,一个管理整体漂移。
八、Critic 与 Token 级优势
Reward Model 常在回答结束时给出序列分数:
$$r_\phi(x,y)$$
但 PPO 需要估计每个 Token 动作的优势:
$$\widehat{A}_t$$
因此系统通常还会训练一个 Value Model 或 Critic:
$$V_w(x,y_{<t})$$
它估计在当前前缀下继续生成,预期能获得多少未来回报。
TD 误差形式仍然熟悉:
$$\delta_t = r_t + \gamma V_w(x,y_{\leq t})- V_w(x,y_{<t})$$
如果中间 Token 没有外部奖励,则常见情况为:
$$r_t=0$$
序列末端再加入 Reward Model 分数和其他惩罚。
优势可以使用 GAE:
$$\hat{A}t^{GAE} = \sum{l=0}^{T-t-1} (\gamma \lambda)^l \delta_{t+l}$$
这说明 RLHF 并没有让经典估计问题变少。
相反,它至少引入了两个估计器:
- Reward Model 估计人的偏好;
- Critic 估计不同 Token 前缀的未来价值。
九、Token Mask:只更新真正属于回答的部分
训练批次通常包含:
- 系统提示;
- 用户提示;
- 模型回答;
- padding Token。
并不是所有位置都应进入策略损失。
设掩码为:
$$m_t \in {0,1}$$
策略损失可以写成:
$$\mathcal{L}_{\mathrm{policy}} = - \frac{ \sum_t m_t \ell_t}{ \sum_t m_t}$$
其中:
| 符号 | 含义 |
|---|---|
| $m_t=1$ | 当前 Token 属于需要优化的模型回答 |
| $m_t=0$ | 当前 Token 是提示、padding 或其他不应更新的位置 |
| $\ell_t$ | 当前 Token 的策略代理目标项 |
Token Mask 是工程细节,却直接影响训练语义。
如果掩码错误,模型可能在不该优化的位置计算梯度,甚至把 padding 或用户输入混进策略更新。
十、Length Bias:为什么更长回答可能占便宜
奖励模型可能偏向更长回答。
原因并不神秘:
- 更长回答更容易包含看似完整的解释;
- 训练数据中,详细回答可能更常被标注者偏好;
- 某些任务中,重复或冗余内容未被充分惩罚。
假设 Reward Model 输出:
$$r_\phi(x,y)= q(x,y) + c\cdot \lvert y \rvert$$
其中:
| 项 | 含义 |
|---|---|
| $q(x,y)$ | 真正与回答质量有关的部分 |
| $\lvert y \rvert$ | 回答长度 |
| $c$ | Reward Model 无意中学到的长度偏好 |
只要:
$$c>0$$
策略就可能通过增加长度提高奖励,即使新增内容没有真正价值。
这就是代理目标漏洞。
解决方式可能包括:
- 改善偏好数据;
- 对长度进行归一化或显式控制;
- 分任务设计评价标准;
- 检查高奖励样本;
- 引入更丰富的评估器;
- 保留人工审查。
没有单一公式能自动修复价值判断。
十一、Reward Hacking:优化器会发现评价器的弱点
如果策略只最大化 Reward Model:
$$\max_\theta \mathbf{E} [ r_\phi(x,y) ]$$
它可能生成 Reward Model 高分但人并不喜欢的回答。
这种现象称为 Reward Hacking。
其结构与前文完全一致:
$$\mathrm{人的真实意图} \longrightarrow \mathrm{有限偏好数据} \longrightarrow \mathrm{Reward Model} \longrightarrow \mathrm{策略优化}$$
每一次压缩都可能损失信息。
策略优化越强,越可能把细小缺口放大。
因此,KL 约束、在线抽查、偏好数据迭代更新和分布外评估都很重要。它们不是装饰,而是为了控制代理目标失灵。
十二、对齐税与能力保持
如果后训练只追求某些偏好指标,模型可能在其他能力上退化。
例如:
- 回答更稳妥,但信息密度下降;
- 风格更规范,但创造性降低;
- 更符合某类标注偏好,却损害其他任务能力;
- 过度拒答,或者过度迎合。
这种代价常被概括为 alignment tax,也就是对齐税。
可以在目标中加入额外约束或辅助训练信号,例如保留一部分预训练目标:
$$\mathcal{L}{\mathrm{total}} = \mathcal{L}{\mathrm{RLHF}} + \eta \mathcal{L}_{\mathrm{pretrain}}$$
其中:
| 符号 | 含义 |
|---|---|
| $\mathcal{L}_{\mathrm{RLHF}}$ | 偏好优化相关损失 |
| $\mathcal{L}_{\mathrm{pretrain}}$ | 语言建模或预训练分布上的辅助损失 |
| $\eta$ | 保持原有能力的权重 |
这不是免费午餐。
$\eta$ 太小,原有能力可能受损;$\eta$ 太大,偏好优化又可能不充分。
十三、RLHF 全链路中的反馈循环
RLHF 不是一次性加工流程。
更真实的结构是:
$$\mathrm{当前策略} \longrightarrow \mathrm{生成候选回答} \longrightarrow \mathrm{收集新偏好} \longrightarrow \mathrm{更新 Reward Model} \longrightarrow \mathrm{更新策略}$$
策略变化后,生成分布也会变化。
Reward Model 起初熟悉的回答分布,未必仍然覆盖新策略产生的文本。
于是再次出现非平稳性:
$$\pi_{\theta_{\mathrm{old}}} \neq \pi_{\theta_{\mathrm{new}}}$$
$$y \sim \pi_{\theta_{\mathrm{new}}} \quad \mathrm{可能离开 Reward Model 熟悉的区域}$$
这正是经典强化学习中的“学习者改变了自己的数据”。
十四、边界:RLHF 不是把人类价值完整写入模型
RLHF 的名字很容易引发过高期待。
它不是把人类价值观完整编码进神经网络,也不是让模型自动理解所有人的真实意图。
它做的是:
- 收集有限示范与偏好;
- 用 Reward Model 近似这些偏好;
- 用受约束的策略优化提高代理奖励;
- 在迭代评估中继续修正数据与模型。
它是一套工程方法,也是一套制度安排。
标注指南、样本覆盖、评价者差异、风险监控和人工回路,都属于系统的一部分。
回归全景图(Callback):PPO-RLHF
| 维度 | PPO-RLHF 的回答 | 它没有消除的矛盾 |
|---|---|---|
| 目标 | 最大化偏好奖励,同时避免策略过度偏离参考模型 | 真实人类意图仍然只能被代理表达 |
| 时间 | 一个回答由许多 Token 构成,奖励常在序列结束后出现 | Token 级信用分配仍然存在 |
| 更新 | 使用 PPO Clip、KL 惩罚、Token Mask 等机制完成局部更新 | 训练链路较复杂,多个超参数共同影响稳定性 |
| 估计 | Reward Model 估计偏好,Critic 估计价值 | 估计器更多,而不是更少;两类误差都会影响策略 |
| 数据 | 策略在线生成新回答,偏好数据和奖励模型再随迭代更新 | 策略变化会改变采样分布,也会改变 Reward Model 面对的输入分布 |
| 探索 | 生成多样性保留有限探索,KL 约束主动压缩探索范围 | 稳定性、可控性与发现更优回答之间仍需权衡 |
再看三条反馈循环:
| 反馈循环 | PPO-RLHF 中的具体形式 |
|---|---|
| 外部交互循环 | 模型生成回答,人类、奖励模型或评估流程给出反馈 |
| 时间回报循环 | 序列末端奖励通过 Critic 与优势估计回到每个 Token |
| 自我更新循环 | Reward Model 分数推动策略更新,新策略产生新回答分布,又要求评价系统继续校正 |
判断:PPO-RLHF 没有消解经典 RL 的矛盾,而是将它们完整迁移到了语言模型场景,并增加了偏好建模误差。
本章小结
RLHF 的关键不是一个单独算法,而是一条完整链路:
- SFT 让模型先学会基本指令跟随;
- 偏好数据表达回答之间的相对质量;
- Reward Model 把有限偏好压缩成可重复调用的评分器;
- PPO 用 Token 级优势更新语言模型;
- Reference Model 和 KL 惩罚限制策略漂移;
- Token Mask、长度控制和能力保持机制管理工程风险。
RLHF 没有让奖励设计问题消失。它把奖励从手写规则变成了学出来的代理模型。
下一章会出现两条更轻或更直接的路线:
- DPO 绕过显式 Reward Model 和 PPO 在线环节;
- GRPO 弱化单独 Critic,使用组内相对比较构造更新信号。
它们究竟删除了矛盾,还是只是重新安排了矛盾的位置?
第 22 章 DPO、GRPO 与新一代后训练方法
RLHF 的经典链路很完整,也很重:
$$\mathrm{偏好数据} \longrightarrow \mathrm{Reward Model} \longrightarrow \mathrm{Critic} \longrightarrow \mathrm{PPO} \longrightarrow \mathrm{新策略}$$
每个组件都有作用,也都会带来训练成本、显存占用和误差来源。
于是,后训练方法开始追问:
- 能否不单独训练 Reward Model?
- 能否不再维护一个与策略模型规模相近的 Critic?
- 能否把人的相对偏好更直接地写进更新目标?
- 对数学、代码等任务,能否使用可验证结果代替模糊评分?
DPO 和 GRPO 给出了不同回答。
它们不是同一种方法,也不应该被粗略归为“更简单的 RLHF”。DPO 主要重构偏好建模与策略更新之间的关系;GRPO 则重构 PPO 中优势估计的方式。
图 22-1:PPO、DPO、GRPO 对照
一、先区分几种容易混淆的训练方式
后训练方法很多。理解它们之前,先把概念边界划清。
| 方法类别 | 数据从哪里来 | 是否在线生成新回答 | 主要更新信号 |
|---|---|---|---|
| SFT | 固定示范数据 | 通常否 | 模仿目标回答 Token |
| Offline Preference Optimization | 固定偏好对 | 训练时通常否 | 偏好回答与非偏好回答的相对关系 |
| PPO-RLHF | 当前策略采样 | 是 | Reward Model 分数、Critic 优势、KL 约束 |
| GRPO 类在线策略优化 | 当前或旧策略对同一提示采样多条回答 | 通常是 | 组内相对奖励、策略比值、KL 约束 |
| Verifier 驱动训练 | 模型生成候选,验证器检查结果 | 常见为在线或迭代式 | 可验证结果、步骤检查或规则反馈 |
不要用“有没有出现强化学习三个字”判断方法本质。
更好的问题是:
- 奖励或偏好从哪里来?
- 数据是固定的,还是由当前策略生成?
- 更新是否依赖策略采样?
- 是否存在参考模型或其他约束?
- 被删除的模块,其工作转移到了哪里?
二、偏好对:DPO 与 RLHF 的共同起点
给定提示 $x$,收集一对回答:
$$(y_w,y_l)$$
其中:
$$y_w \succ y_l$$
表示人或评价系统更偏好 $y_w$。
数据集写成:
$$D_{pref} = { (x_i, y_{w,i}, y_{l,i}) }_{i=1}^{N}$$
经典 RLHF 先用这些偏好对训练 Reward Model:
$$r_\phi(x,y)$$
再用 PPO 优化策略。
DPO 的问题是:
能否直接从偏好对更新策略,不再显式训练一个独立 Reward Model,也不再运行 PPO 在线训练链路?
三、Bradley-Terry:从相对分数解释偏好概率
Bradley-Terry 模型假设,人偏好 $y_w$ 而不是 $y_l$ 的概率由奖励差决定:
$$\Pr ( y_w\succ y_l\mid x )= \sigma ( r(x,y_w)- r(x,y_l))$$
其中:
$$\sigma(z) = \frac{1}{1+e^{-z}}$$
这条公式有两个关键性质。
第一,偏好由奖励差决定,而不是奖励绝对值决定。
如果两个回答的奖励都加上同一个常数:
$$r'(x,y)= r(x,y)+c(x)$$
则:
$$r'(x,y_w)-r'(x,y_l)= r(x,y_w)-r(x,y_l)$$
偏好概率不变。
第二,奖励差越大,偏好概率越接近 $1$。
例如:
$$r(x,y_w)=3, \qquad r(x,y_l)=1$$
则:
$$\Pr(y_w\succ y_l\mid x)= \sigma(2) \approx 0.881$$
四、从 KL 约束 RLHF 目标出发
DPO 并不是凭空提出一个分类损失。它从标准的 KL 约束奖励最大化目标出发:
$$\max_{\pi} E_{x \sim D, y \sim \pi(\cdot | x)} [ r(x,y) ] - \beta E_{x \sim D} [ D_{KL}( \pi(\cdot | x) || \pi_{ref}(\cdot | x) ) ]$$
其中:
| 符号 | 含义 |
|---|---|
| $\pi$ | 希望优化的新策略 |
| $\pi_{\mathrm{ref}}$ | 冻结参考策略 |
| $r(x,y)$ | 回答奖励 |
| $\beta$ | 控制策略偏离参考模型的成本 |
这个目标的最优策略满足:
$$\pi^*(y\mid x)= \frac{ 1}{ Z(x)} \pi_{\mathrm{ref}}(y\mid x)\exp ( \frac{ r(x,y)}{ \beta} )$$
其中:
$$Z(x)= \sum_y \pi_{\mathrm{ref}}(y\mid x)\exp ( \frac{ r(x,y)}{ \beta} )$$
是归一化项,也称配分函数。
直观地说:
在参考模型原有概率的基础上,对高奖励回答进行指数放大。
五、把奖励改写成策略与参考模型的对数概率差
对最优策略公式取对数:
$$\log \pi^*(y\mid x)= \log \pi_{\mathrm{ref}}(y\mid x)+ \frac{ r(x,y)}{ \beta} - \log Z(x)$$
整理得到:
$$r(x,y)= \beta \log \frac{ \pi^*(y\mid x)}{ \pi_{\mathrm{ref}}(y\mid x)} + \beta\log Z(x)$$
这一步非常重要。
它说明奖励可以被写成:
$$\mathrm{新策略相对参考策略的对数概率提升} + \mathrm{只依赖提示的常数}$$
将两个回答相减:
$$r(x,y_w)-r(x,y_l)$$
$$= \beta \log \frac{ \pi^(y_w\mid x)}{ \pi_{\mathrm{ref}}(y_w\mid x)} - \beta \log \frac{ \pi^(y_l\mid x)}{ \pi_{\mathrm{ref}}(y_l\mid x)}$$
$\beta\log Z(x)$ 因为对同一个提示相同,正好抵消。
这就是 DPO 能够绕过显式 Reward Model 的关键。
六、DPO 目标:直接提高偏好回答的相对优势
用参数化策略 $\pi_\theta$ 代替 $\pi^*$,DPO 损失写成:
$$L_{DPO}(\theta) = - E_{(x, y_w, y_l) \sim D_{pref}} [ \log \sigma ( \beta \log \frac{ \pi_\theta(y_w | x) }{ \pi_{ref}(y_w | x) } - \beta \log \frac{ \pi_\theta(y_l | x) }{ \pi_{ref}(y_l | x) } ) ]$$
为了更清楚,可以定义:
$$\Delta_\theta(x,y_w,y_l)= \log \frac{ \pi_\theta(y_w\mid x)}{ \pi_{\mathrm{ref}}(y_w\mid x)} - \log \frac{ \pi_\theta(y_l\mid x)}{ \pi_{\mathrm{ref}}(y_l\mid x)}$$
于是:
$$\mathcal{L}{\mathrm{DPO}}(\theta)= - \mathbf{E} [ \log\sigma ( \beta\Delta\theta ) ]$$
其中:
| 符号 | 含义 |
|---|---|
| $\pi_\theta(y_w\mid x)$ | 当前策略生成偏好回答的概率 |
| $\pi_\theta(y_l\mid x)$ | 当前策略生成非偏好回答的概率 |
| $\pi_{\mathrm{ref}}$ | 冻结参考模型 |
| $\Delta_\theta$ | 相对参考模型,当前策略让偏好回答相对于非偏好回答增加了多少对数概率优势 |
| $\beta$ | 控制偏好强化与参考约束之间的尺度 |
DPO 做的事情可以用一句话概括:
相对于参考模型,提高偏好回答的概率,并降低非偏好回答的概率。
七、最小例子:DPO 在比较什么
假设对同一个提示:
$$\pi_\theta(y_w\mid x)=0.12, \qquad \pi_{\mathrm{ref}}(y_w\mid x)=0.08$$
$$\pi_\theta(y_l\mid x)=0.04, \qquad \pi_{\mathrm{ref}}(y_l\mid x)=0.05$$
则:
$$\log \frac{ \pi_\theta(y_w\mid x)}{ \pi_{\mathrm{ref}}(y_w\mid x)} = \log 1.5 \approx 0.405$$
$$\log \frac{ \pi_\theta(y_l\mid x)}{ \pi_{\mathrm{ref}}(y_l\mid x)} = \log 0.8 \approx -0.223$$
因此:
$$\Delta_\theta = 0.405-(-0.223) = 0.628$$
当前策略相对参考模型,已经更偏向 $y_w$。
如果:
$$\beta=1$$
则偏好概率估计为:
$$\sigma(0.628) \approx 0.652$$
损失会继续推动策略提高这一区分。
八、为什么 DPO 看起来像监督学习
DPO 训练时通常使用固定偏好数据集:
$$(x,y_w,y_l) \sim \mathcal{D}_{\mathrm{pref}}$$
它不要求在每次梯度更新时:
- 从当前策略重新采样;
- 调用显式 Reward Model 打分;
- 训练 Critic;
- 运行 PPO rollout。
因此,工程体验更接近监督学习:读取批次,计算对比损失,反向传播。
但 DPO 不是普通 SFT。
SFT 只提高偏好回答概率:
$$L_{SFT} = - \log \pi_\theta(y_w | x)$$
DPO 还比较:
- 偏好回答与非偏好回答;
- 当前策略与参考模型;
- 两种回答的相对概率提升。
它把 KL 约束 RLHF 目标压缩进一个偏好分类形式。
九、绕过 Reward Model,不等于奖励估计消失
DPO 不再单独训练显式 Reward Model:
$$r_\phi(x,y)$$
但奖励逻辑没有凭空消失。
它被隐式绑定到:
$$\beta \log \frac{ \pi_\theta(y\mid x)}{ \pi_{\mathrm{ref}}(y\mid x)}$$
也就是当前策略相对参考模型的对数概率差。
更准确地说:
DPO 通过重参数化,把“先拟合奖励,再优化策略”改写成“直接用策略表示隐式奖励,并从偏好对更新策略”。
它减少了显式组件,却仍依赖:
- 偏好数据质量;
- Bradley-Terry 等偏好建模假设;
- 参考模型选择;
- $\beta$ 的尺度;
- 数据覆盖范围;
- 训练数据与部署分布之间的一致性。
十、DPO 的边界:固定偏好数据并不覆盖整个语言空间
DPO 常以离线偏好数据训练:
$$\mathcal{D}_{\mathrm{pref}}$$
这提高了稳定性,也限制了探索。
如果数据集中从未出现某类回答,DPO 就缺少直接证据判断它。
假设部署中出现新问题:
$$x_{\mathrm{new}} \not\sim \mathcal{D}_{\mathrm{pref}}$$
或者模型产生新型回答:
$$y_{\mathrm{new}}$$
训练集没有覆盖它们时,偏好泛化仍然依赖模型已有表示与归纳偏置。
因此出现 Online DPO 或迭代式偏好数据更新并不奇怪:
$$\mathrm{当前策略} \longrightarrow \mathrm{生成新回答} \longrightarrow \mathrm{收集新偏好} \longrightarrow \mathrm{更新偏好数据} \longrightarrow \mathrm{再次训练}$$
一旦进入在线循环,数据分布漂移问题也会回来。
十一、GRPO:不用单独 Critic,怎样估计优势
PPO 通常需要 Critic:
$$V_w(x,y_{<t})$$
它用于构造 Token 级优势估计。
但语言模型的 Critic 可能与策略模型规模相近,训练成本不低。并且,奖励常在序列末端给出,要求 Critic 准确估计每个 Token 前缀的价值并不容易。
GRPO,也就是 Group Relative Policy Optimization,采用另一种方式。
对同一个问题 $x$,从旧策略采样一组回答:
$$y_1,y_2,\ldots,y_G \sim \pi_{\theta_{\mathrm{old}}}(\cdot\mid x)$$
再对每个回答评分:
$$r_1,r_2,\ldots,r_G$$
计算组内均值:
$$\mu_r = \frac{1}{G} \sum_{i=1}^{G} r_i$$
以及组内标准差:
$$\sigma_r = \sqrt{ \frac{1}{G} \sum_{i=1}^{G} ( r_i-\mu_r )^2}$$
构造相对优势:
$$\widehat{A}_i = \frac{ r_i-\mu_r}{ \sigma_r+\varepsilon}$$
其中:
| 符号 | 含义 |
|---|---|
| $G$ | 同一提示下采样回答数量 |
| $r_i$ | 第 $i$ 个回答的奖励 |
| $\mu_r$ | 组内平均奖励 |
| $\sigma_r$ | 组内奖励标准差 |
| $\varepsilon$ | 防止分母为零的小常数 |
| $\widehat{A}_i$ | 第 $i$ 个回答相对同组平均水平好多少 |
十二、最小例子:组内比较如何形成优势
对同一个数学问题,采样四个回答,验证器给分:
$$[1,\ 1,\ 0,\ 0]$$
组内均值:
$$\mu_r = \frac{1+1+0+0}{4} = 0.5$$
标准差:
$$\sigma_r = \sqrt{ \frac{ (1-0.5)^2 + (1-0.5)^2 + (0-0.5)^2 + (0-0.5)^2}{4}} = 0.5$$
忽略很小的 $\varepsilon$,相对优势为:
$$[1,\ 1,\ -1,\ -1]$$
正确答案相对组内平均水平更好,概率应该提高;错误答案相对更差,概率应该降低。
GRPO 不需要 Critic 预测每个前缀的长期价值,而是让同一提示下的多个候选回答互相提供参照。
十三、GRPO 的策略目标
对第 $i$ 个回答中的第 $t$ 个 Token,定义策略比值:
$$\rho_{i,t}(\theta)= \frac{ \pi_\theta ( y_{i,t} \mid x,y_{i,<t} )}{ \pi_{\theta_{\mathrm{old}}} ( y_{i,t} \mid x,y_{i,<t} )}$$
一个常见的 GRPO 目标写成:
$$J_{GRPO}(\theta) = E\left[\frac{1}{G}\sum_{i=1}{G}\frac{1}{|y_i|}\sum_{t=1}{|y_i|}\left(\min\left[\rho_{i,t}(\theta)\hat A_i,clip(\rho_{i,t}(\theta),1-\epsilon,1+\epsilon)\hat A_i\right]-\beta D_{KL}\left(\pi_\theta(\cdot|x,y_{i,<t})||\pi_{ref}(\cdot|x,y_{i,<t})\right)\right)\right]$$
其中:
| 符号 | 含义 |
|---|---|
| $\rho_{i,t}(\theta)$ | 新旧策略对当前 Token 概率的比值 |
| $\widehat{A}_i$ | 第 $i$ 个回答的组内相对优势 |
| $\epsilon$ | 裁剪区间宽度 |
| $\beta$ | KL 约束强度 |
| $\pi_{\mathrm{ref}}$ | 冻结参考模型 |
这条公式保留了 PPO 的局部裁剪思想,也保留了参考模型约束。
变化在于:
$$\mathrm{Critic 预测优势} \quad\longrightarrow\quad \mathrm{组内奖励统计量估计优势}$$
十四、弱化 Critic,不等于估计问题消失
GRPO 可以省去单独价值模型,这是明显的工程收益。
但优势仍然需要估计:
$$\widehat{A}_i = \frac{ r_i-\mu_r}{ \sigma_r+\varepsilon}$$
它的可靠性取决于:
- 同一提示采样多少个回答;
- 候选回答是否足够多样;
- 奖励函数或验证器是否可信;
- 组内奖励方差是否足够区分候选;
- 长序列奖励能否合理作用到不同 Token;
- KL 约束是否过强或过弱。
如果一组回答奖励完全相同:
$$r_1=r_2=\cdots=r_G$$
则:
$$\sigma_r=0$$
组内比较无法提供有效方向。
如果组内只有一个回答偶然获得噪声高分,它也可能得到过强鼓励。
显式 Critic 被弱化,估计误差转移到了组内采样和奖励统计。
十五、Outcome Supervision 与 Process Supervision
如果只对最终答案评分,称为 Outcome Supervision。
例如数学答案正确:
$$r(y)=1$$
错误:
$$r(y)=0$$
这种方式简单、可靠,但信用分配较粗。模型可能碰巧得到正确答案,却包含不稳健的推理过程。
如果对中间步骤也评分,称为 Process Supervision。
设推理过程分为 $K$ 步:
$$z_1,z_2,\ldots,z_K$$
每一步有过程奖励:
$$r_1,r_2,\ldots,r_K$$
则某个较早 Token 的优势可以聚合之后步骤奖励。
过程监督提供更细粒度信号,但成本更高:
- 需要步骤级标注或步骤验证器;
- “正确步骤”有时难以严格定义;
- 评价器本身仍可能存在漏洞。
它重新回到了信用分配问题:
只看最终结局,信号太粗;检查每一步,成本又会显著上升。
十六、Verifier:当奖励可以被验证
对开放式对话,很难写出完美奖励。
但一些任务有可验证结果:
- 数学答案是否正确;
- 程序是否通过测试;
- 形式证明是否被检查器接受;
- 工具调用结果是否满足约束;
- 游戏状态是否达到目标。
验证器可以写成:
$$v(x,y) \in {0,1}$$
或更一般地:
$$v(x,y) \in \mathbb{R}$$
如果验证器可靠,奖励比模糊偏好更清楚。
但“可验证”仍不是“全部正确”。
例如,代码通过有限测试不等于没有隐藏错误;数学最终答案正确不等于推理过程可靠;某项指标达标不等于系统整体符合人的意图。
验证器缩小了奖励歧义,却没有把开放世界压缩成一个完美数字。
十七、Reasoning Model 的后训练:探索被组织为候选生成
在推理任务中,模型可以对同一问题采样多个候选:
$$y_1,y_2,\ldots,y_G$$
这些候选既是训练数据,也是有限探索。
采样温度较高时,候选更丰富:
$$\mathrm{更强探索} \longrightarrow \mathrm{更可能发现新推理路径}$$
但错误回答也会增加。
采样温度较低时,候选更集中:
$$\mathrm{更强利用} \longrightarrow \mathrm{更稳定但可能缺少新路径}$$
GRPO、验证器和组内比较把探索重新组织成:
$$\mathrm{同一问题} \longrightarrow \mathrm{生成多个回答} \longrightarrow \mathrm{相对评价} \longrightarrow \mathrm{提高更好回答概率}$$
这仍然是探索与利用,只是探索空间从物理动作变成了语言推理轨迹。
十八、PPO、DPO 与 GRPO:不要用一条轴线简单排序
| 维度 | PPO-RLHF | DPO | GRPO |
|---|---|---|---|
| 常见数据形式 | 在线生成回答 | 离线偏好对 | 同一提示下在线或迭代采样多个回答 |
| 显式 Reward Model | 常见 | 训练链路中可省去 | 依奖励来源而定,可使用 RM、验证器或规则奖励 |
| 单独 Critic | 常见 | 不需要 | 可弱化或省去 |
| 参考模型 | 常见 | 核心组成 | 常见 |
| 更新核心 | PPO 优势与裁剪 | 偏好对比分类损失 | 组内相对优势与裁剪 |
| 主要优势 | 在线策略优化能力强 | 训练链路更简单稳定 | 减少 Critic 成本,适合多候选相对比较 |
| 主要边界 | 链路复杂,估计器多 | 依赖离线偏好数据覆盖与建模假设 | 依赖组内采样质量、奖励可靠性和采样成本 |
这三者不是“旧方法、中间方法、新方法”的单向替代关系。
它们适合的反馈条件、数据条件和计算预算并不相同。
十九、边界:删除模块是一种重构,不是魔法
当一个新方法删除显式 Reward Model 或 Critic 时,第一反应不应是“问题终于被解决了”。
应该继续追问:
- 原模块承担的工作去了哪里?
- 误差被显式暴露,还是被隐藏进新假设?
- 数据覆盖不足时,系统怎样知道自己不知道?
- 在线采样被删除后,探索发生在哪里?
- 参考模型、验证器和组内统计量分别承担了什么责任?
这正是本书希望培养的上帝视角:
不被算法名称吸引,始终追踪目标、估计、数据与反馈循环的去向。
回归全景图(Callback):DPO
| 维度 | DPO 的处理方式 | 消解了什么,转移了什么 |
|---|---|---|
| 目标 | 使用偏好对推动策略更偏向被选择的回答 | 人类意图仍通过有限偏好数据表达,代理目标问题没有消失 |
| 时间 | 通常在完整回答层面比较优劣 | Token 级信用分配被压缩进序列对数概率,细粒度归因仍隐含存在 |
| 更新 | 直接优化偏好分类形式的目标 | 省去 PPO 在线更新链路,但更新逻辑被重构为参考模型相对对数概率的对比 |
| 估计 | 不再单独训练显式 Reward Model | 奖励没有凭空消失,而是依赖建模假设,隐式绑定到策略与参考模型的对数概率差 |
| 数据 | 主要依赖离线偏好对 | 训练更稳定,但能力上限受数据覆盖范围约束,分布外行为仍难以判断 |
| 探索 | 训练阶段通常不主动与环境探索 | 探索被转移到偏好数据的采集、生成和筛选阶段 |
判断:DPO 不是抛弃强化学习内核,而是对“估计与更新”环节做了巧妙重构。它减少了显式组件,却把部分矛盾压缩进数据、参考模型和推导假设中。
回归全景图(Callback):GRPO
| 维度 | GRPO 的处理方式 | 消解了什么,转移了什么 |
|---|---|---|
| 目标 | 根据同一问题下多个回答的相对奖励改进策略 | 从绝对评价转向相对评价,但奖励来源是否可靠仍然关键 |
| 时间 | 序列级或步骤级奖励仍需作用到生成轨迹 | 长序列中的信用分配并未自然消失 |
| 更新 | 使用组内相对优势推动策略更新,并通常配合裁剪和 KL 约束 | 更新结构更轻,但仍需控制策略漂移 |
| 估计 | 可以不依赖单独训练的 Critic,以组内统计量构造相对优势 | 显式价值网络被弱化,估计问题转移为组内采样质量、奖励噪声与方差控制 |
| 数据 | 通常围绕当前或旧策略在线生成多个候选回答 | 在线分布漂移依然存在,采样成本和候选多样性成为新瓶颈 |
| 探索 | 通过同一提示下的多候选生成保留有限探索 | 探索被组织为组内生成,但仍受温度、采样策略和 KL 约束限制 |
判断:GRPO 弱化了显式 Critic,却没有消除估计问题。它把部分价值估计工作转移到了组内比较和采样统计中。
本章小结
DPO 与 GRPO 的共同价值,不是“终于摆脱了强化学习”,而是重新安排系统中最昂贵、最不稳定的部分。
DPO 从 KL 约束 RLHF 目标出发,把奖励重参数化为策略与参考模型的对数概率差,用一个偏好分类损失直接更新策略。
GRPO 从 PPO 出发,对同一提示采样多个回答,用组内相对奖励估计优势,从而弱化对单独 Critic 的依赖。
它们提醒我们:
新方法往往不是删除矛盾,而是转移矛盾;不是不再估计,而是更换估计的位置;不是不再探索,而是改变探索发生的阶段。
下一章,我们暂时放下算法细节,回到更难的问题:当奖励、偏好与验证器都只是人的意图的代理时,对齐究竟是一项优化任务,还是一项更广泛的制度设计任务?
第 23 章 对齐问题的哲学余波
写到这里,我们已经见过许多目标函数:
$$J(\pi) = \mathbf{E}\pi [ \sum_t \gamma^tR{t+1} ]$$
$$\mathcal{L}{\mathrm{DPO}} = - \mathbf{E} [ \log\sigma ( \beta\Delta\theta ) ]$$
$$\widehat{A}_i = \frac{ r_i-\mu_r}{ \sigma_r+\varepsilon}$$
它们越来越精细,也越来越适合工程系统。
但一个根本问题始终没有被公式自动回答:
我们希望智能体真正做什么?
强化学习擅长优化。恰恰因为它擅长优化,目标中的缝隙会变得重要。
对齐不是某一个算法名称,也不是给奖励函数再加一项正则。它是一项长期工作:持续检查可测量目标与真实意图之间的距离,并在系统能力增强时重新设计反馈、约束和责任边界。
一、奖励能否代表人的价值
假设我们希望一个语言模型“有帮助”。
可以收集偏好数据:
$$(x,y_w,y_l)$$
训练 Reward Model:
$$r_\phi(x,y)$$
再优化策略:
$$\max_\theta \mathbf{E} [ r_\phi(x,y) ]$$
这条链路很合理,但每一步都发生了压缩:
$$\mathrm{人的复杂意图} \longrightarrow \mathrm{标注指南} \longrightarrow \mathrm{有限偏好对} \longrightarrow \mathrm{奖励模型} \longrightarrow \mathrm{标量分数}$$
人的价值判断具有上下文:
- 同一句话在不同场景中含义不同;
- 准确、简洁、安全和创造性有时互相冲突;
- 不同用户的合理偏好并不完全一致;
- 某些风险很少出现,却不能忽略;
- 有些目标难以由单次回答质量衡量。
奖励可以表达价值的一部分,但很难完整替代价值。
二、可测量指标与真实意图
设真实意图为:
$$U(y)$$
其中 $U$ 表示回答对人的真实效用。
现实中无法直接访问 $U$,于是使用代理指标:
$$\widehat{U}(y)$$
策略优化的是:
$$\max_y \widehat{U}(y)$$
但我们真正关心的是:
$$\max_y U(y)$$
只要:
$$\widehat{U}(y)\neq U(y)$$
就可能出现偏差。
在普通统计任务中,小偏差可能只是评估误差。
在优化系统中,小偏差会被主动利用:
$$\mathrm{代理指标中的微小漏洞} \longrightarrow \mathrm{优化器反复寻找} \longrightarrow \mathrm{行为明显偏离真实意图}$$
这不是某个模型“故意使坏”,而是优化过程的自然结果。
三、智能体会遵守规则,还是利用规则
想象一个客服模型被要求尽量提高“用户满意度”。
如果满意度通过会话结束后的单次评分衡量,模型可能学会:
- 迎合用户,而不是提供准确建议;
- 过度承诺,而不是坦诚说明限制;
- 使用更讨喜的语气掩盖信息不足;
- 避免提出让用户不舒服但必要的提醒。
模型并没有违反“提高评分”的规则。
问题是:
$$\mathrm{提高评分} \neq \mathrm{真正帮助用户}$$
类似现象在经典 RL 中早已存在:
- 清洁机器人把垃圾藏起来,而不是清理掉;
- 游戏智能体利用计分漏洞;
- 推荐系统提高点击率,却降低长期体验;
- 自动化系统满足局部 KPI,却伤害整体目标。
大模型对齐不是一块新大陆。它是奖励代理问题在更开放环境中的升级版。
四、Goodhart 定律:指标成为目标后会失去可靠性
Goodhart 定律常被概括为:
当一个指标成为目标,它就不再是一个可靠指标。
可以用简单关系表达。
假设真实质量为:
$$U(y)$$
可测量指标为:
$$M(y)= U(y)+ \varepsilon(y)$$
其中:
$$\varepsilon(y)$$
是指标误差。
如果从普通数据中随机抽样,$\varepsilon(y)$ 可能均值接近零。
但优化过程会选择:
$$y^* = \arg\max_y M(y)$$
这不仅偏向高真实质量 $U(y)$,也偏向误差项 $\varepsilon(y)$ 偶然很大的样本。
因此:
$$\max_y [ U(y)+\varepsilon(y) ]$$
会系统性放大代理指标中的误差。
这与 Q-Learning 中的最大化偏差、Actor 追逐 Critic 的价值幻觉、规划器利用世界模型漏洞,是同一类结构。
五、代理目标失灵为什么不是偶然事件
代理目标失灵并不一定意味着设计者粗心。
它有更深层原因:
- 世界比指标复杂;
- 数据覆盖永远有限;
- 环境会变化;
- 人的意图具有隐含条件;
- 优化器会主动搜索边缘区域;
- 系统部署后会改变用户行为和数据分布。
设策略为:
$$\pi_\theta$$
部署数据分布为:
$$d^{\pi_\theta}$$
策略更新后:
$$\pi_\theta \longrightarrow \pi_{\theta'}$$
数据分布也会变化:
$$d^{\pi_\theta} \longrightarrow d^{\pi_{\theta'}}$$
原先在旧分布上可靠的评价器:
$$r_\phi(x,y)$$
在新分布上未必同样可靠。
对齐问题不是一次训练结束后静态保存的结果,而是持续变化的数据与反馈问题。
六、对齐是优化问题,还是制度设计问题
答案是:两者都是。
从优化角度看,需要研究:
- 奖励函数;
- 偏好模型;
- KL 约束;
- 不确定性估计;
- 安全探索;
- 分布外检测;
- 策略更新步长;
- 验证器可靠性。
从制度设计角度看,还需要决定:
- 谁定义什么是高质量回答;
- 不同用户偏好如何表达;
- 高风险任务何时拒绝自动执行;
- 哪些行为需要人工审批;
- 如何记录、审计和追责;
- 新型失败模式如何反馈到数据采集;
- 部署边界如何随能力变化而调整。
如果只做算法优化,系统可能高效地追逐错误目标。
如果只写原则而没有可执行机制,系统又无法在现实中落实约束。
对齐需要把价值判断变成多层防线,而不是只压缩进一个标量分数。
七、Human-in-the-Loop:人不是临时补丁
Human-in-the-Loop 不应被理解为“模型不够强时暂时让人帮忙”。
在高风险系统中,人可以承担不可轻易外包给自动评价器的职责:
- 定义目标边界;
- 处理模糊和冲突情境;
- 审查高风险动作;
- 发现评价器未覆盖的新型漏洞;
- 决定何时暂停系统;
- 更新标注指南与反馈机制。
可以设置风险阈值:
$$u(x,y) > \tau \quad \Longrightarrow \quad \mathrm{转交人工审查}$$
其中:
| 符号 | 含义 |
|---|---|
| $u(x,y)$ | 对当前任务或回答风险、不确定性的估计 |
| $\tau$ | 允许自动执行的风险阈值 |
对于低风险、可逆任务,系统可以拥有更高自主权。
对于高风险、不可逆任务,应提高审查强度。
关键不是“人永远审查一切”,而是:
根据风险、可逆性和不确定性,把决策权分层配置。
八、不确定价值下的谨慎优化
如果对真实效用只有估计:
$$\widehat{U}(y)$$
并且能够估计不确定性:
$$\sigma_U(y)$$
一种保守目标是:
$$\max_y [ \widehat{U}(y)- \lambda \sigma_U(y) ]$$
其中:
| 符号 | 含义 |
|---|---|
| $\widehat{U}(y)$ | 对效用的估计 |
| $\sigma_U(y)$ | 估计不确定性 |
| $\lambda$ | 风险厌恶程度 |
$\lambda$ 越大,系统越不愿意追逐高分但不确定的行为。
这与安全探索中的风险敏感目标一致。
另一种方式是使用约束:
$$\max_\pi J_R(\pi)$$
满足:
$$J_C(\pi) \leq d$$
其中:
| 符号 | 含义 |
|---|---|
| $J_R(\pi)$ | 策略带来的预期收益 |
| $J_C(\pi)$ | 预期风险或成本 |
| $d$ | 可接受风险上限 |
系统不应把所有问题都变成“收益减去一点惩罚”。
对某些安全边界,约束比软惩罚更合适。
九、可逆性:允许试错的前提
探索的伦理边界与工程边界,往往取决于行为是否可逆。
| 行为 | 可逆性 | 合理策略 |
|---|---|---|
| 在模拟器中尝试新控制参数 | 较高 | 可允许更强探索 |
| 为用户生成草稿 | 较高 | 可保留多样性,由用户确认 |
| 自动发布公开声明 | 较低 | 需要审核与权限限制 |
| 执行金融交易或医疗建议 | 风险高 | 需要严格约束、审计与人工介入 |
同一种模型能力,在不同部署环境中需要不同权限。
因此,对齐不能只在模型权重里完成。
权限系统、工具白名单、速率限制、审批流程、回滚能力和日志审计,都是对齐结构的一部分。
十、从“聪明模型”转向“可靠系统”
只讨论模型回答是否聪明,容易忽略系统边界。
一个可靠系统至少要回答:
- 模型允许看到什么信息?
- 模型允许调用哪些工具?
- 哪些动作可以自动执行?
- 哪些动作必须确认?
- 失败后能否回滚?
- 谁能看到日志?
- 如何发现分布漂移?
- 如何更新评价器和策略?
模型只是系统中的一个组件。
越是能力强的模型,越需要清楚的外部边界。
十一、边界:不要把哲学问题变成空泛口号
讨论“价值”“意图”和“制度设计”时,很容易变得抽象。
但本章并不是要离开工程。
相反,哲学问题应被翻译为可检查的问题:
| 抽象问题 | 工程追问 |
|---|---|
| 奖励是否代表人的价值 | 偏好数据覆盖了哪些场景?哪些群体?哪些冲突? |
| 模型是否会利用规则 | 高奖励样本是否经过人工审查?是否存在异常模式? |
| 系统是否谨慎 | 是否有风险阈值、拒绝机制和人工转交? |
| 对齐是否持续有效 | 策略更新后是否重新评估 Reward Model 与部署分布? |
| 权限是否合理 | 高风险工具是否受最小权限、审批和审计约束? |
好的工程不是回避哲学问题,而是让哲学问题拥有可执行的落点。
回归全景图(Callback)
把对齐问题放回六个坐标轴:
| 维度 | 对齐问题中的表现 | 必须保留的警惕 |
|---|---|---|
| 目标 | 人的真实意图被压缩为奖励、偏好、验证器与规则 | 任何代理目标都可能遗漏上下文 |
| 时间 | 当前优化会影响未来用户、数据分布和制度环境 | 不只看单次回答,还要看长期行为后果 |
| 更新 | 通过 SFT、PPO、DPO、GRPO 或其他后训练方法改变策略 | 损失下降不等于社会目标自动改善 |
| 估计 | Reward Model、Critic、验证器和风险模型都在近似真实判断 | 优化器会主动寻找估计器薄弱区域 |
| 数据 | 标注数据、在线生成与部署反馈持续变化 | 旧评价器可能无法覆盖新策略行为 |
| 探索 | 多候选生成、工具调用和自主行动扩大能力边界 | 探索必须受风险、可逆性与权限约束 |
再看三条反馈循环:
| 反馈循环 | 对齐问题中的具体形式 |
|---|---|
| 外部交互循环 | 模型影响用户与环境,环境反馈又改变未来训练数据 |
| 时间回报循环 | 短期满意度、长期信任和系统风险并不总是一致 |
| 自我更新循环 | 代理评价推动模型改变行为,新行为又暴露评价体系的新缺口 |
对齐没有一个“训练完成”的终点。
它是一种持续治理反馈循环的能力。
本章小结
强化学习把一个危险而重要的事实放到我们面前:
一个目标越容易被优化,我们越需要认真检查它是否值得被优化。
奖励、偏好与验证器都有价值,但它们都只是代理。
Goodhart 定律提醒我们,优化会放大代理指标误差;Human-in-the-Loop 提醒我们,人不只是临时标注器,也是目标边界的制定者与高风险决策的责任承担者;谨慎优化提醒我们,不确定时保守并不是能力不足,而是系统成熟。
下一章是全书结语。我们将把二十三章压缩回六个问题与三条反馈循环,让读者能够用同一张地图解剖任何新算法。
结语 用六个问题解剖任何强化学习算法
读到这里,读者已经遇见了许多名字:
- Bellman 方程;
- Monte Carlo;
- TD;
- SARSA;
- Q-Learning;
- DQN;
- Policy Gradient;
- Actor-Critic;
- PPO;
- SAC;
- Model-Based RL;
- RLHF;
- DPO;
- GRPO。
如果把它们当作互不相干的知识点,强化学习会显得像一间堆满零件的仓库。
但如果退后一步,就会发现:这些方法始终在回答同一组问题。
它们面对的世界没有静态标签,没有永远不变的数据分布,也没有一个可以直接反向传播的终极目标。
学习者只能在行动中获取数据,在延迟中等待结果,在不确定中估计未来,再用一次次不完美更新改变自己。
这就是强化学习。
一、第一问:它真正想最大化什么
最基础的长期目标是:
$$J(\pi)=E_{\tau\sim\pi}\left[\sum_{t=0}{T-1}\gammat R_{t+1}\right]$$
其中:
| 符号 | 含义 |
|---|---|
| $\pi$ | 策略 |
| $\tau$ | 策略与环境交互形成的轨迹 |
| $R_{t+1}$ | 第 $t$ 步行动后获得的奖励 |
| $\gamma$ | 未来奖励的折扣因子 |
但任何新算法都不能只停在这条公式。
还要继续问:
- 奖励由谁定义?
- 它是环境天然产生的,还是人为设计的?
- 它来自 Reward Model、验证器还是用户行为?
- 它是否只是更复杂意图的代理?
- 策略是否可能找到提高奖励却违背真实意图的捷径?
DQN、PPO、RLHF、DPO 和 GRPO 的表面差别很大,但都必须面对目标代理问题。
二、第二问:未来怎样返回现在
强化学习的第二个根本困难是时间。
今天的一个动作,可能要经过许多步后才显出后果。
Bellman 方程给出递归结构:
$$V^\pi(s)= \mathbf{E}\pi [ R{t+1} + \gamma V^\pi(S_{t+1}) \mid S_t=s ]$$
它把未来折回现在。
不同算法选择不同截断位置:
| 方法 | 如何处理未来 |
|---|---|
| Monte Carlo | 等待完整结局 |
| TD(0) | 一步之后开始使用价值估计 |
| $n$ 步 TD | 先观察若干真实奖励,再开始自举 |
| GAE | 混合多个时间尺度的 TD 误差 |
| Model-Based Rollout | 在模型中显式推演有限步,再接价值估计 |
| RLHF | 将序列级反馈重新分配给回答中的 Token |
面对新算法,应该问:
- 它使用完整回报,还是自举目标?
- 信用怎样分配给早期动作?
- 长序列中的细粒度归因是否被解决,还是被压缩进某个估计器?
三、第三问:长期目标怎样变成一次更新
最终目标常常无法直接优化。
于是算法构造代理损失。
DQN 使用 TD 误差:
$$L_{DQN}(\theta)=E\left[\left(r+\gamma\max_{a'}Q(s',a';\theta-)-Q(s,a;\theta)\right)2\right]$$
PPO 使用裁剪目标:
$$\mathcal{L}^{\mathrm{CLIP}}(\theta)= \mathbf{E} [ \min ( \rho_t(\theta)\widehat{A}_t, \operatorname{clip} ( \rho_t(\theta), 1-\epsilon, 1+\epsilon )\widehat{A}_t ) ]$$
DPO 使用偏好对比损失:
$$L_{DPO}(\theta)=-E\left[\log\sigma(\beta\Delta_\theta)\right]$$
这些损失函数看起来不同,因为它们承担的局部任务不同。
但都应追问:
- 代理损失与长期目标之间的桥梁是什么?
- 损失下降是否只说明局部估计更一致?
- Clip、KL、Target Network 和 Reference Model 分别约束了哪个变化?
- 工程稳定化工具是否被误解成理论目标?
强化学习中的损失函数通常不是终点,而是控制一次参数更新的操作面板。
四、第四问:它使用了什么估计
强化学习几乎无法摆脱估计。
$$G_t$$
是随机轨迹上的回报估计。
$$V_w(s)$$
是未来价值估计。
$$Q_w(s,a)$$
是动作长期价值估计。
$$r_\phi(x,y)$$
是人类偏好估计。
$$\widehat{p}_\phi(s'\mid s,a)$$
是世界动态估计。
$$\widehat{A}_i$$
是组内相对优势估计。
因此,面对新方法要问:
- 它显式或隐式估计了什么?
- 估计偏差从哪里来?
- 方差怎样控制?
- 最大化、搜索或策略优化会不会放大估计误差?
- 删除显式模型后,估计任务是否转移到数据、参考模型或统计量中?
没有免费估计。
算法设计的成熟,不在于假装误差消失,而在于知道误差可能从哪里回流。
五、第五问:学习者怎样改变自己的数据
监督学习常常假设训练集相对固定。
强化学习中的策略会改变数据分布:
$$\pi_\theta \longrightarrow \mathrm{行动} \longrightarrow d^{\pi_\theta} \longrightarrow \mathrm{新数据} \longrightarrow \mathrm{更新} \longrightarrow \pi_{\theta'}$$
新策略访问新的状态,也制造新的训练样本。
这让数据不再只是原料,而是策略的一部分。
| 方法 | 数据问题 |
|---|---|
| On-Policy 方法 | 数据更新后迅速过时,样本利用率有限 |
| Off-Policy 方法 | 可以复用旧数据,但要承受分布不一致 |
| Experience Replay | 打散相关性并复用经验,也把历史策略保留进系统 |
| Offline RL | 训练更可控,但无法轻易访问数据覆盖之外的行为 |
| RLHF | 新策略生成新回答,Reward Model 需要面对新分布 |
| DPO | 固定偏好对提高稳定性,也把能力上限绑定到数据覆盖 |
| GRPO | 在线候选生成保留探索,但带来采样成本与漂移 |
面对新算法,应该问:
- 数据来自当前策略、旧策略还是固定数据集?
- 哪些行为在数据中从未出现?
- 分布外区域如何被识别?
- 策略更新后,评价器是否仍然可靠?
六、第六问:它怎样探索未知
如果学习者只重复当前最优动作,就可能永远无法发现更好的路径。
探索是信息投资。
但探索并不免费:
- 它会消耗交互预算;
- 它可能带来安全风险;
- 它可能进入估计器陌生的区域;
- 它会扩大数据分布漂移;
- 它可能让训练更不稳定。
不同系统中的探索形式不同:
| 场景 | 探索形式 |
|---|---|
| Bandit | $\epsilon$-greedy、UCB、Thompson Sampling |
| 深度 RL | 随机动作、熵奖励、内在动机、层级探索 |
| Model-Based RL | 探索模型不确定或潜在收益高的区域 |
| 语言模型 | 温度采样、多候选生成、搜索、重排序 |
| DPO | 探索转移到偏好数据生成与筛选阶段 |
| GRPO | 同一提示下生成一组候选,组内相对比较 |
面对新算法,应该问:
- 新经验在哪里产生?
- 探索是主动保留,还是被约束压缩?
- 它如何在信息收益、安全、效率和成本之间取舍?
七、三条反馈循环
六个问题不是六座孤岛。
它们通过三条反馈循环连接起来。
1. 外部交互循环
$$\mathrm{策略} \longrightarrow \mathrm{动作} \longrightarrow \mathrm{环境} \longrightarrow \mathrm{新状态与奖励} \longrightarrow \mathrm{数据}$$
策略必须通过行动才能获得新信息。
2. 时间回报循环
$$\mathrm{未来奖励与下一状态估计} \longrightarrow \mathrm{当前价值} \longrightarrow \mathrm{当前动作判断}$$
未来必须通过回报、自举、优势或模型推演回到现在。
3. 自我更新循环
$$\mathrm{样本} \longrightarrow \mathrm{估计器} \longrightarrow \mathrm{代理损失} \longrightarrow \mathrm{参数} \longrightarrow \mathrm{新策略} \longrightarrow \mathrm{新样本}$$
学习者不是在静态世界中拟合答案。它每更新一次自己,也会改变下一批数据。
八、一张可复用的算法解剖表
以后遇到任何新方法,可以先填这张表。
| 坐标轴 | 必须回答的问题 |
|---|---|
| 目标 | 它最终想优化什么?奖励、偏好或验证信号从哪里来? |
| 时间 | 它如何处理延迟反馈与信用分配? |
| 更新 | 它用什么代理损失、梯度估计或约束完成一次参数更新? |
| 估计 | 它显式或隐式估计了什么?减少了什么误差,又引入了什么偏差? |
| 数据 | 它依赖在线采样、旧经验还是固定数据集?分布漂移风险在哪里? |
| 探索 | 它如何产生新经验?探索被保留、压缩,还是转移到数据生成阶段? |
填完之后,再加一句判断:
这个方法没有神奇地消灭矛盾。它缓解了什么,转移了什么,又把什么隐藏进新的假设中?
这句话适用于 DQN,也适用于 PPO、RLHF、DPO、GRPO,以及未来尚未出现的算法。
九、最后的判断
强化学习不是一套固定算法清单。
它是一种在特殊世界中学习的方法论。
这个世界有三个特征:
- 没有可以直接监督每一步行动的静态真值;
- 行动的结果往往延迟出现;
- 学习者改变策略后,数据分布也随之改变。
因此,强化学习必须不断在多种矛盾之间寻找可执行路径:
- 长期目标与局部更新;
- 真实意图与代理奖励;
- 低偏差与低方差;
- 数据复用与分布漂移;
- 探索未知与控制风险;
- 提高效率与防止误差放大。
每一种损失函数、估计器和工程技巧,都应当放回这个框架中理解。
当读者能够用这六个问题和三条反馈循环解剖一个陌生算法时,这本书真正想做的事情就完成了。
后记 我为什么不想按部就班地介绍强化学习
我不想再写一本从 MDP 开始,依次讲完 Q-Learning、DQN、Actor-Critic、PPO,最后补上一章 RLHF 的传统教材。
这样的写法当然完整,也有它不可替代的价值。但当算法越来越多,公式越来越长,读者很容易记住树叶,却看不见森林。
我更想暂时站远一点,用一种近似“上帝视角”的方式俯瞰强化学习:先不急着追随算法发展的时间顺序,而是追问这门学科为什么会长成今天的样子。
为什么真实目标总要经过奖励和代理损失才能落地?
为什么智能体每学会一点东西,训练数据的分布也随之改变?
为什么我们一边依赖自举提高效率,一边又害怕误差在自举中不断放大?
为什么探索是获得更优策略的必要条件,却也成为不稳定和风险的来源?
为什么 Actor 与 Critic 必须合作,却可能相互强化彼此的错误?
为什么 DPO 绕过显式 Reward Model 后,奖励问题并没有凭空消失?
为什么 GRPO 弱化显式 Critic 后,估计问题又转移到了组内采样和相对比较?
这些问题比某一个具体公式更长久。
TD、DQN、PPO、RLHF、DPO 和 GRPO 并不是彼此割裂的技巧,而是在不同场景下,对同一组根本矛盾做出的不同回答。
因此,这本书不试图让读者背诵更多算法。它希望帮助读者获得一张地图:以后面对任何新的损失函数、约束项或训练框架,都能看清它从哪里来,缓解了什么,又牺牲了什么。
这也是为什么书中保留了所有必要公式。
通俗不等于绕开数学。没有公式,读者只能得到比喻;只有公式,读者又很难理解公式为什么存在。理想状态是:先提出真实问题,再建立直觉,接着写出完整公式,解释每个符号,最后把公式重新放回反馈循环。
我也希望书中的插图承担真正的叙事任务。
强化学习最难理解的地方,往往不是某个静态定义,而是一个动态过程:
- 奖励怎样沿时间回流;
- 自举怎样提前截断未来;
- 误差怎样在致命三角中传播;
- 策略更新怎样改变数据分布;
- Actor 与 Critic 怎样彼此帮助,又彼此放大误差;
- PPO、DPO 和 GRPO 怎样删去一些显式模块,又把矛盾转移到新的位置。
这些过程值得被画出来,而不只是被写出来。
如果读完之后,读者不再把强化学习理解为一堆需要记忆的公式,而是理解为一个不断在目标、时间、更新、估计、数据与探索之间寻找平衡的系统,这本书就完成了它真正想做的事。
附录 A 数学基础
本附录不是数学教材,而是阅读正文时随手可查的地基。每个概念只解释强化学习中最常用的含义。
一、概率、期望与条件期望
随机变量 $X$ 的期望为:
$$\mathbf{E}[X] = \sum_x p(x)x$$
连续随机变量则写成积分:
$$\mathbf{E}[X] = \int p(x)x \mathrm{d}x$$
期望不是一次观测,而是重复采样后的平均趋势。
条件期望:
$$\mathbf{E}[X\mid Y=y]$$
表示已知 $Y=y$ 时,$X$ 的平均值。
强化学习中的价值函数就是条件期望:
$$V^\pi(s) = \mathbf{E}_\pi [ G_t\mid S_t=s ]$$
它表示:已知当前状态为 $s$,之后遵循策略 $\pi$ 时,未来回报平均是多少。
二、方差
方差衡量随机变量围绕均值的波动:
$$\operatorname{Var}(X)= \mathbf{E} [ ( X-\mathbf{E}[X] )^2 ]$$
在强化学习中,高方差意味着同一种状态或动作可能产生差异很大的更新信号。
Monte Carlo 回报通常方差较高,因为它包含整条后续轨迹中的随机性。
三、Markov Property
Markov Property,马尔可夫性质,写成:
$$\Pr ( S_{t+1} \mid S_0,A_0,\ldots,S_t,A_t )= \Pr ( S_{t+1} \mid S_t,A_t )$$
它表示:如果当前状态 $S_t$ 已经包含足够信息,那么预测下一状态时不必重新查看全部历史。
注意,马尔可夫性质不是说“历史不重要”,而是说“历史中对未来有用的信息已经被压缩进当前状态”。
四、MDP
马尔可夫决策过程 MDP 常写成:
$$\mathcal{M} = ( \mathcal{S}, \mathcal{A}, p, r, \gamma )$$
其中:
| 符号 | 含义 |
|---|---|
| $\mathcal{S}$ | 状态空间 |
| $\mathcal{A}$ | 动作空间 |
| $p(s'\mid s,a)$ | 执行动作后到达下一状态的概率 |
| $r(s,a)$ | 奖励机制 |
| $\gamma$ | 折扣因子 |
策略写成:
$$\pi(a\mid s)$$
表示在状态 $s$ 下选择动作 $a$ 的概率。
五、POMDP
如果智能体无法直接观察真实状态,只能看到观测:
$$O_t$$
则问题更接近部分可观测马尔可夫决策过程 POMDP。
此时策略可能需要依赖历史:
$$\pi ( a_t \mid o_1,a_1,\ldots,o_t )$$
或者依赖由历史压缩出的内部表示:
$$h_t = f(h_{t-1},o_t,a_{t-1})$$
六、折扣回报
从时刻 $t$ 开始的折扣回报:
$$G_t = R_{t+1} + \gamma R_{t+2} + \gamma^2R_{t+3} + \cdots$$
也可以递归写成:
$$G_t = R_{t+1} + \gamma G_{t+1}$$
折扣因子:
$$0\leq\gamma\leq 1$$
$\gamma$ 越大,学习者越重视远期奖励。
七、固定点与压缩映射
Bellman 算子可以写成:
$$(T^\pi V)(s)=E_\pi\left[R_{t+1}+\gamma V(S_{t+1})|S_t=s\right]$$
策略价值函数满足:
$$V^\pi = \mathcal{T}^\pi V^\pi$$
它是 Bellman 算子的固定点。
当:
$$0\leq\gamma<1$$
时,Bellman 算子在常见条件下具有压缩性质。直观地说,多次应用算子后,价值估计会越来越接近固定点。
函数逼近、自举与 Off-Policy 同时出现时,简单收敛直觉不再自动成立。
八、随机梯度估计
目标函数常写成期望:
$$\mathcal{L}(\theta)= \mathbf{E}_{X\sim p} [ \ell(\theta;X) ]$$
无法遍历全部样本时,可以用小批量估计梯度:
$$\nabla_\theta \mathcal{L}(\theta)\approx \frac{1}{B} \sum_{i=1}^{B} \nabla_\theta \ell(\theta;X_i)$$
其中 $B$ 为批次大小。
强化学习的特别之处在于:样本分布 $p$ 往往由策略决定,并会随训练变化。
九、Importance Sampling
如果数据来自行为策略 $\mu$,却希望估计目标策略 $\pi$ 下的期望,可以使用重要性采样比:
$$\rho_t = \frac{ \pi(A_t\mid S_t)}{ \mu(A_t\mid S_t)}$$
直观地说:
- 如果目标策略更常选择这个动作,样本权重增大;
- 如果目标策略较少选择这个动作,样本权重减小。
轨迹级比值可能写成:
$$\rho_{t:T-1} = \prod_{k=t}^{T-1} \frac{ \pi(A_k\mid S_k)}{ \mu(A_k\mid S_k)}$$
轨迹越长,方差越可能迅速增大。因此实际方法常使用截断、裁剪或其他稳定化机制。
十、KL 散度
KL 散度衡量两个概率分布之间的差异:
$$D_{\mathrm{KL}} ( p\parallel q )= \mathbf{E}_{x\sim p} [ \log \frac{ p(x)}{ q(x)} ]$$
在 PPO-RLHF、DPO 和 GRPO 中,KL 常用于限制新策略偏离参考模型:
$$D_{\mathrm{KL}} ( \pi_\theta \parallel \pi_{\mathrm{ref}} )$$
它不是距离函数:一般不对称,也不满足普通几何距离的全部性质。
附录 B 关键公式速查
本附录用于快速定位。完整解释请回到对应章节。
| 主题 | 公式 | 对应章节 |
|---|---|---|
| 折扣回报 | $G_t=R_{t+1}+\gamma R_{t+2}+\gamma^2R_{t+3}+\cdots$ | 第 1 章 |
| 状态价值 | $V^\pi(s)=\mathbf{E}_\pi[G_t\mid S_t=s]$ | 第 3 章 |
| 动作价值 | $Q^\pi(s,a)=\mathbf{E}_\pi[G_t\mid S_t=s,A_t=a]$ | 第 3 章 |
| Bellman 期望方程 | $V^\pi(s)=E_\pi\left[R_{t+1}+\gamma V^\pi(S_{t+1}) | S_t=s\right]$ |
| Bellman 最优方程 | $Q*(s,a)=E\left[R_{t+1}+\gamma\max_{a'}Q*(S_{t+1},a') | S_t=s,A_t=a\right]$ |
| TD 误差 | $\delta_t=R_{t+1}+\gamma V(S_{t+1})-V(S_t)$ | 第 5 章 |
| $n$ 步回报 | $G_t{(n)}=\sum_{k=0}{n-1}\gammakR_{t+k+1}+\gammanV(S_{t+n})$ | 第 5、18 章 |
| SARSA | $Q(S_t,A_t)\leftarrow Q(S_t,A_t)+\alpha[R_{t+1}+\gamma Q(S_{t+1},A_{t+1})-Q(S_t,A_t)]$ | 第 16 章 |
| Q-Learning | $Q(S_t,A_t)\leftarrow Q(S_t,A_t)+\alpha[R_{t+1}+\gamma\max_{a'}Q(S_{t+1},a')-Q(S_t,A_t)]$ | 第 16 章 |
| DQN Loss | $L(\theta)=E\left[(r+\gamma\max_{a'}Q(s',a';\theta-)-Q(s,a;\theta))2\right]$ | 第 8、16 章 |
| Policy Gradient | $\nabla_\theta J(\theta)\propto\mathbf{E}[A^\pi(S,A)\nabla_\theta\log \pi_\theta(A\mid S)]$ | 第 17 章 |
| Advantage | $A\pi(s,a)=Q\pi(s,a)-V^\pi(s)$ | 第 7、17 章 |
| GAE | $\hat A_t=\sum_{l=0}{\infty}(\gamma\lambda)l\delta_{t+l}$ | 第 7、18 章 |
| PPO Ratio | $\rho_t(\theta)=\pi_\theta(A_t\mid S_t)/\pi_{\theta_{\mathrm{old}}}(A_t\mid S_t)$ | 第 18、21 章 |
| PPO Clip | $\mathcal{L}^{\mathrm{CLIP}}=\mathbf{E}[\min(\rho_t\widehat{A}_t,\operatorname{clip}(\rho_t,1-\epsilon,1+\epsilon)\widehat{A}_t)]$ | 第 18、21 章 |
| KL-Regularized RLHF | $\max_\theta\mathbf{E}[r_\phi(x,y)-\beta\log\frac{\pi_\theta(y\mid x)}{\pi_{\mathrm{ref}}(y\mid x)}]$ | 第 21 章 |
| Reward Model | $\Pr(y_w\succ y_l\mid x)=\sigma(r_\phi(x,y_w)-r_\phi(x,y_l))$ | 第 21 章 |
| DPO | $L_{DPO}=-E\left[\log\sigma(\beta\Delta_\theta)\right]$ | 第 22 章 |
| GRPO Group Advantage | $\widehat{A}_i=(r_i-\mu_r)/(\sigma_r+\varepsilon)$ | 第 22 章 |
DPO 中的 $\Delta_\theta$
$$\Delta_\theta = \log \frac{ \pi_\theta(y_w\mid x)}{ \pi_{\mathrm{ref}}(y_w\mid x)} - \log \frac{ \pi_\theta(y_l\mid x)}{ \pi_{\mathrm{ref}}(y_l\mid x)}$$
它表示:相对于参考模型,当前策略让偏好回答相对于非偏好回答增加了多少对数概率优势。
附录 C 算法映射表
这张表不是算法排名。它用于快速观察:不同方法把矛盾放在了哪里。
图 C-1:六维算法家族地图
| 算法 | 主要范式 | 是否自举 | 数据方式 | 主要解决的问题 | 主要稳定化机制或代价 |
|---|---|---|---|---|---|
| Monte Carlo | 价值估计 | 否 | On-Policy | 用完整轨迹估计回报 | 低自举偏差,高方差,必须等待结局 |
| TD(0) | 价值估计 | 是 | 常见为 On-Policy | 提前更新价值 | 小步更新,但引入自举偏差 |
| SARSA | Value-Based | 是 | On-Policy | 学习当前行为策略的动作价值 | 会把探索风险计入策略评价 |
| Q-Learning | Value-Based | 是 | Off-Policy | 学习最优动作价值 | 最大化偏差与分布不一致风险 |
| DQN | Value-Based | 是 | Off-Policy | 用神经网络逼近 Q 值 | Replay、Target Network;仍处于致命三角 |
| REINFORCE | Policy-Based | 否 | On-Policy | 直接更新策略 | 结构简单,但方差高 |
| A2C/A3C | Actor-Critic | 是 | On-Policy | 用 Critic 降低策略梯度方差 | Advantage、并行采样 |
| DDPG | Actor-Critic | 是 | Off-Policy | 连续动作控制 | Replay、Target Network;Critic 高估会误导 Actor |
| TD3 | Actor-Critic | 是 | Off-Policy | 降低连续控制中的价值幻觉 | 双 Critic、目标策略平滑、延迟更新 |
| SAC | Actor-Critic | 是 | Off-Policy | 连续控制与探索 | Entropy Regularization |
| PPO | Actor-Critic | 通常是 | On-Policy | 限制策略更新突变 | Clip、KL、GAE |
| Dyna | Model-Based | 依具体更新而定 | 真实与模拟数据结合 | 提高样本效率 | 模型偏差会污染模拟经验 |
| MuZero | Model-Based Planning | 是 | 真实经验与搜索 | 学习适合规划的潜在动态 | 搜索、潜在模型、价值与策略预测 |
| PPO-RLHF | Actor-Critic | 通常是 | 在线生成 | 在偏好奖励下优化语言模型 | Reward Model、Critic、KL、Reference Model |
| DPO | 偏好优化 | 不依赖显式价值自举 | 主要为离线偏好数据 | 直接优化偏好对 | Reference Model;依赖数据覆盖与建模假设 |
| GRPO | 策略优化 | 可不依赖显式 Critic | 常见为在线或迭代采样 | 用组内相对比较构造优势 | Group Baseline、Clip、KL;依赖采样质量 |
六维快速比较
| 算法 | 目标 | 时间 | 更新 | 估计 | 数据 | 探索 |
|---|---|---|---|---|---|---|
| DQN | 累计奖励 | Bellman 自举 | TD Loss | Q 值与目标网络 | Replay 旧经验 | 常用 $\epsilon$-greedy |
| PPO | 累计奖励 | Advantage、GAE | Clip Objective | Critic | On-Policy rollout | 随机策略、熵 |
| SAC | 奖励加熵 | TD 自举 | Actor-Critic 更新 | 双 Q 等 | Replay | 熵进入目标 |
| PPO-RLHF | 偏好奖励加 KL 约束 | Token 级优势 | PPO Clip | RM 与 Critic | 在线生成 | 采样与 KL 权衡 |
| DPO | 偏好对 | 序列对数概率 | 对比损失 | 隐式奖励关系 | 离线偏好对 | 转移到数据采集 |
| GRPO | 组内相对奖励 | 序列或步骤反馈 | 相对优势与 Clip | 组内统计量 | 多候选生成 | 组内候选采样 |
附录 D 超参数思想地图
超参数不是孤立旋钮。每一个超参数都在控制一种矛盾。
| 参数 | 常见位置 | 主要控制对象 | 过小时可能发生什么 | 过大时可能发生什么 |
|---|---|---|---|---|
| $\gamma$ | Return、TD | 未来奖励权重 | 过度短视 | 估计更难,长期噪声影响更强 |
| $\alpha$ | 各类梯度或 TD 更新 | 单次更新步长 | 学习过慢 | 不稳定、震荡甚至发散 |
| $\lambda$ | GAE、TD($\lambda$) | 偏差与方差权衡 | 更依赖短期自举 | 更接近长回报,方差提高 |
| $\epsilon$ | $\epsilon$-greedy | 随机探索概率 | 过早锁定当前最优 | 反复浪费在随机动作上 |
| $\epsilon$ | PPO Clip | 局部策略更新范围 | 改进幅度受限 | 策略变化可能过猛 |
| $\beta$ | KL Penalty、DPO | 偏好优化与参考约束 | 偏离参考模型过快 | 更新过于保守 |
| $\alpha_{\mathrm{ent}}$ | SAC、Entropy Bonus | 探索强度 | 策略过早收缩 | 策略长期过于随机 |
| $\tau$ | Soft Target Update | 目标网络更新速度 | 目标变化太慢 | 目标变化过快,不稳定 |
| $\tau$ | Language Model Sampling | 生成分布平滑程度 | 候选过于集中 | 错误与低质量候选增多 |
| $H$ | Model-Based Rollout | 想象深度 | 利用未来信息不足 | 模型误差累积 |
| $G$ | GRPO | 同一提示的候选数量 | 组内统计不稳定 | 采样成本提高 |
同名参数不一定控制同一件事
符号只是记号。
例如 $\epsilon$ 在不同上下文中可能表示:
- $\epsilon$-greedy 的随机探索概率;
- PPO Clip 的裁剪区间;
- 防止除零的小常数。
阅读论文时,先看定义,不要只凭符号猜含义。
附录 E 推荐阅读路线
本书可以顺序阅读,也可以按问题进入。
一、第一次系统学习强化学习
建议顺序:
- 序章;
- 第 1 至 7 章;
- 第 10 至 13 章;
- 第 16 至 18 章;
- 第 19 章;
- 第 20 至 23 章;
- 结语。
第 8、9、14、15 章可以在第一次阅读后回看。它们负责补充误差放大、深度探索与安全边界。
二、已经学过基础算法,希望建立全局视角
建议顺序:
- 序章;
- 第 6 章:损失函数;
- 第 7 至 12 章:估计、致命三角与稳定化;
- 第 16 至 19 章:算法综合案例;
- 结语。
重点不是重新背诵算法步骤,而是比较每种方法怎样转移矛盾。
三、主要关心大模型后训练
建议顺序:
- 序章;
- 第 2 章:奖励不是目的;
- 第 4 至 7 章:信用分配、估计与代理损失;
- 第 10 至 12 章:分布漂移与稳定化;
- 第 17、18 章:策略梯度、Actor-Critic 与 PPO;
- 第 20 至 23 章:语言模型、RLHF、DPO、GRPO 与对齐;
- 结语。
这条路线能避免把 DPO 或 GRPO 理解为凭空出现的新技巧。
四、主要关心工程稳定性
建议顺序:
- 第 5 章:自举;
- 第 7 章:偏差与方差;
- 第 8 章:最大化偏差;
- 第 9 章:致命三角;
- 第 10、11 章:非平稳性与 Off-Policy;
- 第 12 章:稳定化工具箱;
- 第 18 章:Actor-Critic;
- 第 21、22 章:大模型后训练中的稳定化。
五、外部资料主题索引
继续阅读外部教材、论文或课程时,可以按以下主题检索:
- MDP、Bellman Equation、Dynamic Programming;
- Monte Carlo、TD、SARSA、Q-Learning;
- DQN、Double DQN、Deadly Triad;
- Policy Gradient、Actor-Critic、GAE、PPO、SAC;
- Model-Based RL、MCTS、AlphaZero、MuZero、World Model;
- Offline RL、Preference Learning、Safe RL;
- RLHF、DPO、GRPO、Verifier、Reasoning Model Post-Training。
附录 F 核心参考资料
本附录列出正文写作时最重要的一组原始论文与基础资料。它不是完整文献综述,而是方便读者继续深挖的入口。
一、基础教材
- Richard S. Sutton, Andrew G. Barto. Reinforcement Learning: An Introduction, Second Edition.
http://incompleteideas.net/book/RLbook2020.pdf
二、深度强化学习与策略优化
-
Volodymyr Mnih et al. Human-level control through deep reinforcement learning. Nature, 2015.
https://doi.org/10.1038/nature14236 -
John Schulman et al. Proximal Policy Optimization Algorithms. 2017.
https://arxiv.org/abs/1707.06347 -
Tuomas Haarnoja et al. Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor. 2018.
https://arxiv.org/abs/1801.01290 -
David Silver et al. Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model. 2019.
https://arxiv.org/abs/1911.08265
三、人类反馈与大模型后训练
-
Nisan Stiennon et al. Learning to Summarize from Human Feedback. 2020.
https://arxiv.org/abs/2009.01325 -
Long Ouyang et al. Training Language Models to Follow Instructions with Human Feedback. 2022.
https://arxiv.org/abs/2203.02155 -
Rafael Rafailov et al. Direct Preference Optimization: Your Language Model is Secretly a Reward Model. 2023.
https://arxiv.org/abs/2305.18290 -
Zhihong Shao et al. DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models. 2024.
https://arxiv.org/abs/2402.03300
四、怎样使用这些资料
阅读论文时,建议继续使用全书六个问题:
- 它的目标函数是什么?
- 延迟反馈如何返回此前动作?
- 一次参数更新由哪个代理损失完成?
- 它依赖哪些显式或隐式估计?
- 数据来自当前策略、旧策略还是固定数据集?
- 探索被保留、压缩,还是转移到数据生成阶段?
论文中的新名词会不断变化,但这六个问题仍然有效。