《量子计算机》全书
引言 我为什么要写这本书
我第一次认真听人讲量子计算,是在读博士的时候。
那时我在实验室里,常听师兄师姐提起一位老师:清华计算机系的应明生老师。
他的经历很特别,研究方向也很超前。
在很多人还只是把量子计算当成一个遥远名词的时候,他已经在这个方向上做了很深的工作。
我不是一开始就懂量子计算。
恰恰相反,刚接触它的时候,我和很多人一样,第一反应是:
这东西是不是太物理了?
是不是要先学一大堆薛定谔方程?
是不是没有量子力学背景就根本进不去?
后来,我经常参加系里的讲座。
其中有不少是应明生老师团队关于量子计算的报告。
那些讲座给我最大的感受是:
真正懂这个领域的人,反而不会一上来用复杂公式把你压住。
他们会先抓住最核心的规则。
只要规则讲清楚,量子计算就没有那么玄。
我印象很深的一次,是听到段润尧老师讲量子计算的入门思路。
他说,理解量子计算,可以先从量子力学的几条基本规则入手。
把这些规则和计算机专业熟悉的逻辑门对照起来,就能慢慢走到量子态、量子门和量子线路。
这句话对我很有启发。
因为它把量子计算从“神秘物理”拉回到了“计算”本身。
计算机专业的人,熟悉比特、逻辑门、电路、算法。
如果我们能从这些熟悉的东西出发,再一步一步替换成量子版本,就会发现:
比特 -> 量子比特
逻辑门 -> 量子门
经典电路 -> 量子线路
确定输出 -> 概率测量
普通并行 -> 振幅和干涉
这条路不轻松,但它是可以走的。
这本书就是沿着这条路写的。
这本书不想做什么
先说清楚,这本书不是一本量子力学教材。
它不会从黑体辐射一路推到薛定谔方程。
也不会要求你先掌握复杂的波函数、哈密顿量、算符代数。
这些内容当然重要。
如果你以后要深入研究量子物理,它们迟早都要学。
但如果你的目标是先理解量子计算机到底怎么工作,尤其是理解量子线路、量子门、量子算法的基本逻辑,那么我们不必一开始就走最重的路。
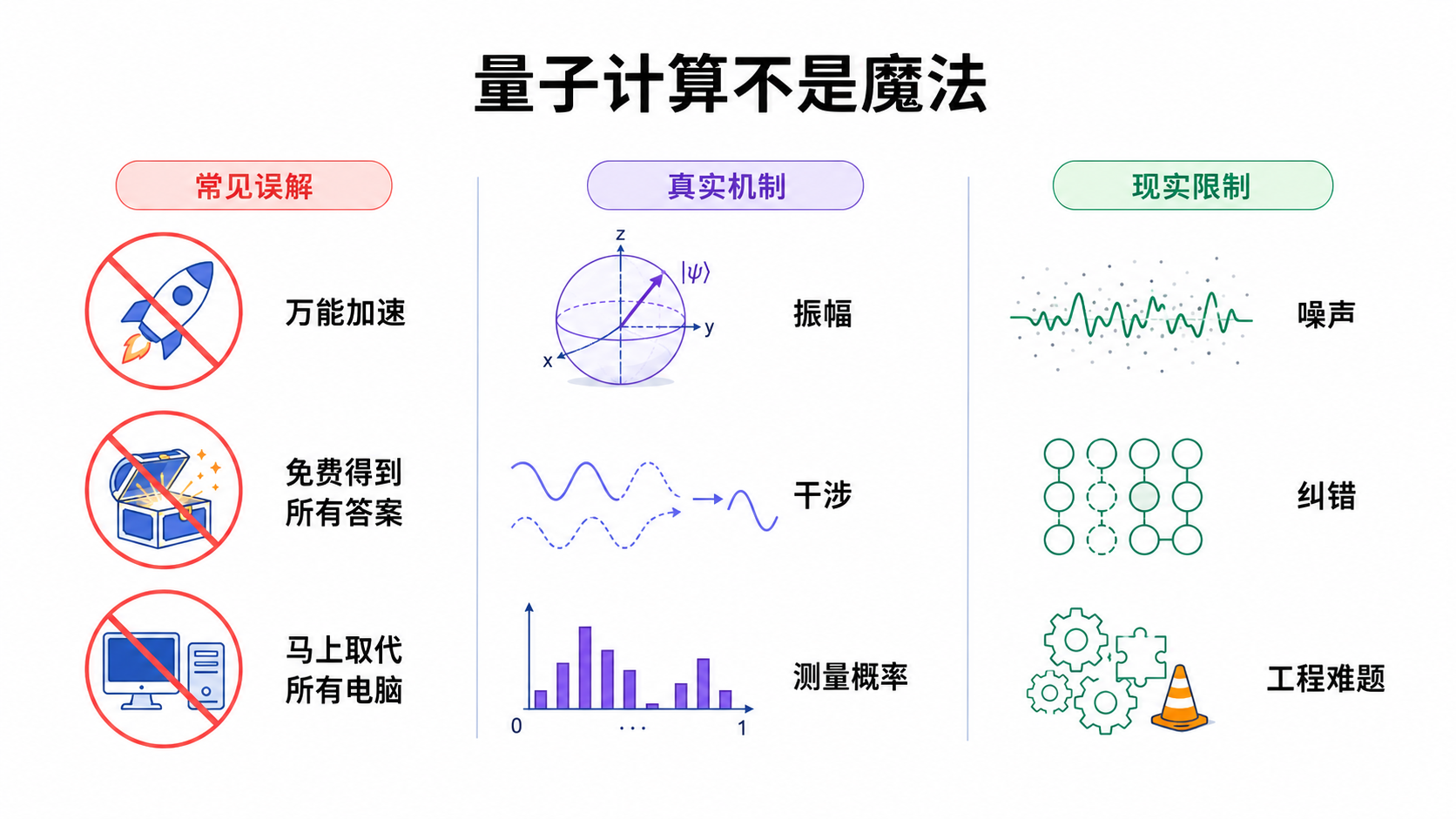
这本书也不是一本追热点的科普书。
我不会告诉你“量子计算马上改变一切”。
也不会把量子计算说成万能机器。
量子计算很强,但它不是魔法。
它有真实优势,也有真实限制。
它能加速某些问题,但不能让所有问题都自动变简单。
它有很漂亮的算法,也有很艰难的工程现实。
所以,本书的态度是:
不神化
不吓人
不故意炫技
尽量把事情讲清楚
这本书想做什么
这本书想做一件比较朴素的事:
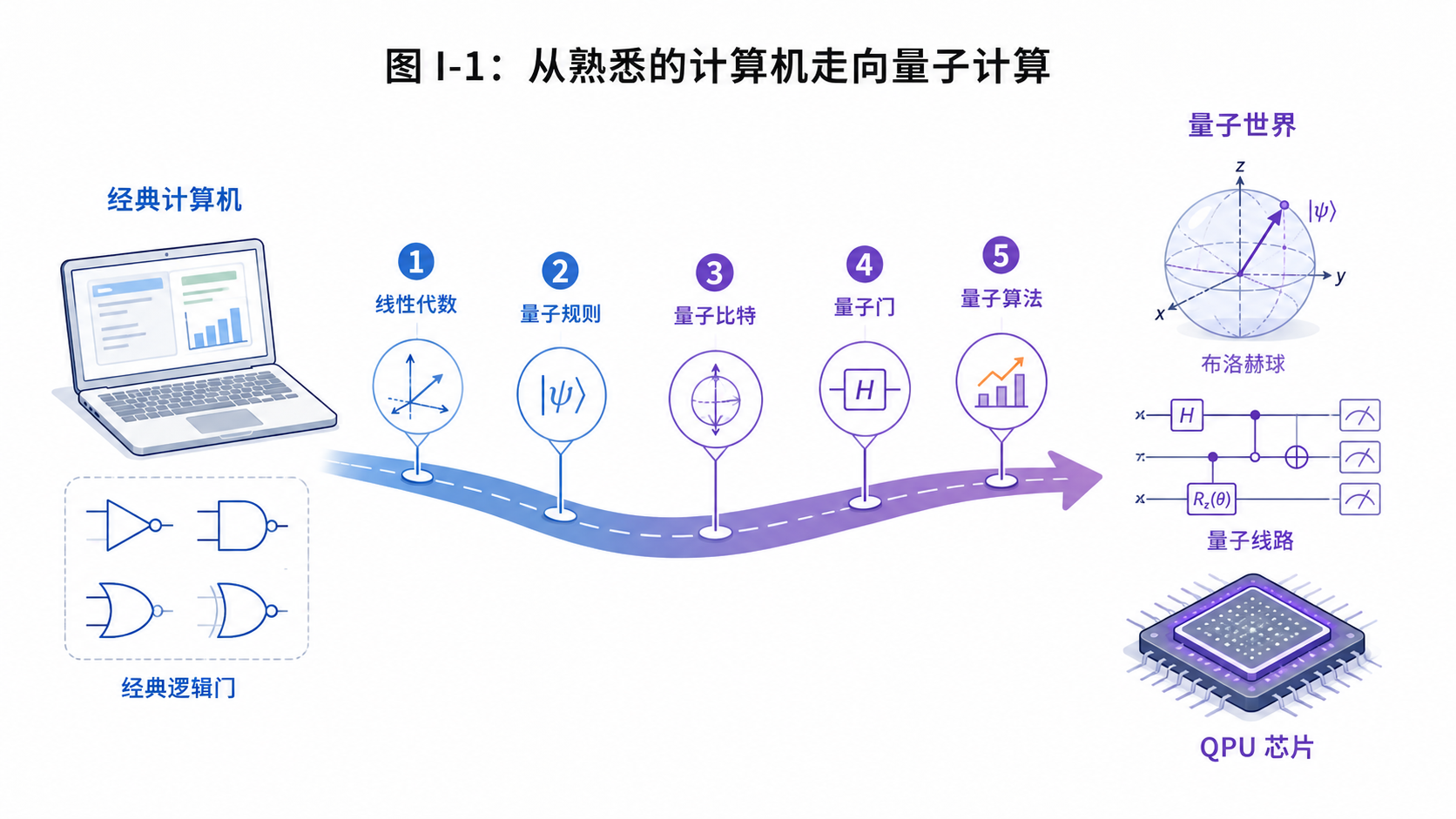
从你已经知道的计算机知识出发,带你走到量子计算。
如果你学过一点线性代数,知道向量、矩阵、内积这些词。
如果你学过一点计算机组成原理,知道比特、逻辑门、电路这些概念。
那你已经有了足够的起点。
本书会先补一章线性代数急救包。
只补后面真正会用到的东西。
然后,我们会沿着两条线前进。
第一条是历史线。
为什么会有量子力学?
为什么经典物理不够?
量子力学怎样从解释微观世界,走到操控微观世界?
量子计算又怎样从一个物理想法,变成一种新的计算模型?
第二条是技术线。
经典计算机怎样用电信号表示 0 和 1?
逻辑门怎样组合出电路?
量子比特和经典比特有什么不同?
量子门为什么必须是可逆的?
叠加、纠缠、干涉到底在计算里起什么作用?
这两条线会不断交叉。
历史线告诉我们:
这些想法为什么会出现
技术线告诉我们:
这些想法怎样变成计算
本书的一个核心路线
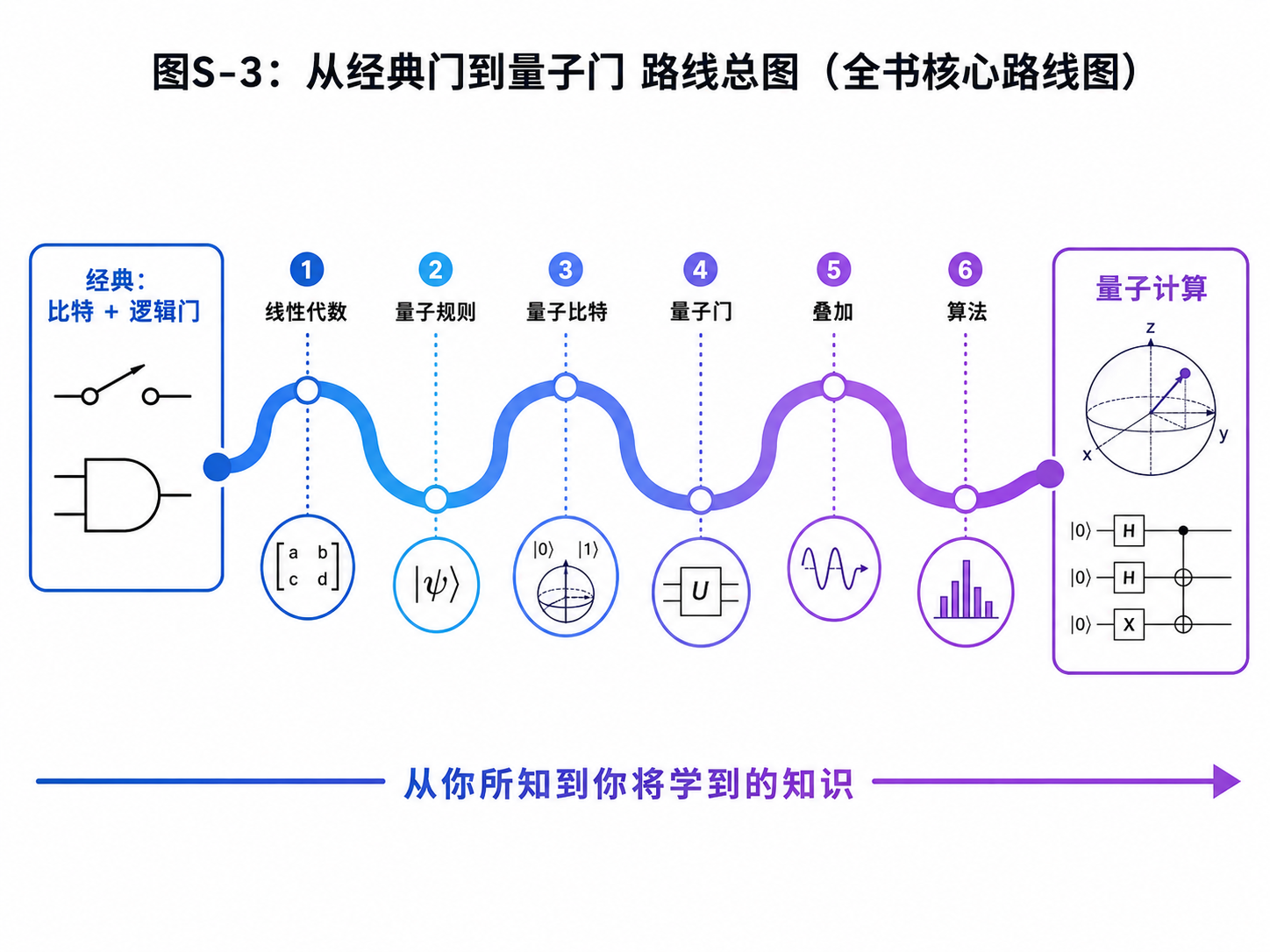
本书有一个最重要的路线:
从经典门到量子门
很多量子计算教材会从量子力学开始。
这当然是正统路线。
但对计算机背景的读者来说,另一个入口可能更自然:
先问经典计算机怎么工作。
经典计算机的基本图景是:
比特表示信息
逻辑门改变比特
电路组合逻辑门
算法被编译成一连串操作
量子计算机的基本图景则是:
量子比特表示状态
量子门改变量子态
量子线路组合量子门
算法安排振幅和干涉
测量给出最终经典结果
这两个图景很像。
但关键地方都变了。
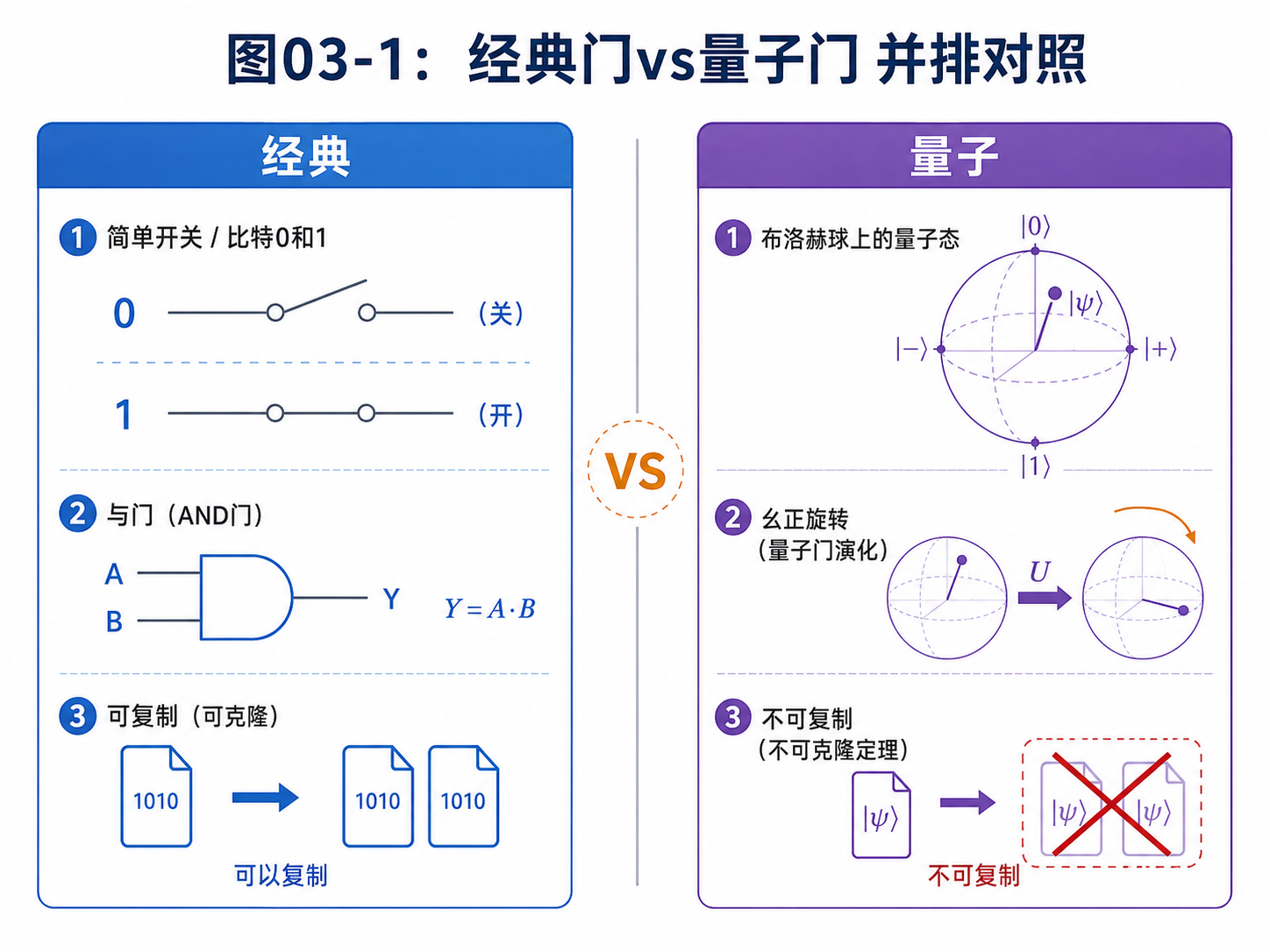
经典比特只能是 0 或 1。
量子比特可以处在叠加态。
经典门可以丢信息。
量子门必须保持可逆。
经典信息可以复制。
未知量子态不能随便复制。
经典程序可以中途打印变量。
量子程序不能随便测量中间态。
经典并行靠更多硬件。
量子并行靠状态空间、振幅和干涉。
这些差异,会一章一章展开。
你需要什么前置知识
这本书尽量降低门槛。
你最好知道一点线性代数:
向量
矩阵乘法
内积
复数
不用精通。
第零章会把本书真正需要的部分先补一遍。
你最好知道一点计算机基础:
比特
逻辑门
电路
算法
如果你学过计算机组成原理、数字逻辑、离散数学,那会更顺。
你不需要先学完量子力学。
你不需要先懂薛定谔方程。
你也不需要有物理专业背景。
当然,完全没有数学也不现实。
量子计算毕竟是一套关于向量和矩阵的计算方法。
但我们会尽量让每个数学符号都有直觉,而不是让公式自己站在那里吓人。
阅读时请记住的一件事
量子计算里最容易出问题的地方,不是公式本身。
而是直觉。
很多经典世界里的直觉,在量子世界里不能直接搬过去。
比如:
看一眼不会改变东西
复制一份总是可以的
并行就是多开几台机器
结果早就在那里,只是我们还没看
这些想法在经典计算里很自然。
但在量子计算里,它们往往会误导我们。
所以读这本书时,不妨保持一种心态:
先允许直觉被改造
再用新的直觉理解公式
量子计算不是反常识。
它只是反经典常识。
一旦规则换了,新的直觉也会慢慢长出来。
写给当年听讲座的自己
这本书某种意义上,是写给当年那个坐在讲座里似懂非懂的自己的。
那时我能感觉到量子计算很重要,也能感觉到它背后有一种很漂亮的结构。
但很多概念像雾一样:
叠加到底是不是同时算所有答案?
测量为什么会破坏状态?
量子门为什么要可逆?
纠缠到底对计算有什么用?
量子计算机为什么这么难造?
这些问题如果只靠零散文章,很容易越看越乱。
所以我想把它们按一条线串起来。
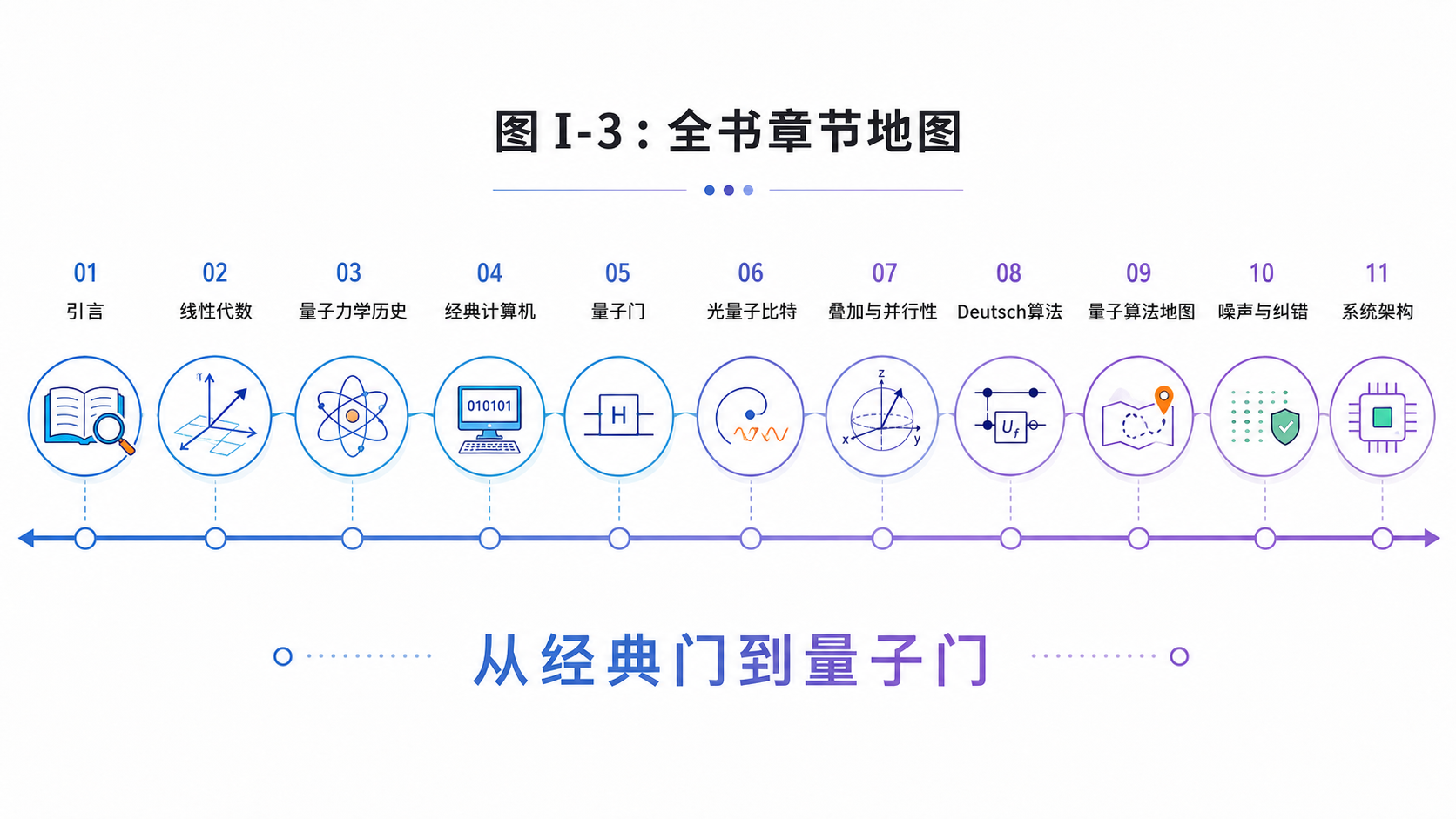
从线性代数开始。
到量子力学的基本规则。
到经典计算机。
到量子门。
到光量子比特。
到量子并行和 Deutsch 算法。
再到更大的算法地图、噪声纠错和未来机器架构。
读完以后,你不一定会变成量子计算专家。
这也不是本书的目标。
但你应该能做到几件事:
听到量子比特时,知道它不是神秘小球
看到量子门时,知道它是向量空间里的可逆变换
听到量子并行时,知道它不是免费读出所有答案
看到 Shor 和 Grover 时,知道它们利用的是结构和干涉
听到量子纠错时,知道难点不是简单复制三份
看到量子计算新闻时,能分辨希望、现实和夸张
如果这本书能帮你做到这些,它就完成了自己的任务。
那么,我们从最小的一块工具开始。
先补一点线性代数。
不是为了考试,而是为了看懂量子计算真正使用的语言。
第零章 线性代数急救包:只补真正会用到的工具
如果你打开一本量子计算教材,最先撞上来的通常不是量子计算机,而是一串符号:向量、矩阵、内积、张量积、酉矩阵、投影、测量。
这些词看起来像门槛。很多读者就是在这里被劝退的。
但对这本书来说,我们不需要先把线性代数完整重学一遍。我们只需要准备一套够用的小工具。你可以把本章当成出门前整理背包:不是把整个家搬走,而是只带后面路上一定会用到的东西。
这套工具包括六件事:
- 量子态是复向量
- 合法量子态必须归一化
- 量子门是保持长度的矩阵
- 门作用于态,就是矩阵乘向量
- 多个量子比特放在一起,要用张量积
- 测量概率来自振幅的模平方
先别急着记住每个词。我们一件一件来。
0.1 先把“状态”想成一个箭头
经典计算机里的一个比特很简单:不是0,就是1。
你可以把它想成一个开关。开,就是1;关,就是0。它没有中间状态,也不会同时又开又关。经典计算机之所以可靠,很大程度上就来自这种清楚的二分。
量子比特不一样。
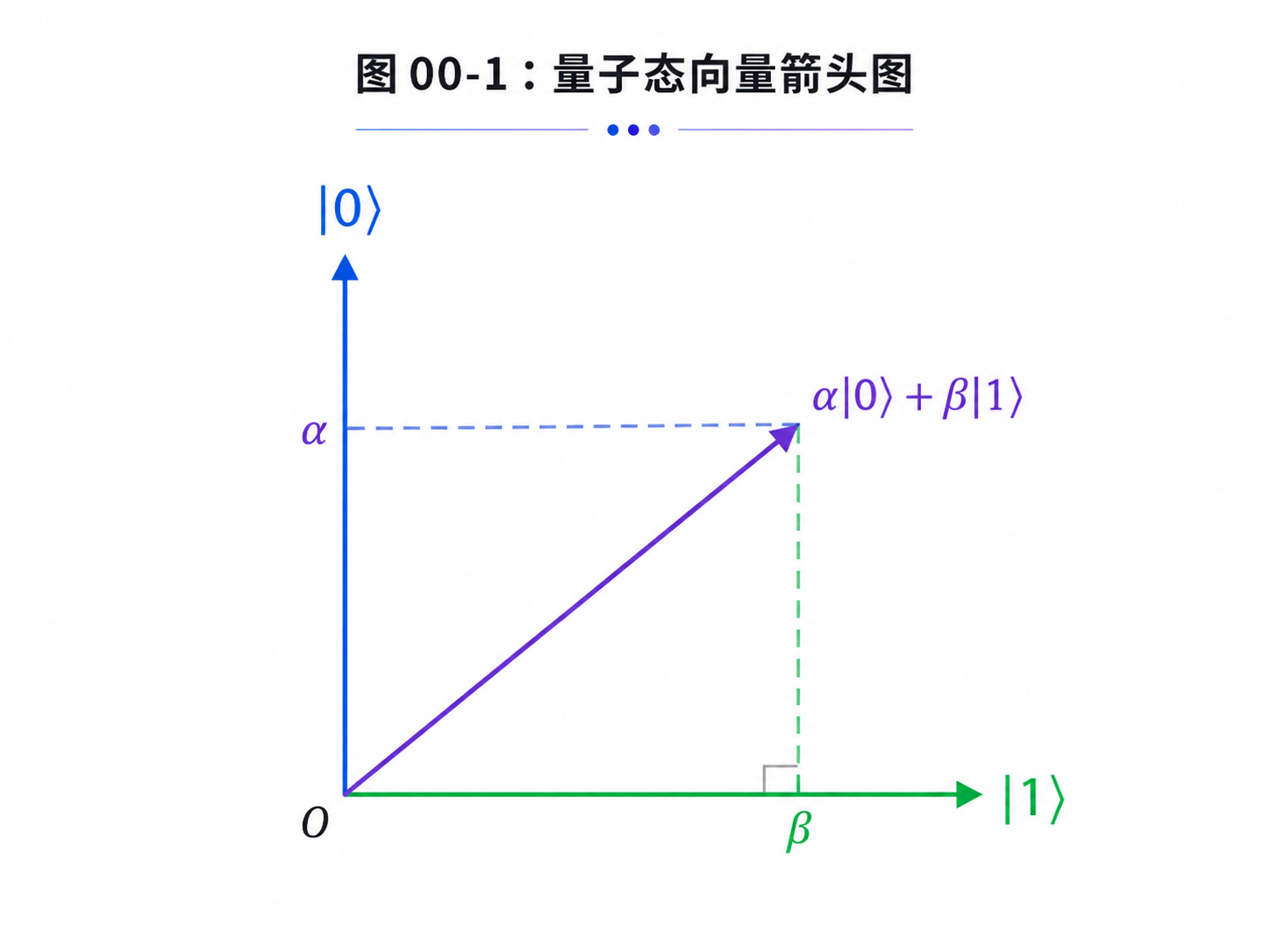
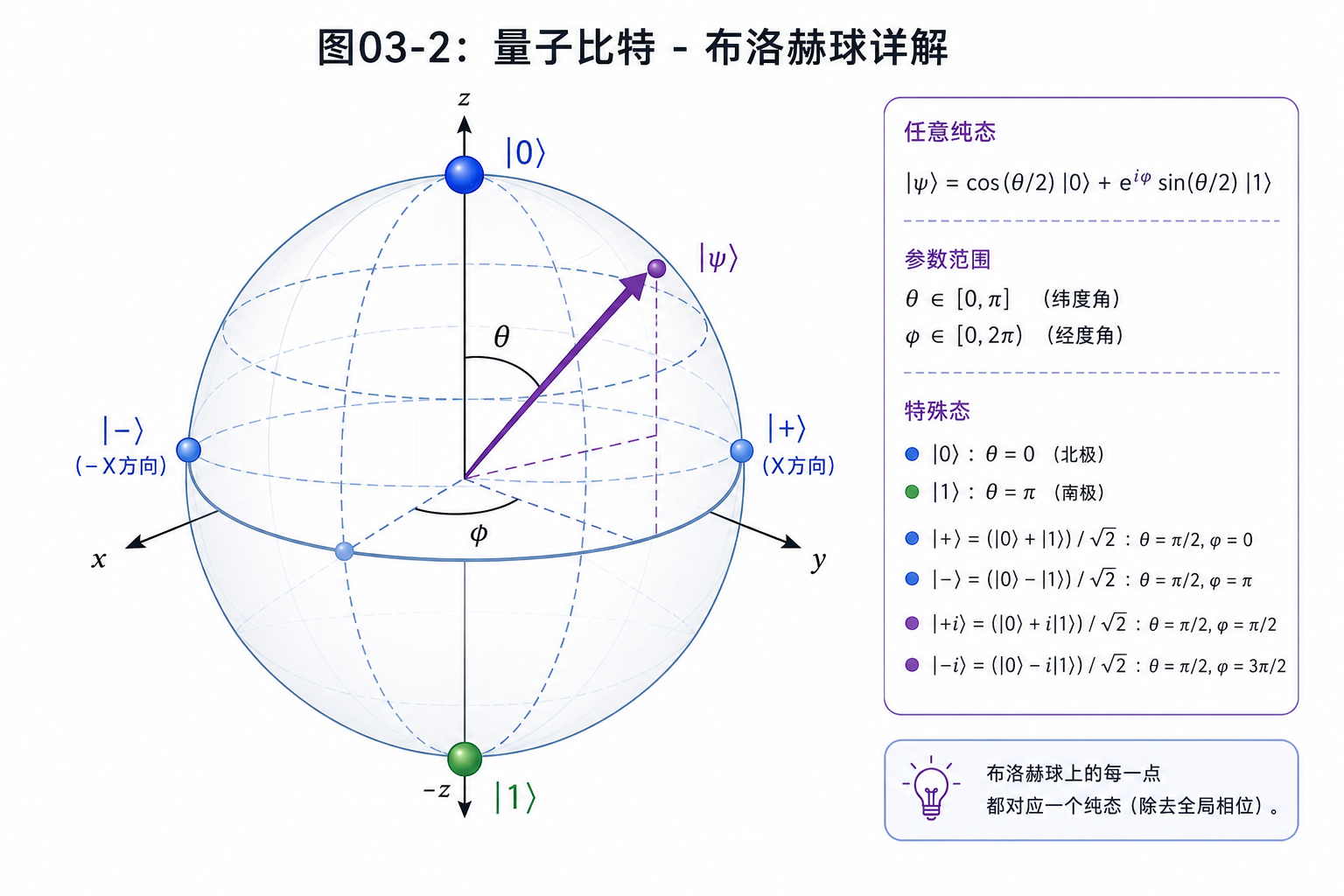
量子比特也有两个基本状态,我们仍然把它们记作 |0⟩ 和 |1⟩。但它不一定只站在其中一个位置上。它可以是两者的叠加:
|ψ⟩ = α|0⟩ + β|1⟩
这行式子先不用害怕。它只是在说:一个量子比特的状态,可以由两部分组成。一部分沿着 |0⟩ 方向,一部分沿着 |1⟩ 方向。
如果用图像来想,你可以把量子态想成一个箭头。|0⟩ 是一个基本方向,|1⟩ 是另一个基本方向。一个普通量子态,就是这两个方向按不同比例合成出来的新箭头。
这里的 α 和 β 叫振幅。它们决定这个箭头更偏向 |0⟩,还是更偏向 |1⟩。
如果 α = 1, β = 0,这个状态就是 |0⟩。
如果 α = 0, β = 1,这个状态就是 |1⟩。
如果 α 和 β 都不是0,它就处在叠加态。
这就是量子比特和经典比特的第一个差别:经典比特像一个只会停在两个位置的开关,量子比特更像一个可以指向很多方向的箭头。
0.2 为什么要用复数
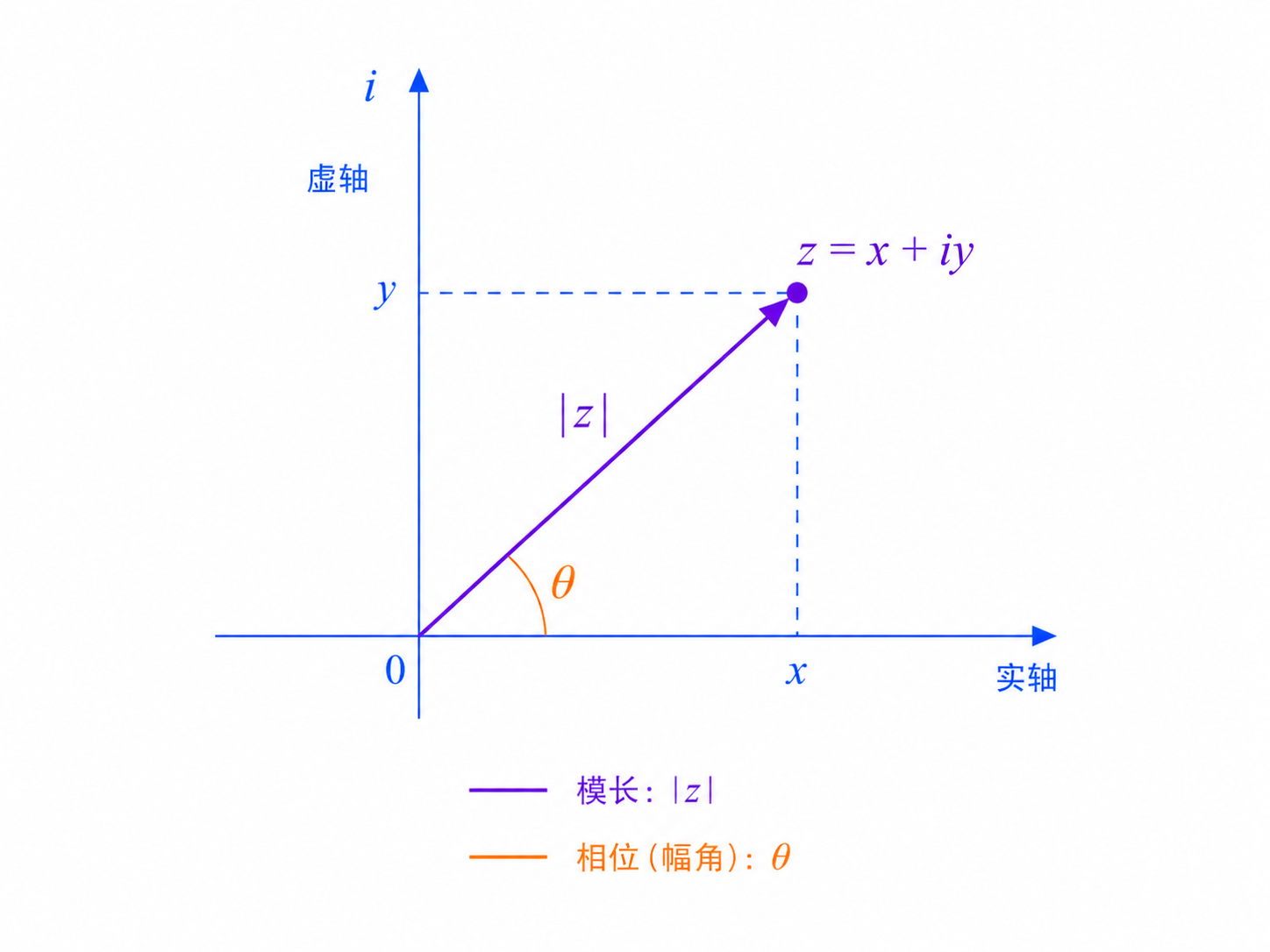
上面的 α 和 β 不只是普通实数,它们通常是复数。
一听到复数,很多人会下意识紧张。其实你可以先抓住一个很简单的直觉:复数不仅有大小,还有角度。
这个角度,就是我们后面反复遇到的“相位”。
如果只讲概率,似乎实数就够了。比如一个量子比特测到0的概率是50%,测到1的概率也是50%。那为什么还要引入复数?
因为量子计算真正厉害的地方,不只是概率,而是干涉。
两个振幅相遇时,可能互相加强,也可能互相抵消。这就像两列波相遇:波峰遇到波峰,会更高;波峰遇到波谷,可能相互抵消。复数的相位,就是用来记录这种“波峰波谷怎么对齐”的信息。
所以,复数不是为了让公式显得高级。它的作用很具体:记录相位,让干涉能够发生。
在后面的算法里,尤其是 Deutsch 算法、Grover 算法、Shor 算法里,我们会反复看到同一件事:答案不是直接被写在某个位置上,而是藏在相位里,再通过干涉被读出来。
这就是复数必须出现的原因。
0.3 概率来自振幅的模平方
量子态里有振幅,但测量时得到的是概率。
这两者之间的关系很简单:
概率 = 振幅的模平方
如果一个量子比特是:
|ψ⟩ = α|0⟩ + β|1⟩
那么:
- 测到
0的概率是|α|² - 测到
1的概率是|β|²
这里的竖线不是绝对值那么简单。因为 α 和 β 可能是复数,所以 |α| 表示复数的模,也就是它的大小。再平方,就得到概率。
概率有一个基本要求:所有可能结果的概率加起来必须等于1。
所以一个合法的量子态必须满足:
|α|² + |β|² = 1
这叫归一化。
“归一化”这个词听起来很数学,其实意思很朴素:所有可能性加起来,必须是100%。
如果你写出一个状态:
2|0⟩ + 3|1⟩
它还不是一个合法量子态,因为概率会加爆。你需要把它缩放一下,让总概率回到1。这个缩放过程就叫归一化。
后面我们遇到量子态时,会经常看到 1/√2 这样的系数。它不是凭空来的,而是为了让概率加起来等于1。
比如:
(|0⟩ + |1⟩) / √2
测到0的概率是 1/2,测到1的概率也是 1/2,加起来刚好是1。
0.4 内积:两个状态有多像
接下来需要一个工具:内积。
你可以先把内积理解成一个问题:
两个状态有多像?
如果两个箭头方向完全一样,内积就大。
如果两个箭头互相垂直,内积就是0。
在量子计算里,内积最常见的用途是计算测量概率。比如你手里有一个状态 |ψ⟩,你想知道它被测成某个状态 |φ⟩ 的概率。规则是:
概率 = |⟨φ|ψ⟩|²
这里的 ⟨φ|ψ⟩ 就是 |φ⟩ 和 |ψ⟩ 的内积。
这个符号来自狄拉克记号。右边这种 |ψ⟩ 叫 ket,左边这种 ⟨φ| 叫 bra。名字有点古怪,但你不需要被它绊住。
你可以暂时这样理解:
|ψ⟩是一个列向量⟨φ|是一个行向量⟨φ|ψ⟩就是行向量乘列向量
它最后得到一个数。这个数的模平方,就是概率。
为什么要这么麻烦?因为量子测量不是“直接读取一个隐藏的值”。测量更像是问:
这个状态在我关心的方向上,有多少分量?
内积就是回答这个问题的工具。
0.5 矩阵:让箭头转起来
有了状态,就要有操作。
经典计算里的操作是逻辑门。比如 NOT 门把0变成1,把1变成0。AND门看两个输入,按真值表给出输出。
量子计算里的操作是量子门。
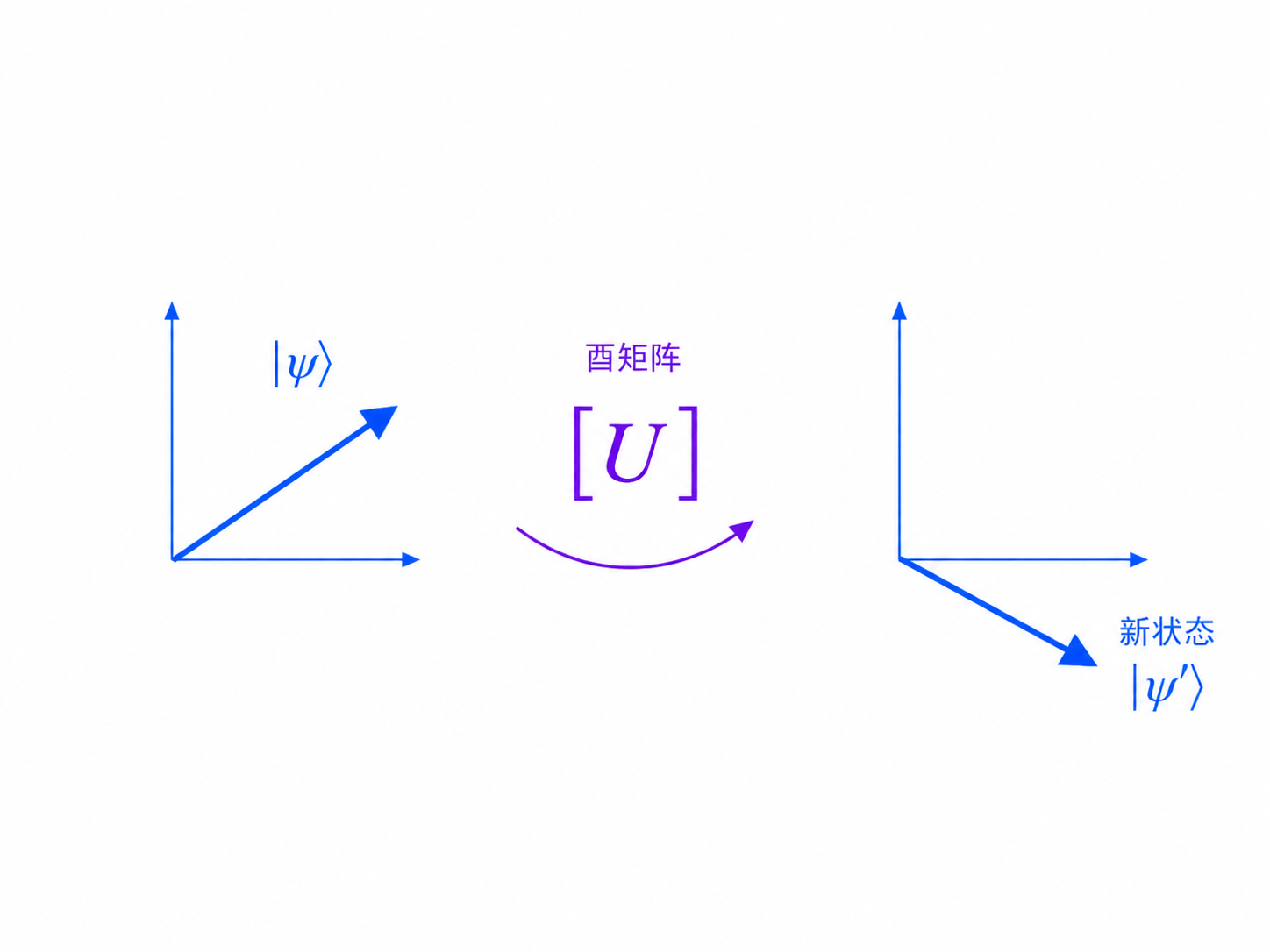
量子门首先可以看成矩阵。
一个量子态是向量,一个量子门是矩阵。量子门作用在量子态上,就是矩阵乘向量:
新状态 = 量子门 × 旧状态
这句话非常重要。后面所有量子线路,本质上都在重复这件事。
如果一个量子比特的状态是一个箭头,那么量子门就是把这个箭头转到另一个方向的操作。
比如 X门。它的作用和经典 NOT 门很像:
X|0⟩ = |1⟩
X|1⟩ = |0⟩
也就是说,它把 |0⟩ 和 |1⟩ 对调。
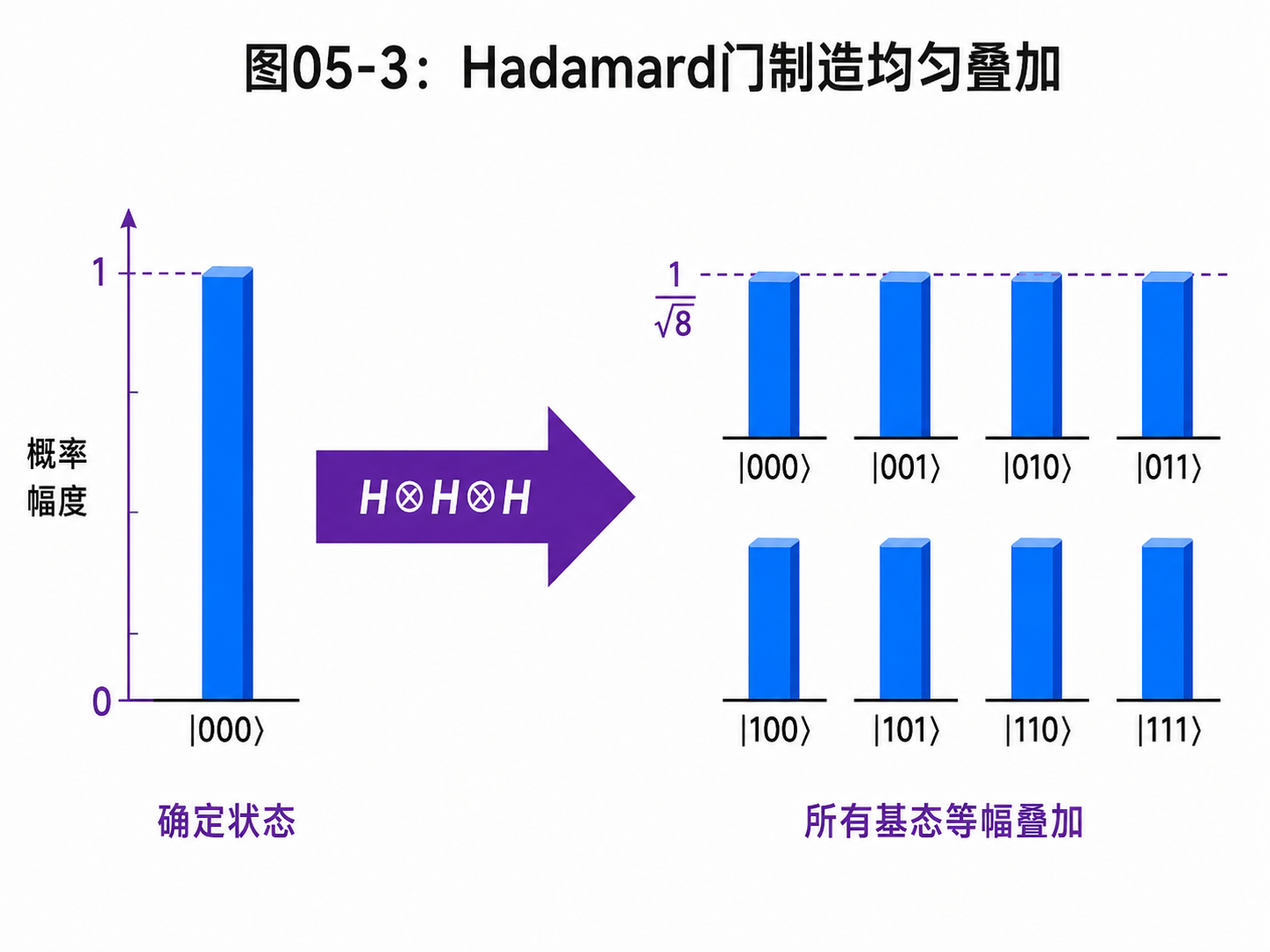
再比如 H门,也叫 Hadamard 门。它很重要,因为它可以制造叠加:
H|0⟩ = (|0⟩ + |1⟩) / √2
原来明确的 |0⟩,经过H门以后,变成了 |0⟩ 和 |1⟩ 的平均叠加。
这就是量子算法里最常见的一步:先用H门把确定输入展开成叠加,再让后面的门同时作用在这些分量上。
0.6 量子门为什么必须“保持长度”
不是所有矩阵都能当量子门。
合法的量子门必须有一个重要性质:操作前后,状态的总长度不变。
为什么?
因为状态长度对应总概率。总概率必须一直是1。如果一个矩阵把向量拉长了,概率就会超过1;如果把向量压短了,概率就会少于1。这都不合理。
所以量子门必须保持长度。这样的矩阵叫酉矩阵。
你不需要一开始就熟练操作酉矩阵,只要先记住它的直觉:
量子门像旋转,不像拉伸。
它可以改变状态的方向,可以改变不同分量之间的相位,但不能随便增减总概率。
这也带来另一个结果:量子门原则上是可逆的。
如果一个操作只是旋转,那么你总可以反方向转回来。经典AND门不行,因为它把多种输入压成同一个输出,丢掉了来路信息。量子门不能这么做。
这就是为什么很多经典门不能直接搬进量子计算里。量子计算不是在经典门上加一个“量子外壳”,而是从一开始就换了操作规则。
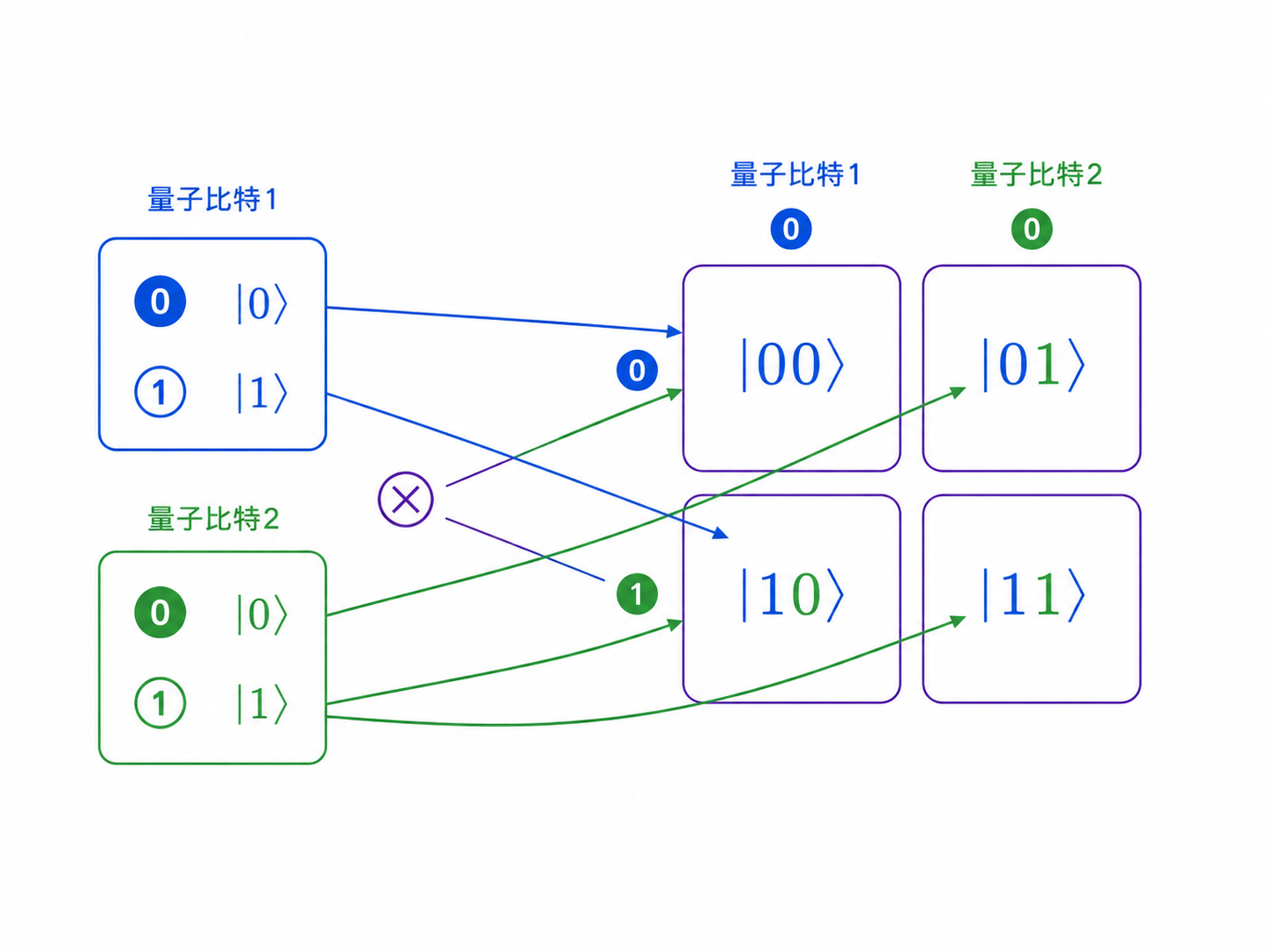
0.7 张量积:多个量子比特怎么放在一起
一个量子比特有两个基本方向:|0⟩ 和 |1⟩。
两个量子比特呢?
它们的基本状态有四个:
|00⟩, |01⟩, |10⟩, |11⟩
三个量子比特有八个基本状态。
n个量子比特有 2ⁿ 个基本状态。
这就是量子计算里经常出现指数增长的地方。不是因为我们真的造出了 2ⁿ 台机器,而是因为n个量子比特合在一起以后,状态需要 2ⁿ 个振幅来描述。
这种“合在一起”的数学规则叫张量积。
张量积这个词很容易让人紧张,但它在这里先只有一个作用:告诉我们多个系统怎么组成一个大系统。
如果第一个量子比特是:
a|0⟩ + b|1⟩
第二个量子比特是:
c|0⟩ + d|1⟩
它们合起来以后,会得到四个分量:
ac|00⟩ + ad|01⟩ + bc|10⟩ + bd|11⟩
这就像普通乘法展开括号,只不过每一项都带着一个量子状态标签。
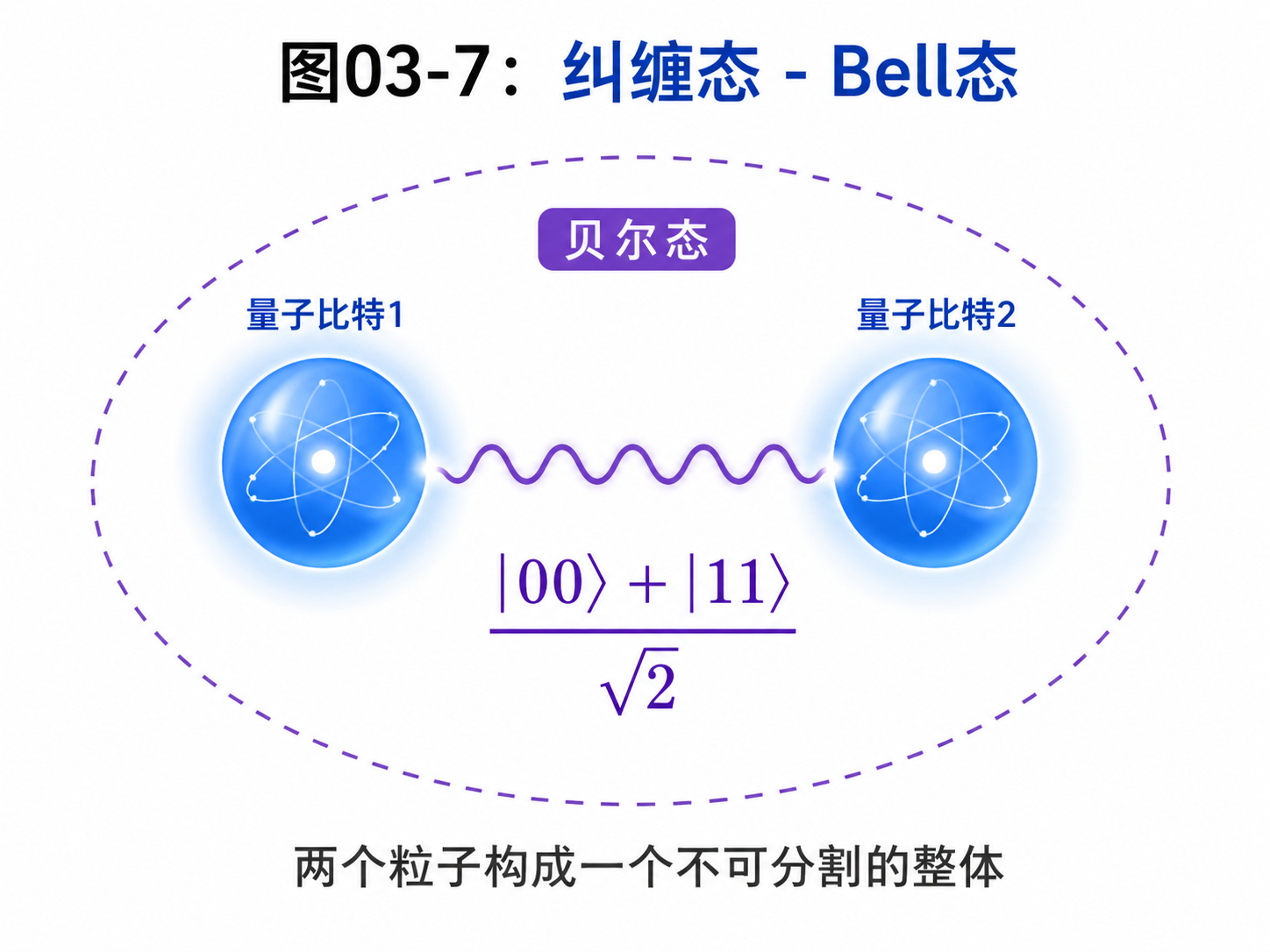
张量积也是纠缠出现的地方。
有些两量子比特状态,可以拆成“第一个量子比特的状态 × 第二个量子比特的状态”。这种状态叫乘积态。
但有些状态拆不开。比如:
(|00⟩ + |11⟩) / √2
你不能说第一个量子比特自己是什么状态,第二个量子比特自己是什么状态。它们必须作为一个整体来描述。
这就是纠缠。
这一点后面会非常重要。量子计算的能力,不只来自叠加,也来自多个量子比特之间这种不能拆开的整体关系。
0.8 测量:把连续的状态压成一个结果
量子态可以有很多振幅,可以有相位,可以处在叠加里。
但测量的时候,你拿到的结果很朴素:0或1。
这就是量子测量最反直觉的地方。
测量不是把量子态里所有信息都读出来。相反,测量会把一个丰富的量子态压成一个经典结果。
如果一个量子比特是:
(|0⟩ + |1⟩) / √2
你去测量它,不会同时看到0和1。你只会看到其中一个:
- 50%的概率看到0
- 50%的概率看到1
测完以后,原来的叠加态也不在了。如果你测到0,它就变成 |0⟩;如果你测到1,它就变成 |1⟩。
这叫坍缩。
“坍缩”听起来很玄,其实你可以先把它理解成:测量会强行给出一个经典答案,同时丢掉原来状态里很多细节。
这就是为什么量子计算不能靠“把所有可能答案都算出来,然后全部读出来”取胜。
你读不出来。
量子算法真正要做的是另一件事:在测量前,通过一连串量子门,让正确答案对应的振幅变大,让错误答案对应的振幅变小。这样最后一测,正确答案出现的概率就高。
这句话是后面理解量子算法的关键。
0.9 本章小结:以后迷路就回到这六句话
本章没有完整讲完线性代数,也不需要讲完。我们只是为后面的量子计算准备了六个工具。
第一,量子态是向量。
它不是一个隐藏的经典值,而是一个可以有多个分量的状态。
第二,振幅可以是复数。
复数记录相位,相位让干涉成为可能。
第三,概率来自振幅的模平方。
振幅不是概率,但振幅的模平方给出概率。
第四,量子门是矩阵。
门作用于态,就是矩阵乘向量。
第五,量子门必须保持总概率。
所以它像旋转,不像随意拉伸。数学上,这类矩阵叫酉矩阵。
第六,多个量子比特合在一起,要用张量积。
张量积带来指数级状态空间,也带来纠缠。
有了这六句话,我们就可以进入第一章:从量子力学的历史出发,看这些数学规则为什么会出现,又怎样一步步走到量子计算机。
第一章 从量子力学的诞生到量子计算:一百多年的逻辑链条
上一章我们准备了几个工具:向量、矩阵、内积、张量积、测量概率。
这些工具看起来像数学。可是它们不是凭空出现在量子计算里的。它们背后有一段很长的历史:物理学家先是在实验里发现经典理论解释不了的现象,然后一点点把这些现象压缩成新的数学语言。
本章要讲的不是完整量子力学史。那会是一整本书。
我们只抓住一条主线:
为什么量子计算可以先从向量、矩阵和测量规则讲起?
换句话说,我们要看清楚:量子计算不是一门突然冒出来的技术,它是量子力学发展到信息处理阶段以后,自然长出来的一条路。
1.1 “量子”最早是什么意思
很多人听到“量子”,第一反应是玄。
其实这个词一开始并不玄。它的意思很朴素:一份一份的。
在经典物理的直觉里,很多东西应该是连续变化的。比如水从杯子里倒出来,可以多一点,也可以少一点;温度可以一点点升高;能量似乎也应该可以连续取任意值。
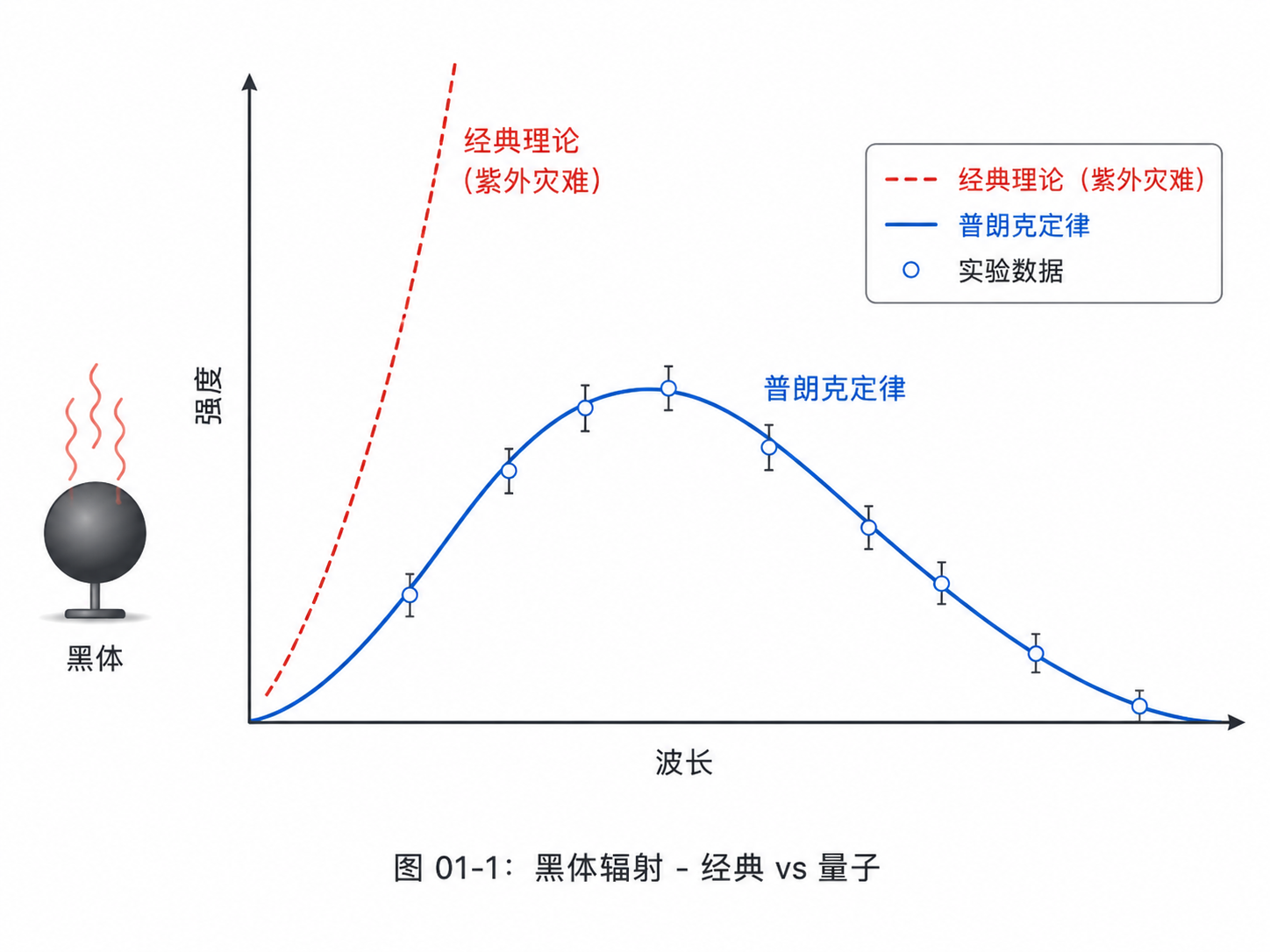
但到了19世纪末,物理学家遇到了一个麻烦:黑体辐射。
你不需要知道黑体辐射的全部细节,只需要知道一点:按照当时的经典理论去算,结果会和实验对不上,而且错得很离谱。
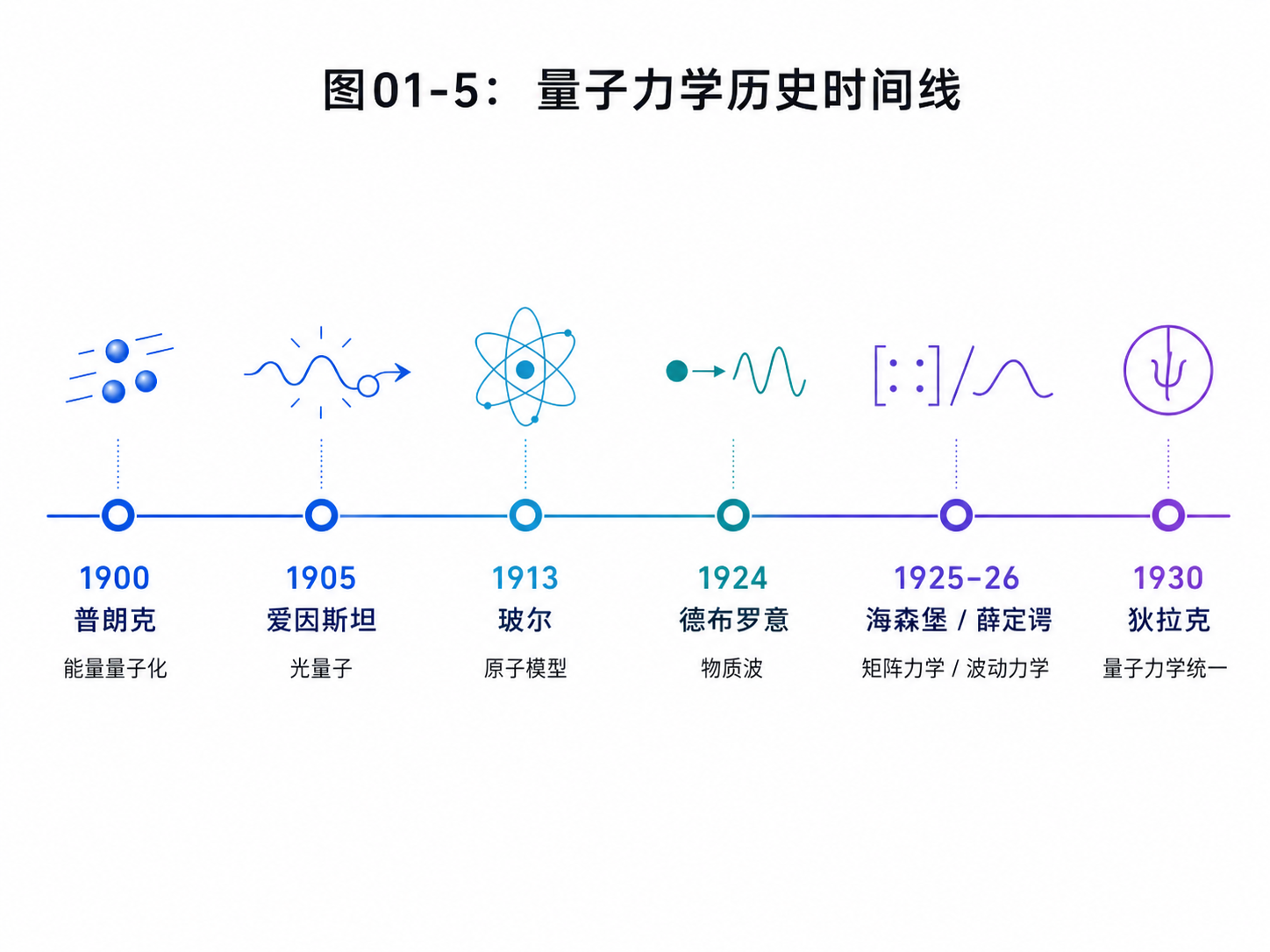
1900年,普朗克提出一个大胆的想法:能量也许不是连续交换的,而是一份一份交换的。
这“一份一份”,就是量子。
这个想法一开始更像一个计算技巧。普朗克并不是一上来就宣布世界观彻底改变了。他只是发现,如果假设能量按小份交换,公式就能和实验对上。
但这个“小技巧”后来变成了大革命。
因为它动摇了一个很深的经典直觉:自然界不一定处处连续。
从这一步开始,物理学家逐渐意识到,在微观世界里,很多东西不能再用日常经验去想。
1.2 光也是一份一份的
普朗克说能量是一份一份交换的。几年后,爱因斯坦往前推了一步:光本身也可以看成一份一份的。
这就是光量子的想法。
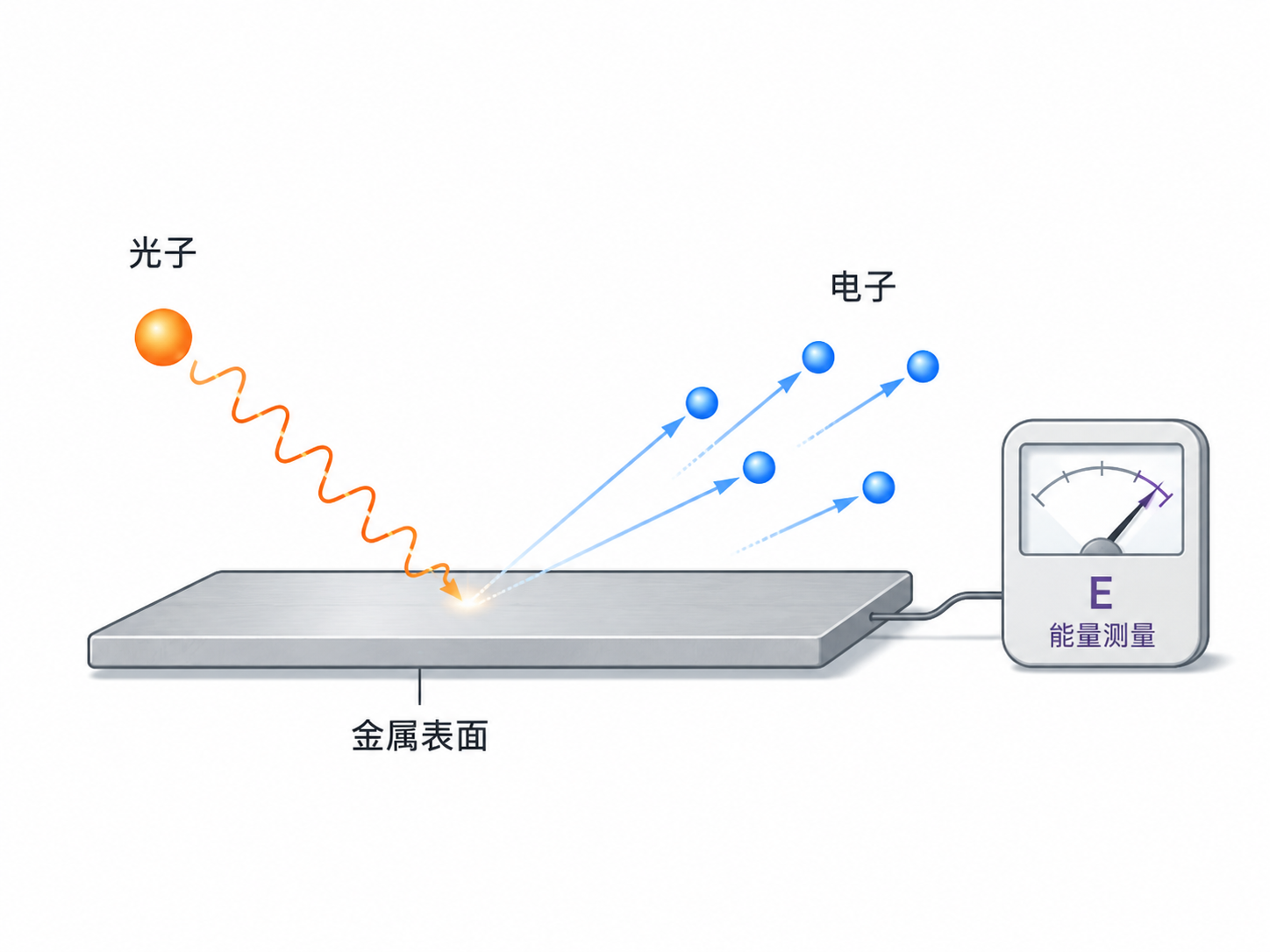
为什么要这么想?
因为有一个现象叫光电效应。简单说,就是光照到金属上,可以把电子打出来。
如果按经典波动图像来想,光越强,应该越容易把电子打出来。可实验告诉我们,关键不只是光强,而是光的频率。频率不够,就算光再强,也打不出电子;频率够了,哪怕光不强,也能打出电子。
这很像什么?
像一个个小球在撞电子。
每个小球携带一份能量。频率越高,每份能量越大。只有单份能量足够大,才能把电子打出来。
这里的“小球”就是光子。
当然,光不是普通小球。它有波动性,也有粒子性。但在这个阶段,我们只需要记住一点:光不再只是连续的波,也可以表现得像一份一份的能量包。
这个想法对后面的量子计算很重要。
因为在第四章,我们会用光子的偏振来讲量子比特。那时候你会看到,一个光子就可以承载一个量子比特。
1.3 原子也不是小太阳系
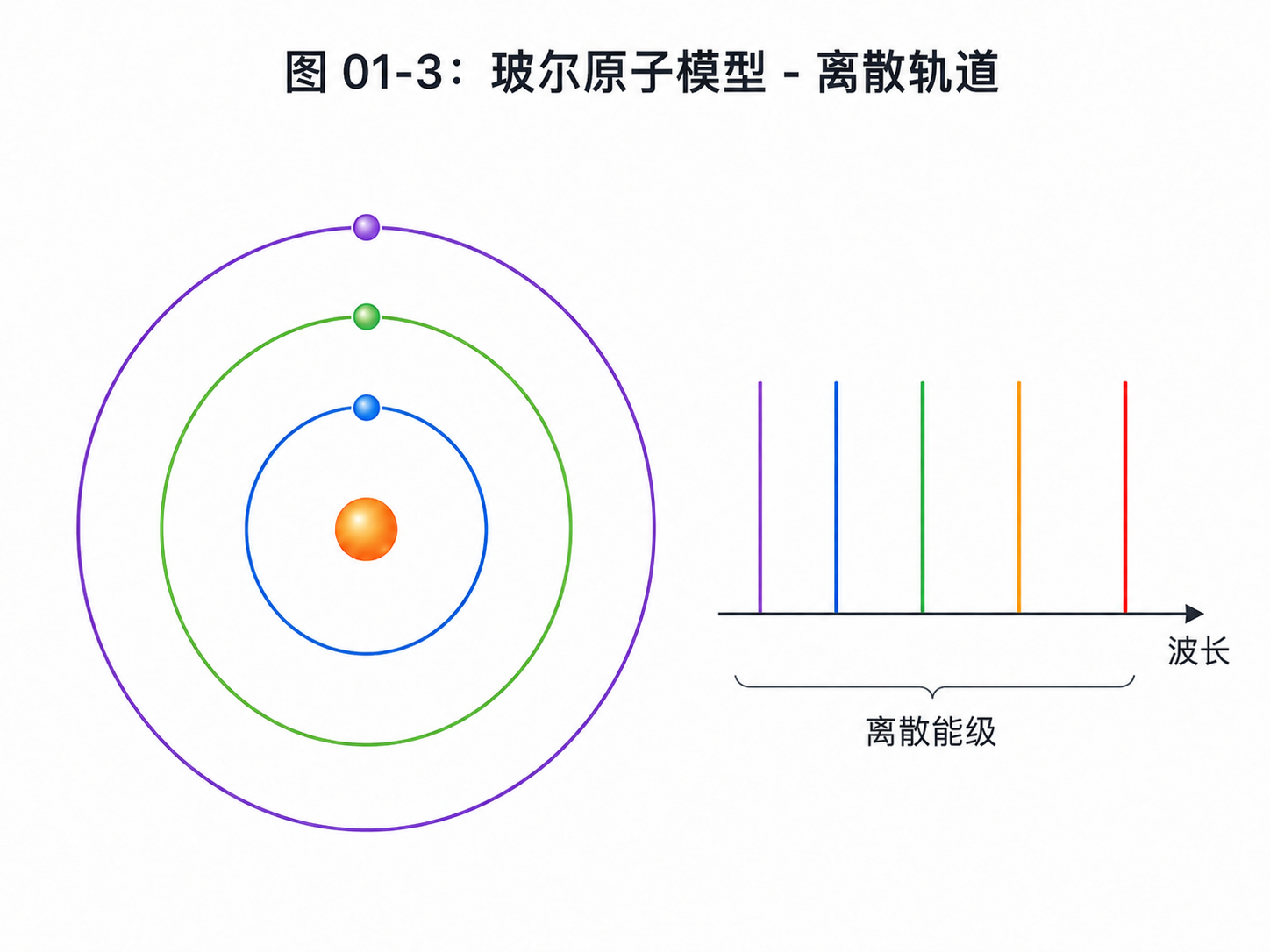
接下来登场的是玻尔。
在经典图像里,很多人会把原子想成一个小太阳系:电子绕着原子核转,就像行星绕着太阳转。
这个图像很直观,但它有问题。
按照经典电磁理论,绕圈运动的电子应该不断辐射能量。能量一丢,轨道就会越转越小,最后电子应该掉进原子核里。
可真实原子很稳定。
玻尔提出一个新想法:电子不是想在哪条轨道就在哪条轨道。它只能待在某些允许的轨道上。换句话说,原子的能级是离散的。
这又是一次“连续变成离散”。
电子从一个能级跳到另一个能级,会吸收或发出一份特定能量的光。
这解释了为什么原子发出的光不是连续的一整片颜色,而是一条一条特定谱线。
从量子计算的角度看,玻尔模型本身不是终点。它还不够完整,也不够现代。但它留下了一个非常重要的直觉:
微观系统的状态不是随便取的,它有一套自己的规则。
后面我们把量子比特写成 |0⟩ 和 |1⟩,其实也是在选两个可以区分的基本状态。它们不一定是电子轨道,也可以是光子的水平偏振和垂直偏振,或者超导电路里的两个能级。
物理载体不同,但思想相通:先找到两个可控制、可区分的状态,再用它们来编码信息。
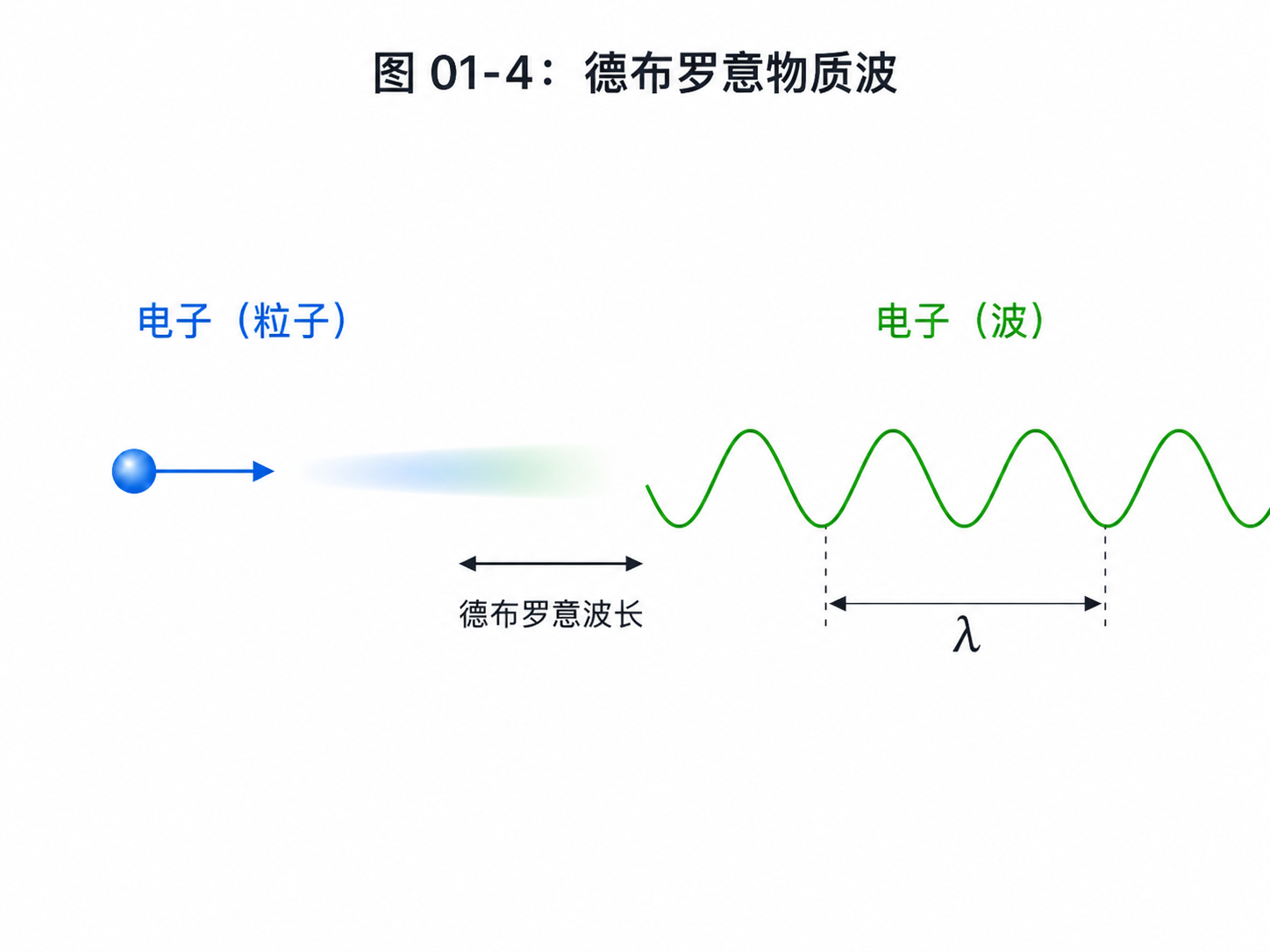
1.4 物质也有波动性
到这里,光已经既像波又像粒子了。
那反过来呢?
如果光这种“波”可以表现得像粒子,那么电子这种“粒子”会不会也表现得像波?
德布罗意提出:会。
这听起来很大胆,但后来实验支持了它。电子可以发生衍射和干涉,这正是波的行为。
这一步非常关键。
因为它告诉我们:微观世界不是简单的“粒子世界”,也不是简单的“波世界”。它有一套更底层的描述方式。我们日常说的粒子和波,只是它在不同实验条件下表现出来的两种面孔。
那更底层的描述方式是什么?
后来答案逐渐变清楚:状态。
不是先问“它到底是粒子还是波”,而是先问“这个系统的状态是什么”。状态怎么变化?测量时会得到什么结果?
这就是第零章那些工具开始派上用场的地方。
量子态用向量表示。
状态变化用矩阵表示。
测量结果按概率出现。
这不是数学家硬塞进去的形式,而是物理学家在实验压力下逐渐找到的语言。
1.5 两条路:矩阵力学和波动力学
1920年代,量子理论进入了真正成型的阶段。
当时有两条看起来很不一样的路。
一条是海森堡的矩阵力学。
海森堡不试图画出电子到底沿着哪条轨道走。他关注的是可观测量:能级是多少,跃迁频率是多少,实验能看到什么。为了描述这些量,他用到了一种当时看起来很奇怪的数学对象:矩阵。
另一条是薛定谔的波动力学。
薛定谔写出了著名的波动方程,用波函数来描述微观系统。这个图像更接近日常直觉,因为大家多少能想象“波”是什么。
一开始,这两条路看起来完全不同。
一个是矩阵。
一个是波函数。
但后来人们发现,它们本质上是同一套理论的不同写法。
这件事很重要。它说明量子力学真正的核心,不是某一种单独图像,而是一套抽象结构。你可以用矩阵讲,也可以用波函数讲,还可以用更统一的向量空间语言讲。
而量子计算最常用的,就是向量和矩阵这条路。
这也是为什么本书不从薛定谔方程开始,而是从向量和矩阵开始。
不是因为薛定谔方程不重要,而是因为我们要理解的是量子计算。对量子线路来说,最直接的语言就是:
状态是向量,门是矩阵,线路是矩阵连乘。
1.6 狄拉克:把符号统一起来
如果说海森堡和薛定谔给出了两条路,那么狄拉克做的事情,就是把这些路统一成一种更简洁的语言。
我们在第零章里已经见过 |ψ⟩ 这样的符号。这种写法就来自狄拉克。
它的好处是非常适合量子计算。
比如一个量子比特可以写成:
|ψ⟩ = α|0⟩ + β|1⟩
两个量子比特可以写成:
|00⟩, |01⟩, |10⟩, |11⟩
测量概率可以写成:
|⟨φ|ψ⟩|²
这些符号一开始有点陌生,但它们很省力。等你习惯以后,会发现它们比长篇文字更清楚。
这也是本书会一直使用狄拉克记号的原因。
不过我们会遵守一个原则:每次出现重要符号,都尽量配上人话解释。符号不是为了显示专业,而是为了让复杂关系写得更清楚。
1.7 四条规则:量子计算真正需要的入口
到1930年前后,量子力学已经有了比较成熟的数学框架。
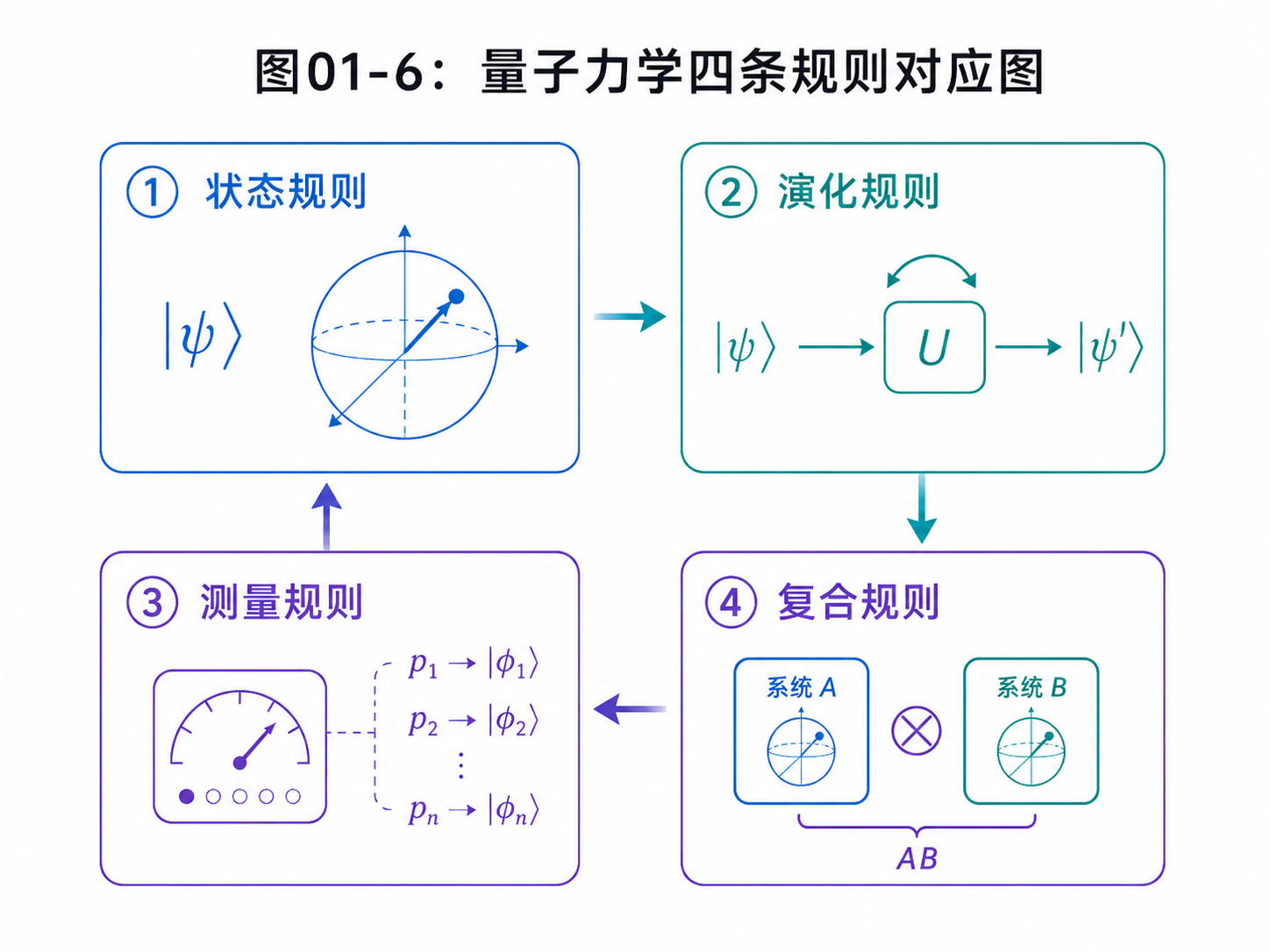
对一本量子计算入门书来说,我们不需要把全部量子力学都搬进来。我们只需要抓住四条和计算最相关的规则。
第一,状态规则。
一个量子系统的状态,可以用一个向量表示。对一个量子比特来说,这个向量可以写成:
|ψ⟩ = α|0⟩ + β|1⟩
第二,演化规则。
如果不测量,一个封闭量子系统的变化可以用矩阵表示。这个矩阵必须保持总概率不变,所以它像旋转,不像拉伸。
第三,测量规则。
测量不会把量子态里的全部信息都读出来。测量只会给出一个经典结果,比如0或1。哪个结果出现,由振幅的模平方决定。
第四,复合规则。
多个量子系统放在一起,要用张量积组成一个更大的系统。正是这条规则,让多个量子比特的状态空间迅速变大,也让纠缠成为可能。
这四条规则,就是本书进入量子计算的入口。
它们听起来很抽象,但和计算机的关系非常直接:
| 量子规则 | 计算里的对应 |
|---|---|
| 状态是向量 | 量子比特的状态 |
| 演化是保持概率的矩阵 | 量子门 |
| 测量按概率给出结果 | 读出计算答案 |
| 多系统用张量积合成 | 多量子比特寄存器 |
有了这张表,你就能看出本书的路线:
从向量到量子比特,从矩阵到量子门,从张量积到多量子比特系统,从测量到算法输出。
1.8 第一次量子革命:利用量子规律
量子力学建立以后,并没有只停留在黑板上。
它很快改变了技术世界。
激光、半导体、晶体管、核磁共振、现代材料科学,都离不开量子力学。你手机里的芯片,本质上也是量子力学成功进入工程世界的结果。
这通常被称为第一次量子革命。
第一次量子革命的特点是:我们利用了量子规律,但并不一定逐个操控单个量子系统。
比如晶体管利用了半导体材料的量子性质,但工程师不需要在计算时一个一个操控单个电子的量子态。
激光利用了原子和光的量子规律,但我们通常把它当成一种稳定的光源来使用。
换句话说,第一次量子革命让量子规律变成了材料、器件和工具。
它让现代电子工业成为可能。
但它还不是量子计算。
1.9 第二次量子革命:主动操控量子态
第二次量子革命的变化在于:我们不只是利用材料整体的量子性质,而是开始主动操控单个或少数量子系统。
我们开始问:
- 能不能制备一个指定的量子态?
- 能不能让它按我们的设计演化?
- 能不能把多个量子系统纠缠起来?
- 能不能在最后读出我们想要的信息?
这些问题一旦连起来,就很接近量子计算了。
量子计算的基本循环正是:
制备 → 演化 → 测量
先准备初始量子态。
再用量子门改变它。
最后测量,得到经典结果。
这和第零章的数学工具完全对应:
- 制备:准备一个向量
- 演化:让矩阵作用在向量上
- 测量:按概率读出结果
所以,量子计算既是物理的,也是数学的。
说它是物理的,是因为你必须真的有一个量子系统,比如光子、离子、超导电路。
说它是数学的,是因为在量子线路层面,它可以被清楚地写成向量和矩阵的运算。
这正是本书想走的路:先抓住数学结构,再回到物理实现。
1.10 三个后面会反复出现的词
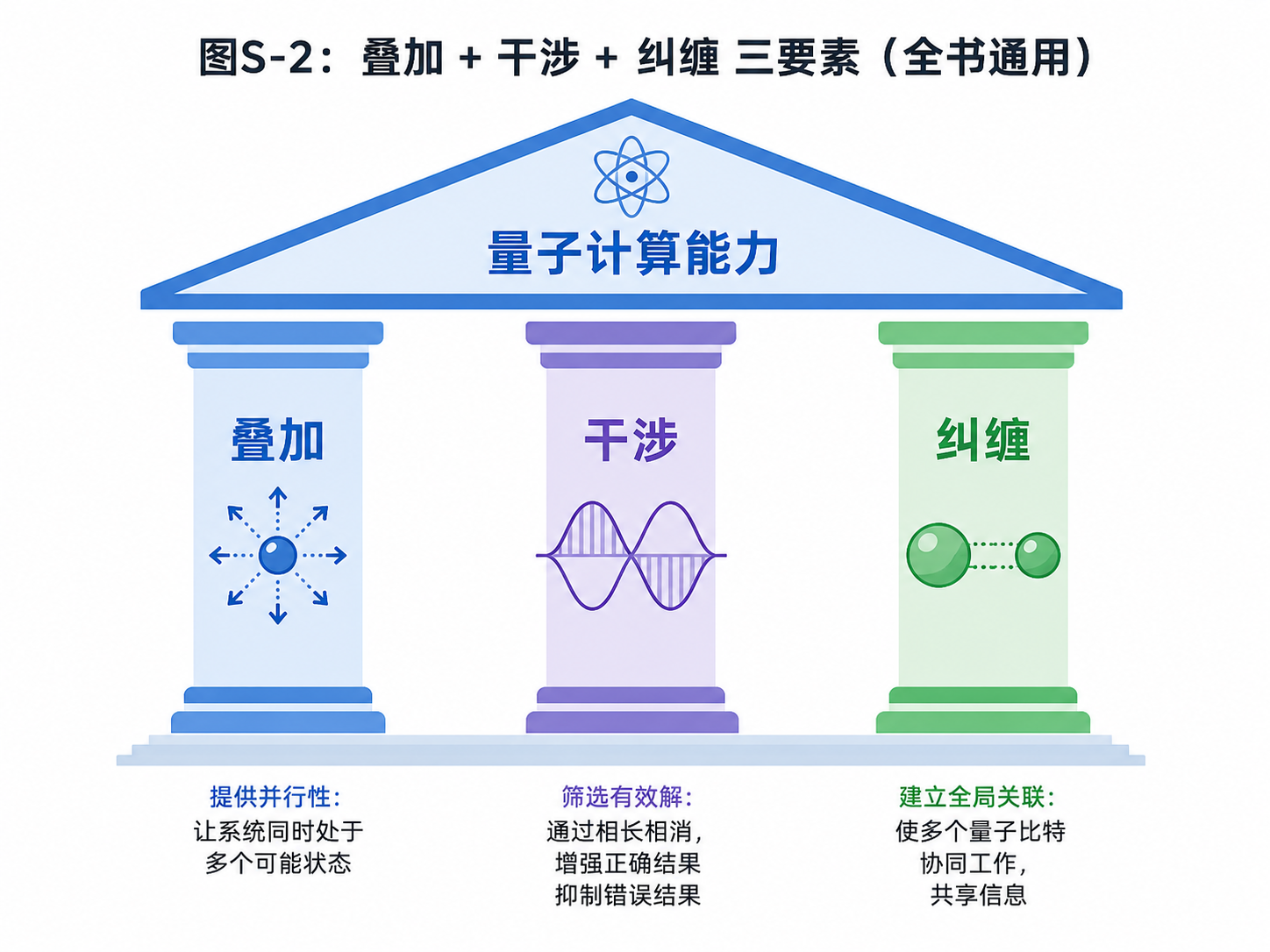
从四条规则出发,后面会反复出现三个词:叠加、干涉、纠缠。
第一,叠加。
量子态可以同时带有多个基本状态的分量。一个量子比特可以写成 α|0⟩ + β|1⟩,多个量子比特可以带着更多分量。这给了量子计算更大的状态空间。
第二,干涉。
振幅可以相互加强,也可以相互抵消。量子算法真正的技巧,不是“把所有答案都读出来”,而是让错误答案的振幅抵消,让正确答案的振幅变大。
第三,纠缠。
多个量子比特放在一起后,有些状态不能拆开描述。它们必须作为整体来看。纠缠让多量子比特系统拥有经典系统很难模拟的关联。
这三个词会在后面一遍遍出现。
但现在不用急着完全掌握它们。
我们只要先记住:
叠加提供空间,干涉帮助筛选,纠缠带来整体关联。
更完整的计算含义,会在第三章、第五章和第六章展开。
1.11 本章小结:历史最后落到计算
本章从普朗克讲到量子计算,看起来跨度很大,但主线其实很简单。
第一,普朗克和爱因斯坦让我们看到:能量和光可以一份一份出现。
第二,玻尔让我们看到:微观系统的状态有自己的离散结构。
第三,德布罗意、海森堡、薛定谔让我们看到:微观世界不能只用日常粒子图像来描述,需要新的数学语言。
第四,狄拉克把这种语言整理得更统一,让状态、内积、测量这些概念变得更容易书写。
第五,到了量子计算这里,我们把这套语言用于信息处理:用量子态表示信息,用量子门处理信息,用测量读出信息。
所以,量子计算不是从天而降的技术。它是量子力学的一种新用法:把原本用来描述微观世界的规则,转化为一种新的计算方式。
下一章,我们会回到读者更熟悉的地方:经典计算机。
我们先看经典计算是怎么从电信号、继电器、逻辑门一步步搭出来的。只有看清经典门做了什么,后面才能真正看清量子门哪里不同。
第二章 经典计算机:从电信号到逻辑门
上一章我们从量子力学的历史走到量子计算,最后落在一句话上:
用量子态表示信息,用量子门处理信息,用测量读出信息。
这句话听起来已经很像计算机了。
但在真正进入量子门之前,我们要先回到更熟悉的经典计算机。
为什么?
因为量子计算不是凭空出现的。它很大程度上是在回答一个问题:
如果经典计算机用比特和逻辑门来计算,那么量子计算机能不能用量子比特和量子门来计算?
要理解后半句,必须先把前半句看清楚。
本章不打算完整讲计算机组成原理。我们只沿着一条线走:
电信号 → 继电器 → 逻辑门 → 电路 → 处理器
这条线的目的只有一个:看清经典计算的底层规则。
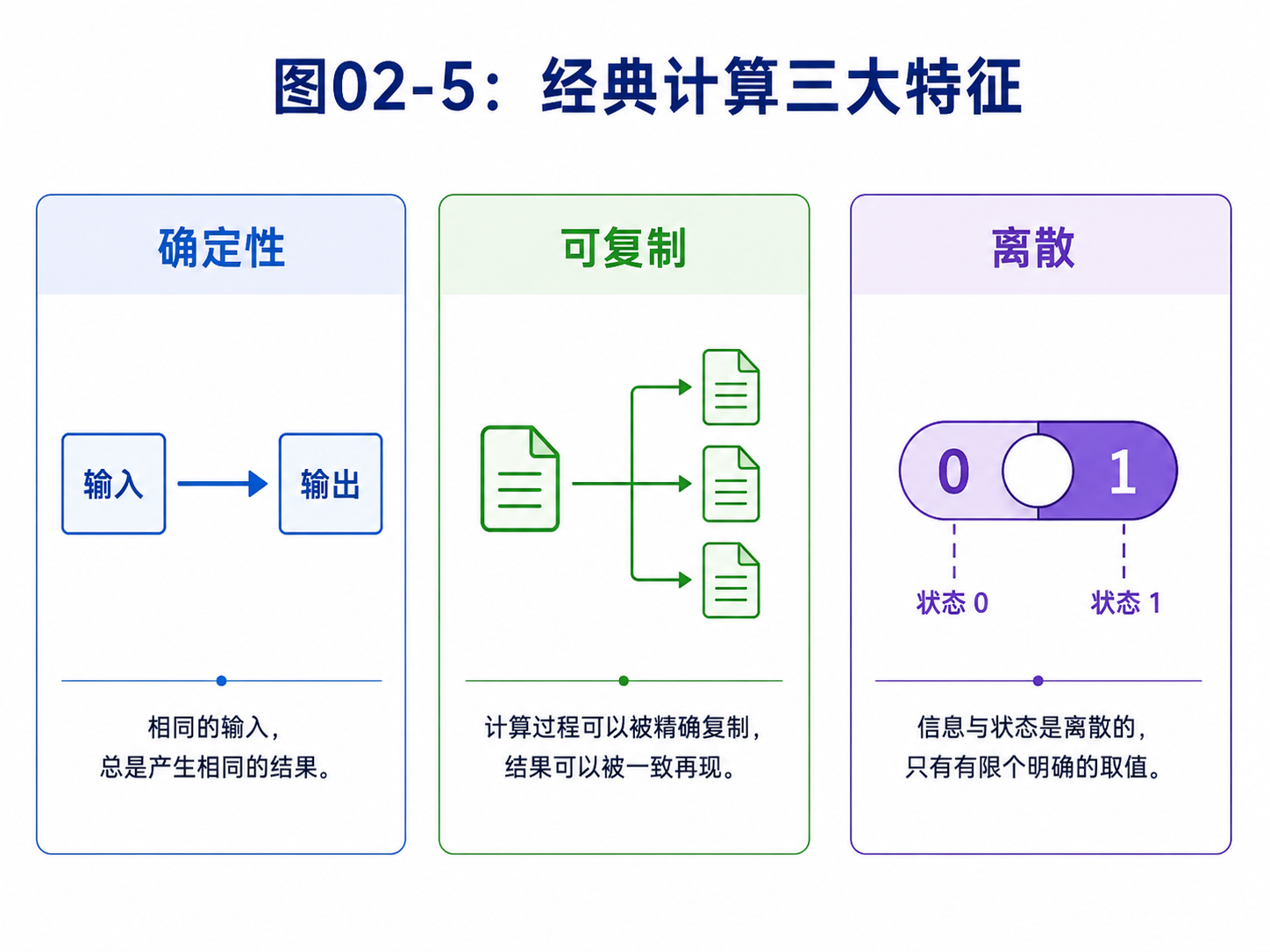
到了本章末尾,我们会总结出经典计算的三个特征:
- 确定性
- 可复制
- 状态离散
下一章讲量子门时,这三点会被逐条改写。
2.1 为什么是0和1
计算机为什么用0和1?
最简单的答案是:因为物理世界里,最容易稳定区分的状态通常就是两种。
开关可以开,也可以关。
电路可以通,也可以断。
电压可以高,也可以低。
磁性材料可以朝一个方向,也可以朝另一个方向。
这些都是两种状态。
当然,现实世界并不真的只有两种状态。电压可以是0.1伏、0.2伏、0.3伏,也可以在中间抖动。但工程上可以规定一个范围:高于某个阈值就算1,低于某个阈值就算0。中间的小波动,只要不越过阈值,就不会影响结果。
这就是数字电路的厉害之处。
它不是要求物理世界完美,而是把不完美的物理信号压成稳定的符号。
0和1不是抽象地飘在空中。它们在机器里总要落到某种物理状态上。
在继电器时代,0和1可以是电路断开和接通。
在晶体管时代,0和1可以是低电压和高电压。
在硬盘里,0和1可以是磁化方向。
在光通信里,0和1也可以是光信号的有无或不同调制状态。
所以,比特不是纯粹的数学符号。比特是物理状态和抽象符号之间的一座桥。
这一点对后面理解量子比特很重要。
量子比特也不是纯粹写在纸上的 |0⟩ 和 |1⟩。它也必须落到物理系统上,比如光子的偏振、离子的能级、超导电路的两个状态。
经典比特和量子比特的共同点是:它们都需要物理载体。
不同点是:经典比特只取0或1,而量子比特可以处在0和1的叠加里。
2.2 从电报到继电器
要理解逻辑门,可以从更早的电报说起。
电报的基本动作非常简单:按下电键,电路接通;松开电键,电路断开。远处的电磁铁跟着吸合或释放,于是就能发出长短不同的信号。
这已经是信息传递了。
有电,表示一种状态。
没电,表示另一种状态。
如果我们愿意,就可以把它们叫作1和0。
继电器在这个基础上又往前走了一步。
继电器的关键不是“传递信号”,而是“用一个信号控制另一个信号”。
它里面有一个电磁铁。小电流经过线圈时,电磁铁吸合,带动另一个开关接通或断开。也就是说,一个电路里的电信号,可以控制另一个电路。
这件事很重要。
因为计算不只是把信息从A传到B,而是要让信息改变信息。
如果一个信号能控制另一个信号,我们就可以开始做逻辑。
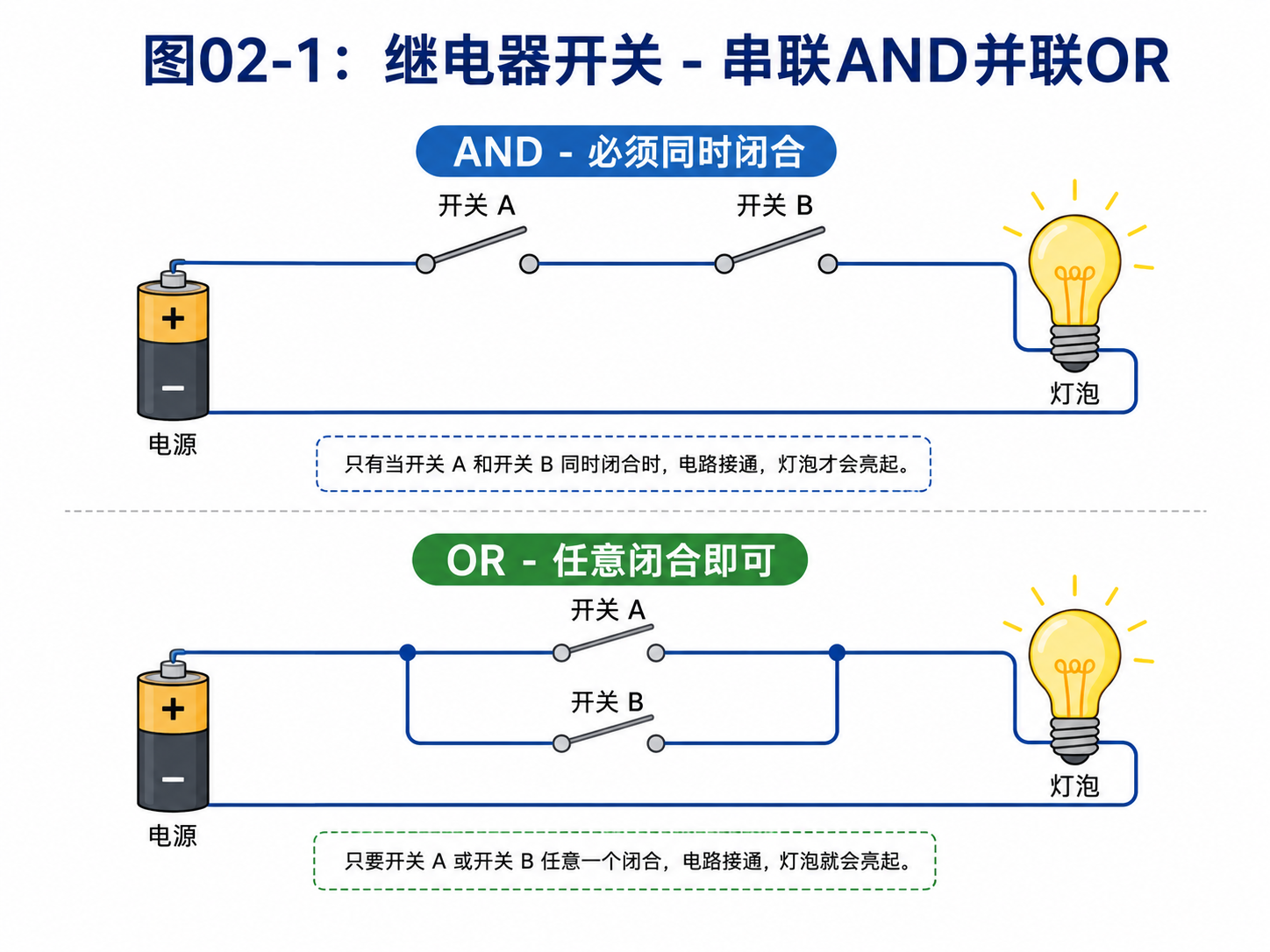
比如两个开关串联:
只有两个开关都接通,电路才通。
这就是 AND。
两个开关并联:
只要有一个开关接通,电路就通。
这就是 OR。
一个开关控制另一条线路的断开和接通,也可以做出 NOT。
你看,逻辑一开始并不是抽象公式。它可以由很具体的物理装置实现出来。
这就是本章最重要的直觉:
计算不是脱离物理的。计算是物理系统按某种规则变化。
经典计算如此,量子计算也如此。
2.3 布尔代数:把推理变成计算
有了物理开关,还需要一套语言来描述它们。
这套语言就是布尔代数。
布尔代数只处理两种值:真和假,或者1和0。
它有几个基本操作:
- AND:两个条件都满足,结果才为真
- OR:至少一个条件满足,结果就为真
- NOT:把真变假,把假变真
这看起来像逻辑课。
但它也是计算机的底层语言。
比如:
A AND B
可以理解成一句逻辑判断:
A成立,并且B也成立。
也可以理解成一个电路:
开关A和开关B串联,两个都接通,电流才能通过。
这就是布尔代数的力量:它把推理、符号和物理电路连在了一起。
在纸上,它是逻辑表达式。
在电路里,它是门和线。
在程序里,它是条件判断。
这一点和量子计算也很像。
量子计算的纸面语言是向量和矩阵。
量子计算的物理实现是光子、离子、超导电路等真实系统。
两者之间,也需要一座桥。
2.4 逻辑门:把布尔代数做成机器
布尔代数里的 AND、OR、NOT,如果用继电器或晶体管实现出来,就是逻辑门。
逻辑门的特点是非常清楚的:
输入是什么,输出就是什么。
没有模糊地带。
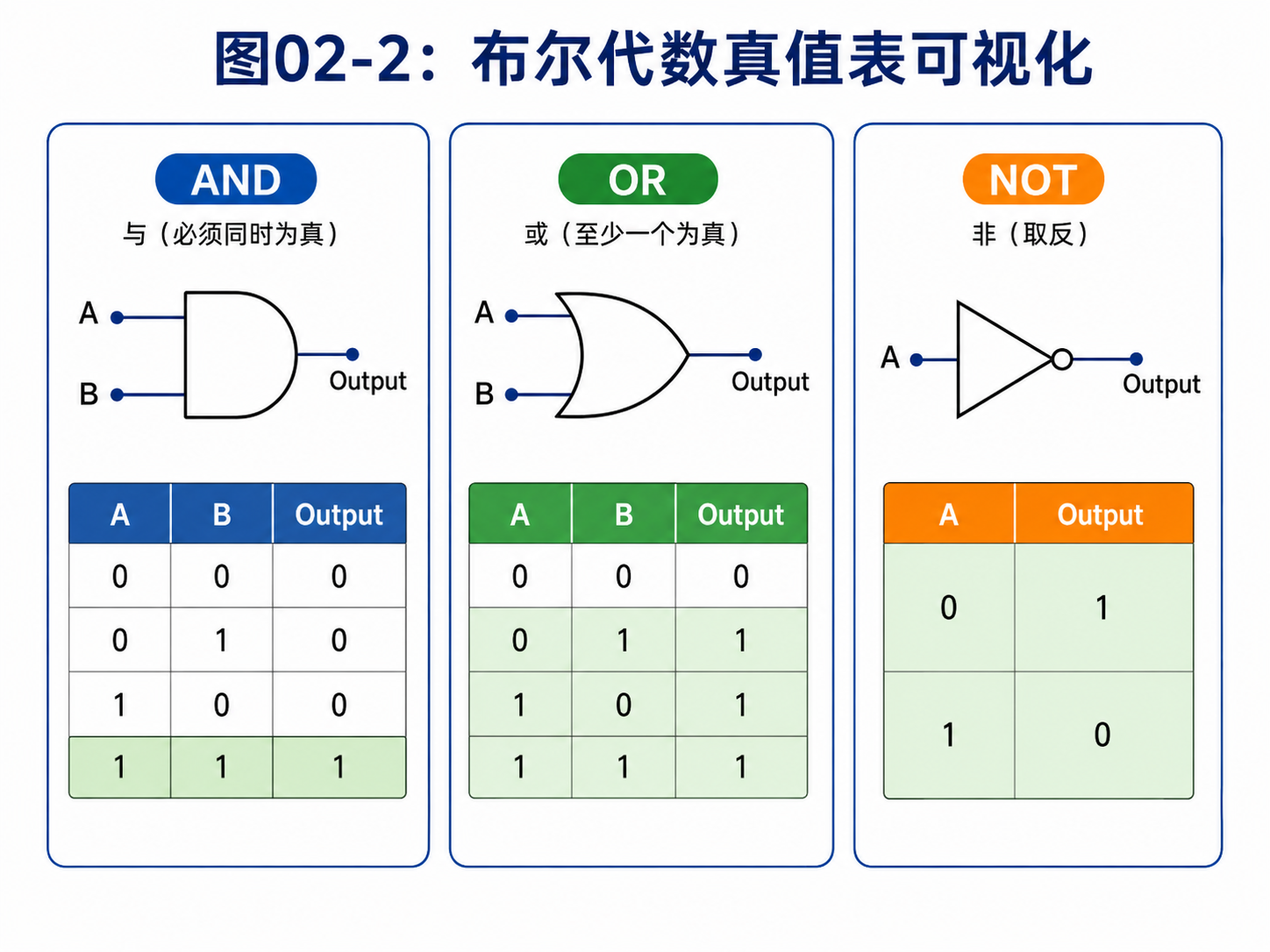
比如 AND 门:
| A | B | A AND B |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 0 |
| 1 | 0 | 0 |
| 1 | 1 | 1 |
这张表叫真值表。
真值表的意思是:所有可能输入都列出来,每一种输入对应唯一输出。
OR门也一样:
| A | B | A OR B |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 1 |
NOT门更简单:
| A | NOT A |
|---|---|
| 0 | 1 |
| 1 | 0 |
有了这些门,就可以搭出更复杂的计算。
不过真正的计算机并不一定要把 AND、OR、NOT 都做一遍。事实上,只用一种门也够。
比如 NAND 门。
NAND 的意思是:先 AND,再 NOT。
也就是:
NOT (A AND B)
NAND 很重要,因为只用 NAND 门就能搭出任意布尔逻辑。
这叫通用性。
通用性是计算机科学里非常重要的思想:只要基本组件足够合适,就不需要无穷多种零件。少数几种门,反复组合,就能构造复杂系统。
后面讲量子门时,我们会看到同样的思想:量子计算也有通用门集。少数几种量子门,原则上可以组合出任意量子算法。
2.5 从门到电路
单个逻辑门能做的事情很少。
但门可以组合。
这就像积木。一个积木很简单,一堆积木就能搭出房子、桥、城堡。
计算机也是这样。
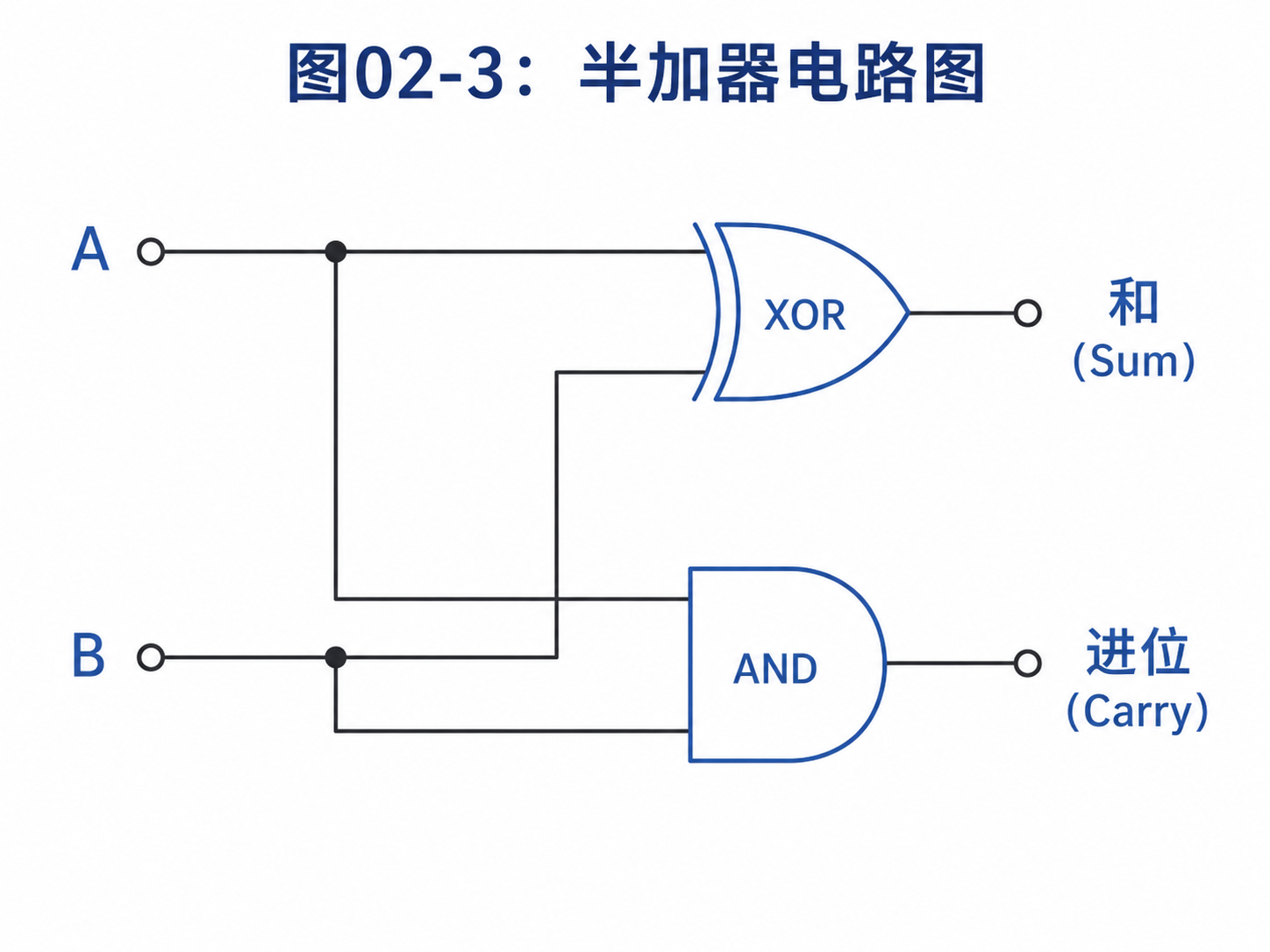
先看一个最简单的例子:加法。
如果你要加两个一位二进制数:
0 + 0 = 0
0 + 1 = 1
1 + 0 = 1
1 + 1 = 10
最后一行说明:两个1相加,结果不是一位,而是产生了进位。
这就需要两个输出:
- 当前位的结果
- 进位
当前位的结果可以由 XOR 门给出。
进位可以由 AND 门给出。
这就是半加器。
如果还要处理来自低位的进位,就需要全加器。
多个全加器串起来,就能做多位二进制加法。
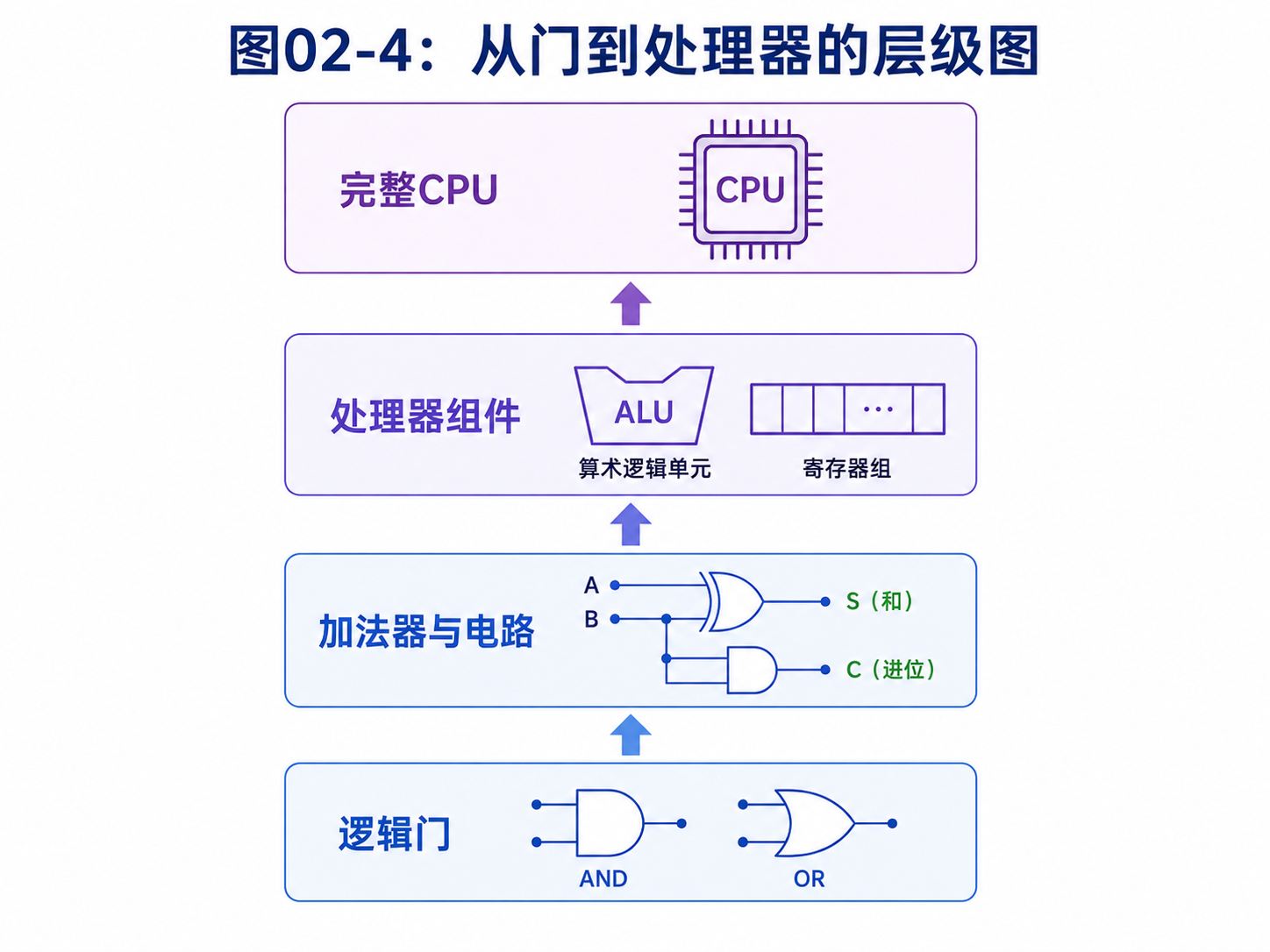
这就是从门到电路的过程。
逻辑门本身很小,但它们一层层组合以后,就能实现加法器、选择器、译码器、寄存器,最后组成处理器。
这一层层组合,对理解量子计算非常有用。
因为量子计算也不是靠单个量子门完成复杂任务。
它也是把很多量子门连成量子线路。
经典线路里,线传递经典比特。
量子线路里,线表示量子比特的状态沿着时间往前演化。
经典门改变0和1。
量子门改变振幅和相位。
这就是两者最直接的平行关系。
2.6 从电路到处理器
一堆组合电路还不等于完整计算机。
计算机还需要存储中间结果,需要按步骤执行指令,需要知道下一步该做什么。
于是就有了处理器。
一个简化版处理器可以分成几块:
- 运算单元:做加法、逻辑运算等
- 寄存器:临时保存数据
- 控制单元:决定每一步做什么
- 时钟:给所有部件统一节拍
处理器的工作可以粗略看成一个循环:
取指令 → 解码 → 执行 → 写回
取指令:从内存里拿下一条指令。
解码:弄清这条指令要做什么。
执行:让相应电路工作。
写回:把结果存回寄存器或内存。
这个循环非常快,快到我们平时感觉不到。但从底层看,它仍然是一连串逻辑门在翻转状态。
每一步都很确定。
输入相同,电路相同,输出就相同。
这就是经典计算机给我们的稳定感。
写一段程序,今天跑是这个结果,明天跑还是这个结果。硬件没有坏、输入没有变,输出就不会随缘漂移。
量子计算会打破这种直觉的一部分。
量子门本身仍然按确定规则演化量子态,但测量结果带有概率性。这就是后面最容易混淆的地方:量子态的演化是可计算的,测量结果却不是每次都一样。
2.7 经典计算的三个特征
现在我们可以总结经典计算的三个关键特征。
第一,确定性。
一个经典逻辑门有明确真值表。输入确定,输出确定。
AND门不会今天看到 1 AND 1 输出1,明天突然输出0。
第二,可复制。
经典比特可以读出,也可以复制。你可以把一个文件复制十份,可以把一个变量打印出来,可以把同一份数据发给多个模块。
这件事太自然了,以至于我们平时不会注意它。
但到了量子世界,它会变成大问题。
未知量子态不能随便复制。测量中间状态还会破坏它。正因为如此,量子程序不能像经典程序一样随便打印中间变量。
第三,状态离散。
经典比特不是0就是1。一个8位寄存器,在某一时刻只保存256种可能值中的一个。
它当然可以在不同时间变成不同值,但在某一个时刻,它有明确值。
这给经典计算带来稳定性,也带来边界。
如果你要在很多可能性里找答案,经典计算通常需要逐个检查,或者用很多硬件并行检查。
量子计算的不同之处在于:n个量子比特可以带着 2ⁿ 个振幅。它不是一次读出 2ⁿ 个答案,而是给算法提供了一个更大的状态空间。
这就是下一章要开始对比的地方。
2.8 经典计算的边界
说经典计算有边界,不是说经典计算不好。
恰恰相反,经典计算极其成功。
它稳定、便宜、可扩展,支撑了现代社会几乎所有信息系统。我们写代码、存照片、看视频、训练模型,绝大部分都依赖经典计算。
但任何计算模型都有自己的规则,也就有自己的边界。
经典计算的边界,来自它的基本选择:
- 比特只能是0或1
- 门按真值表确定输出
- 信息可以复制
- 中间结果可以反复读取
这些选择带来稳定性,也意味着它处理某些问题时只能按经典方式展开。
比如无序搜索。
如果有N个盒子,其中一个藏着目标。你没有任何额外线索,只能打开盒子检查。经典方法最坏就要检查N次。
多找几个人一起查当然有用,但只是把工作分摊。问题规模一大,压力仍然很快回来。
再比如大整数分解。
我们知道经典计算机可以分解小整数,也有很多聪明算法。但对非常大的数,已知经典算法仍然很吃力。Shor算法之所以出名,就是因为量子计算提供了完全不同的思路:不是逐个试因子,而是把问题转成周期寻找。
所以,量子计算不是要取代经典计算。
它更像是补上一种新的计算方式。
对于很多普通任务,经典计算仍然最好。
但对某些有特殊结构的问题,量子计算可能走出一条经典计算很难走的路。
2.9 为下一章做准备:经典门和量子门的对照
本章讲了经典计算从哪里来。
它不是从抽象符号开始,而是从物理信号开始:有电或没电,高电压或低电压,开或关。
然后这些物理状态被抽象成0和1。
0和1再通过布尔代数组织起来。
布尔代数被做成逻辑门。
逻辑门再组合成电路和处理器。
这条路可以写成:
物理状态 → 比特 → 逻辑门 → 电路 → 计算机
下一章,我们会走一条平行路线:
量子状态 → 量子比特 → 量子门 → 量子线路 → 量子计算机
这两条路线看起来相似,但关键地方完全不同。
经典比特非0即1,量子比特可以叠加。
经典门查真值表,量子门旋转向量。
经典信息可以复制,未知量子态不能复制。
经典测量通常不破坏数据,量子测量会改变状态。
看清这些差异,量子计算就不会显得玄。它只是换了一套底层规则。
下一章,我们就从经典门走向量子门。
第三章 从经典门到量子门
上一章,我们沿着经典计算机的路线走了一遍:
物理状态 → 比特 → 逻辑门 → 电路 → 计算机
这一章,我们走一条平行路线:
量子状态 → 量子比特 → 量子门 → 量子线路 → 量子计算机
这两条路线看起来很像,但底层规则完全不同。
经典比特只有0和1。
量子比特可以是0和1的叠加。
经典门查真值表。
量子门旋转向量。
经典信息可以复制。
未知量子态不能复制。
经典测量通常不改变数据。
量子测量会改变状态。
这一章的目标,就是把这些差异讲清楚。
不是为了让量子计算显得神秘,恰恰相反,是为了去掉神秘感。量子计算不是魔法,它只是换了一套底层规则。
3.1 从比特到量子比特
经典比特很干脆:不是0,就是1。
这件事在第二章已经讲过。0和1可以落到很多物理状态上,比如低电压和高电压、断路和通路、磁化方向的两种取向。
经典比特的好处是稳定。
你读它,知道它是0还是1。
你复制它,副本还是0或1。
你把它送进逻辑门,输出也由真值表确定。
量子比特也有两个基本状态,仍然记作:
|0⟩, |1⟩
但它不只能停在这两个位置上。
它可以写成:
|ψ⟩ = α|0⟩ + β|1⟩
这就是叠加。
如果说经典比特像开关,量子比特更像一个箭头。|0⟩ 是一个方向,|1⟩ 是另一个方向。量子态可以指向两者之间的某个方向。
这里的 α 和 β 是振幅。它们不是直接的概率,但它们的模平方给出概率:
测到0的概率 = |α|²
测到1的概率 = |β|²
这也解释了为什么我们要求:
|α|² + |β|² = 1
所有可能结果的概率加起来必须是100%。
所以,量子比特并不是“既是0又是1”这么一句话就能讲完。更准确地说,它是一个带有两个分量的状态。测量之前,这两个分量都参与后续计算;测量之后,只得到一个经典结果。
这就是量子比特和经典比特的第一道分界线。
3.2 从查表到旋转
经典门像查表。
AND门的规则很清楚:
0 AND 0 = 0
0 AND 1 = 0
1 AND 0 = 0
1 AND 1 = 1
输入是什么,输出就是什么。没有中间过程,也没有概率。
量子门不是这样。
量子门作用的对象不是一个确定的0或1,而是一个向量。
因此,量子门更像一次旋转。
它把一个量子态转到另一个量子态,但不能随便拉长或压短这个向量。因为向量长度关系到总概率,总概率必须一直是1。
这种保持长度的矩阵,叫酉矩阵。
你不需要一开始就熟练计算酉矩阵,只要先抓住直觉:
量子门改变方向,不改变总概率。
比如 X门。
它很像经典 NOT 门:
X|0⟩ = |1⟩
X|1⟩ = |0⟩
它把 |0⟩ 和 |1⟩ 对调。
再比如 H门,也叫 Hadamard 门:
H|0⟩ = (|0⟩ + |1⟩) / √2
H|1⟩ = (|0⟩ - |1⟩) / √2
它的作用很特别:可以把一个确定状态变成叠加态。
后面讲 Deutsch 算法时,H门会反复出现。它就像把一个明确输入展开,让多个可能性一起参与计算。
3.3 为什么量子门必须可逆
经典门不一定可逆。
比如 AND 门。
如果输出是1,你知道输入一定是 1,1。
但如果输出是0,你不知道输入到底是 0,0、0,1,还是 1,0。
来路信息丢了。
这在经典计算里很常见,也完全可接受。经典计算机可以丢信息,可以覆盖变量,可以擦除数据。只要我们愿意付出能量代价,工程上可以照样工作。
但量子门不行。
量子门必须保持状态长度,也必须保留足够的信息,让操作原则上可以倒回去。
直觉上说,如果量子门像旋转,那么你总可以反方向转回来。
这就是为什么经典AND门不能直接当量子门。
那量子计算怎么做类似“条件控制”的事情?
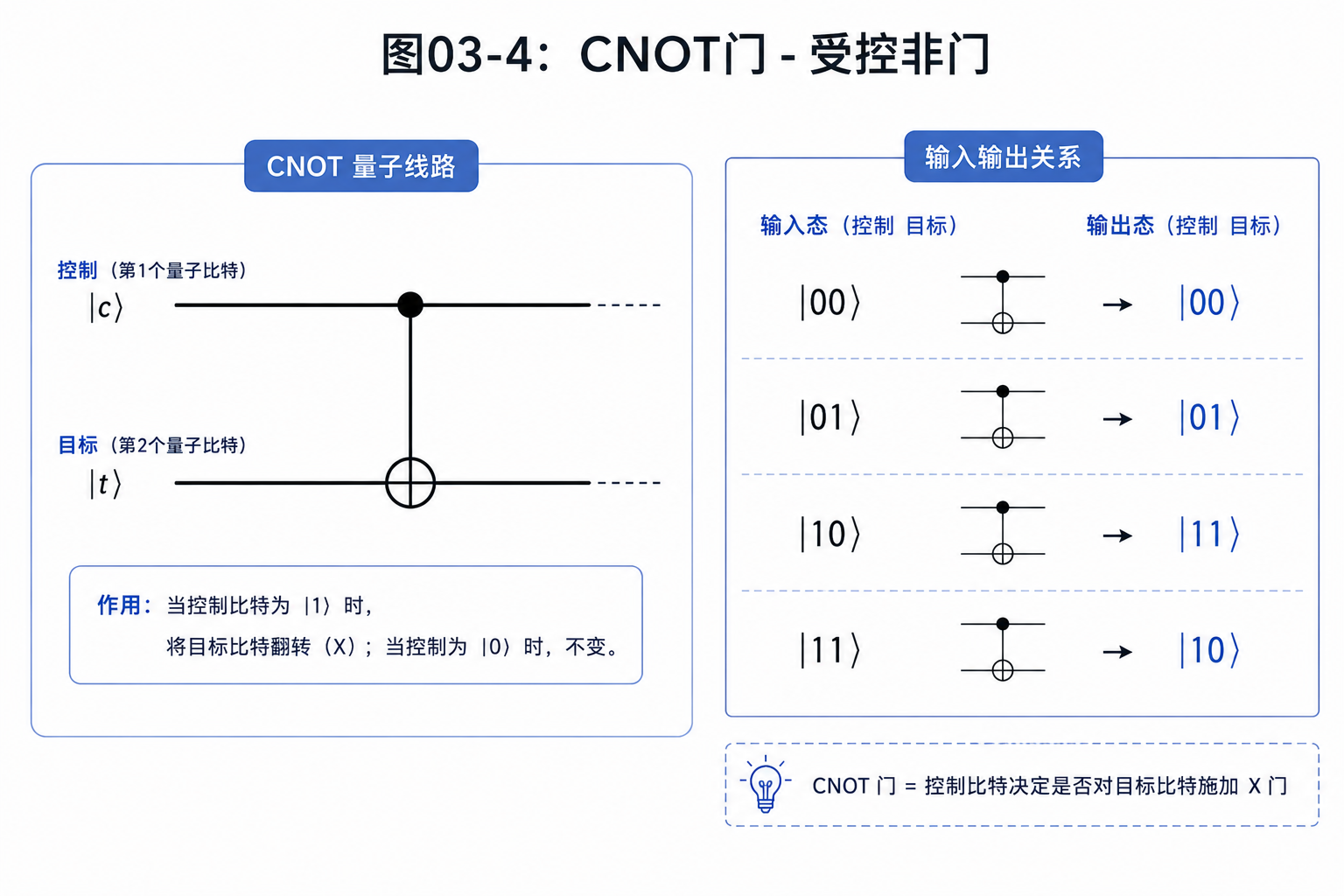
用受控门。
最常见的是 CNOT 门,也叫受控非门。
它有两个量子比特:
- 第一个叫控制比特
- 第二个叫目标比特
规则是:
如果控制比特是0,目标比特不变。
如果控制比特是1,目标比特翻转。
写成表就是:
| 输入 | 输出 |
|---|---|
| 00 | 00 |
| 01 | 01 |
| 10 | 11 |
| 11 | 10 |
注意,这张表是一一对应的。
每个输入都有唯一输出,每个输出也能倒推出唯一输入。
所以 CNOT 是可逆的。
它不是把两个比特压成一个比特,而是在两个比特的空间里重新排列状态。
这就是量子门和经典门很重要的区别:量子门不是随便计算一个函数,而是在状态空间里做可逆变换。
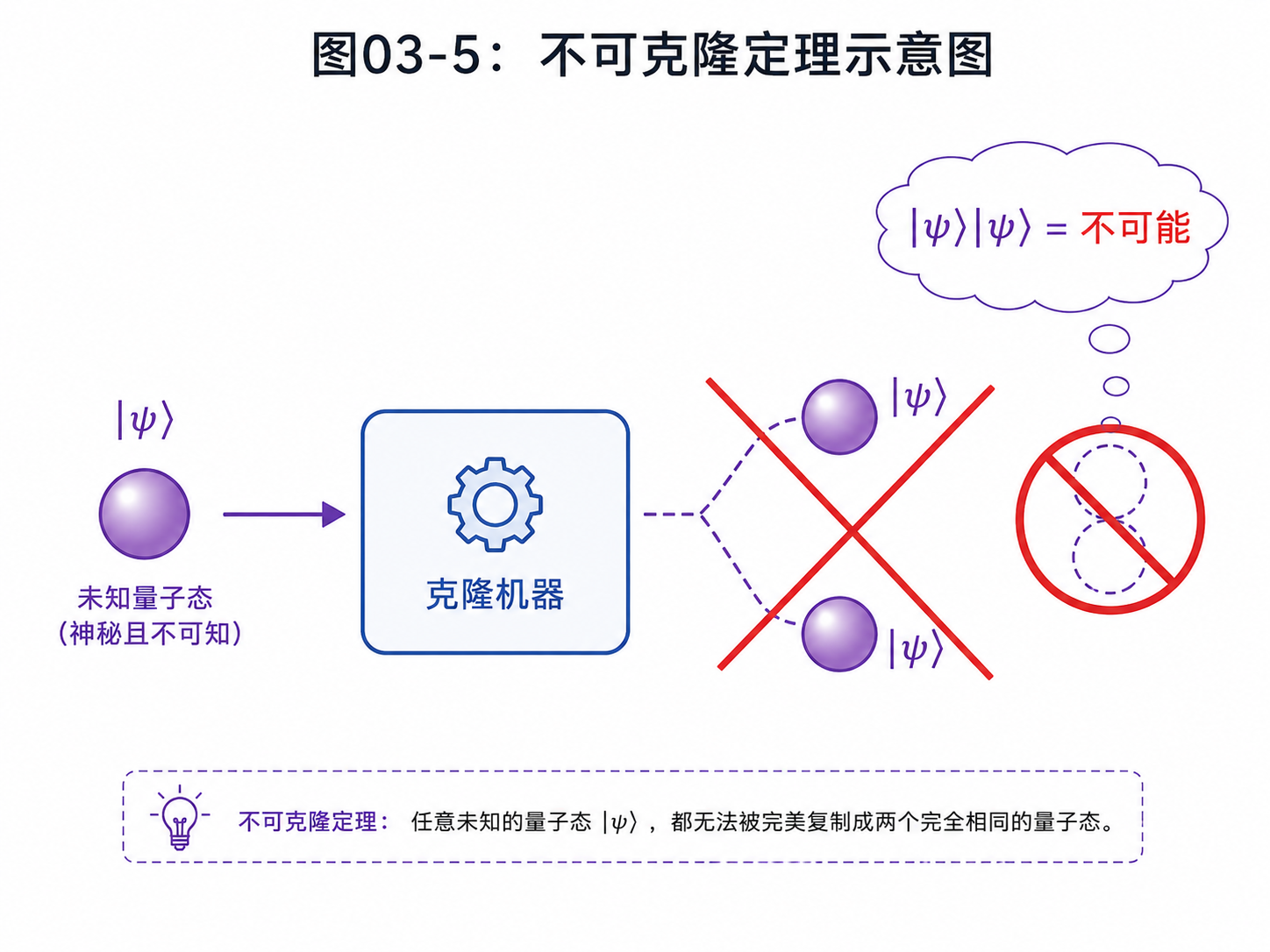
3.4 不能复制未知量子态
经典信息可以复制。
你可以复制一个文件,复制一个变量,复制一个比特。
这件事太自然了,以至于我们平时根本不会注意。
但量子世界里,未知量子态不能随便复制。
这叫不可克隆定理。
先看直觉。
如果一个量子态已经确定是 |0⟩,当然可以重新制备很多个 |0⟩。
如果已经确定是 |1⟩,也可以重新制备很多个 |1⟩。
问题出在未知叠加态:
|ψ⟩ = α|0⟩ + β|1⟩
如果你不知道 α 和 β,就不能造出一个通用机器,把任意 |ψ⟩ 都复制成两份。
为什么?
因为量子操作必须是线性的。
如果一个复制机能复制 |0⟩,也能复制 |1⟩,那么它作用在 α|0⟩ + β|1⟩ 上时,线性规则会给出一种结果。
但真正“复制两份叠加态”需要的是另一种结果。
两者一般对不上。
所以,万能复制机不存在。
这个结论很反直觉,但它非常重要。
它意味着你不能在量子程序中随便备份中间状态。
也不能像经典调试那样,把中间变量打印出来看看。
一旦测量,中间状态就被改变了。
这会直接影响量子算法的设计方式。
经典程序可以边跑边看,量子程序更像提前设计好的一条线路:先制备,再演化,最后测量。中间每一步都必须在数学上算清楚。
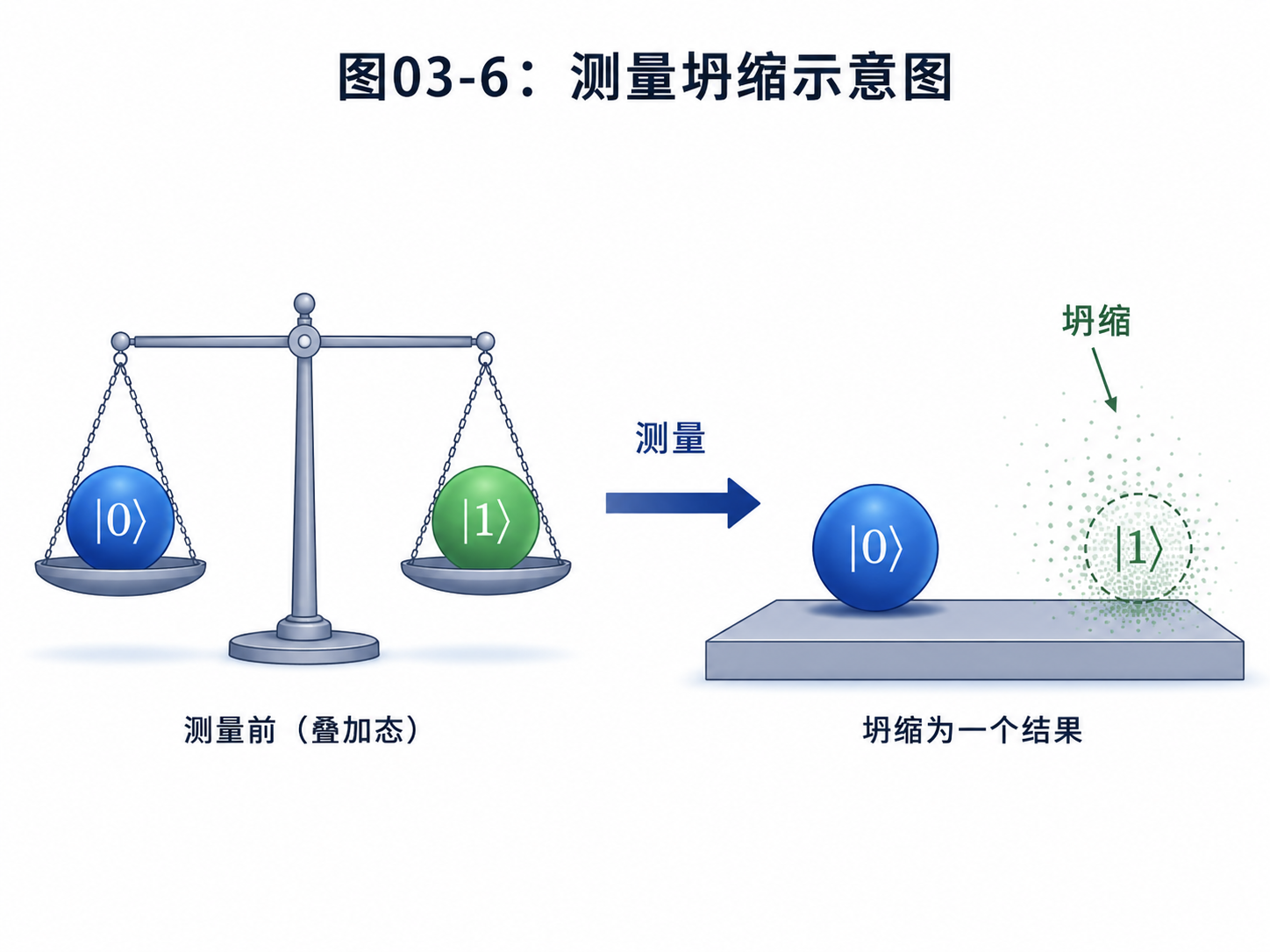
3.5 测量不是读取,是改变
经典计算里,读取数据通常不会改变数据。
你打开一个文件,文件还在。
你打印一个变量,变量还在。
你读取内存里的一个比特,它不会因为被读了一次就消失。
但量子测量不一样。
量子态测量前可能是:
(|0⟩ + |1⟩) / √2
测量时,你只会得到0或1。
如果测到0,状态就变成 |0⟩。
如果测到1,状态就变成 |1⟩。
原来的叠加态不在了。
所以,测量不是“无损读取”。它更像是把量子态压成一个经典答案。
这也是量子计算最容易被误解的地方。
有人会说:n个量子比特可以表示 2ⁿ 个状态,那是不是一测就能读出 2ⁿ 个答案?
不能。
测量一次只给你一个经典结果。
量子算法真正做的,是在测量之前调整振幅,让正确答案更容易被测出来。
这句话会在后面反复出现。
3.6 纠缠:不能拆开的整体
一个量子比特可以叠加。
两个量子比特放在一起,会发生更有意思的事:纠缠。
两个经典比特也可以有关联。
比如两个比特总是相同:00或11。
但你仍然可以说,第一个比特有自己的值,第二个比特也有自己的值。它们只是值之间有关系。
量子纠缠更强。
比如这个状态:
(|00⟩ + |11⟩) / √2
它表示:两个量子比特作为整体,处在 |00⟩ 和 |11⟩ 的叠加中。
你不能单独拿出第一个量子比特,说它自己处在某个确定的纯态里。也不能单独拿出第二个量子比特说清楚全部情况。
它们必须放在一起描述。
这就是纠缠。
纠缠不是两个比特之间偷偷传信号。
它更像是:这两个量子比特从一开始就属于同一个整体状态。你只看局部,看不到完整信息。
纠缠是量子计算中非常重要的资源。
没有纠缠,很多多量子比特系统就容易被经典计算模拟。纠缠让系统的整体结构变得更复杂,也让量子计算在某些问题上有机会获得优势。
当然,本章只先建立直觉。
后面讲多量子比特、算法和纠错时,纠缠会再次出现。
3.7 经典门和量子门的对照
现在我们把前面的差异放在一张表里。
| 维度 | 经典计算 | 量子计算 |
|---|---|---|
| 基本单元 | 比特,只能是0或1 | 量子比特,可以是叠加态 |
| 状态描述 | 一个确定值 | 一个向量 |
| 操作方式 | 查真值表 | 用矩阵旋转向量 |
| 可逆性 | 有些门不可逆,比如AND | 量子门原则上可逆 |
| 复制 | 可以随便复制 | 未知量子态不能复制 |
| 读取 | 通常不改变数据 | 测量会改变状态 |
| 多比特关系 | 可以用局部值和逻辑关系描述 | 可能出现纠缠,必须整体描述 |
这张表不是为了背概念,而是为了建立一条清楚的线:
经典计算的核心是比特和逻辑门。
量子计算的核心是量子比特和量子门。
形式上很像。
规则上完全不同。
正是这种“结构相似、规则不同”,让量子计算既能和经典计算对照,又能走出自己的能力边界。
3.8 几个常见量子门
为了让量子门不只是抽象概念,我们先认识几个常见门。
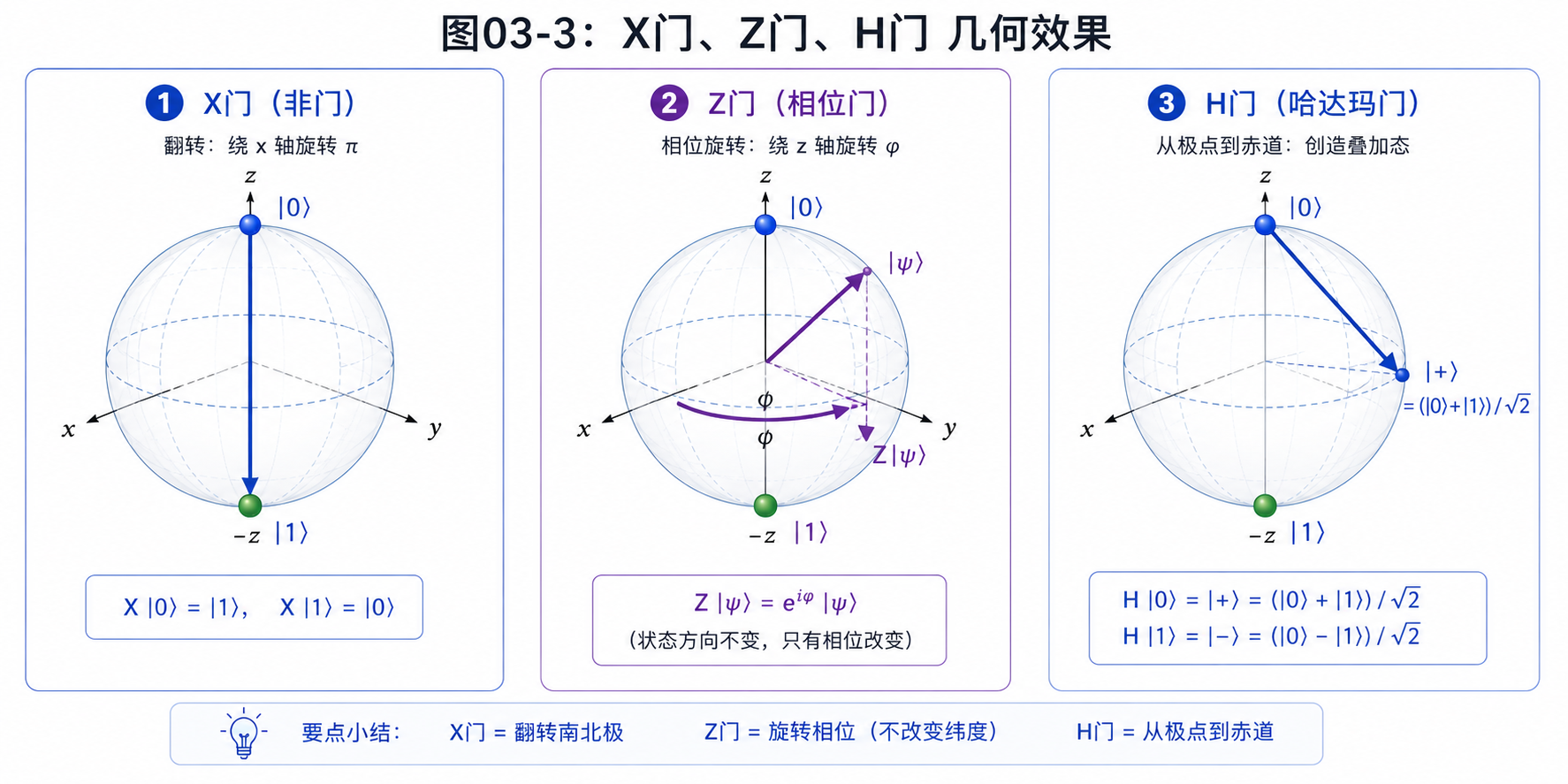
第一,X门。
它像经典 NOT 门:
X|0⟩ = |1⟩
X|1⟩ = |0⟩
所以它也常被叫作量子 NOT。
第二,Z门。
它不改变 |0⟩ 和 |1⟩ 被测到的概率,但会改变相位:
Z|0⟩ = |0⟩
Z|1⟩ = -|1⟩
这个负号很重要。
在经典计算里,1 和 -1 可能只是数值不同。但在量子计算里,负号会影响后面的干涉。两个路径相遇时,符号相反可能会抵消。
第三,H门。
H门可以制造叠加:
H|0⟩ = (|0⟩ + |1⟩) / √2
H|1⟩ = (|0⟩ - |1⟩) / √2
它会在后面的算法里频繁出现。
你可以先把H门看成一个“展开器”:它把一个确定状态展开成两个方向的叠加。
第四,CNOT门。
CNOT是双量子比特门。它根据第一个量子比特的状态,决定是否翻转第二个量子比特。
更重要的是,当控制比特处在叠加态时,CNOT可以把两个量子比特纠缠起来。
例如:
先让第一个量子比特经过H门:
|0⟩ → (|0⟩ + |1⟩) / √2
再加上第二个量子比特 |0⟩:
(|00⟩ + |10⟩) / √2
然后作用 CNOT:
(|00⟩ + |11⟩) / √2
这就是一个纠缠态。
这两个门 H 和 CNOT 的组合非常重要。H制造叠加,CNOT制造关联。很多量子线路都离不开它们。
3.9 量子线路:矩阵连乘的计算
经典电路是逻辑门连起来。
量子线路也是门连起来。
但解释方式不同。
经典线路里,一条线通常表示一个比特的值从左往右传。
量子线路里,一条线表示一个量子比特的状态随时间演化。
每遇到一个量子门,状态就被变换一次。
如果先作用H门,再作用X门,那么整体操作就是:
XH|ψ⟩
注意顺序:右边的门先作用。
这和函数复合很像。先做里面的,再做外面的。
多个量子比特时,如果两个门并排作用,就用张量积描述;如果前后作用,就用矩阵乘法描述。
所以,第零章说过的两句话现在派上用场了:
- 串联是矩阵乘法
- 并联是张量积
量子线路看起来像电路图,但本质上是一串向量和矩阵的计算。
这就是为什么本书一直说:在量子线路层面,量子计算可以先理解为线性代数。
3.10 本章小结:不是升级,而是换规则
本章从经典门走到了量子门。
经典门和量子门有相似的外形:都是小方块,都接在线路上,都一步步组成更复杂的电路。
但它们不是同一种东西。
经典门处理的是确定的0和1。
量子门处理的是向量。
经典门可以丢信息。
量子门必须保持总概率,原则上可逆。
经典信息可以复制。
未知量子态不能复制。
经典读取通常不改变数据。
量子测量会改变状态。
这就是后面所有量子算法的底层约束。
它既带来麻烦,也带来机会。
麻烦在于:不能随便复制、不能随便测量、不能随便调试。
机会在于:可以利用叠加、相位、干涉和纠缠,设计经典计算没有的算法路径。
下一章,我们暂时离开抽象线路,用光子来做一个物理插曲。
到时候你会看到:量子比特不是纸面符号,量子门也不是纯数学对象。它们可以落到真实物理装置上,比如光子的偏振、波片和探测器。
第四章 光量子比特:从数学到看得见的物理
前三章一直在讲抽象结构。
量子态是向量。
量子门是矩阵。
测量会把量子态压成经典结果。
这些说法是对的,但读者很自然会问:
这些东西到底长什么样?
一个量子比特是纸上的 α|0⟩ + β|1⟩,还是实验室里某个真实东西?
量子门是一个矩阵,还是一个真实装置?
测量是公式,还是探测器真的“咔哒”一下给出结果?
本章用光子来回答这些问题。
光子不是唯一的量子计算平台,也不一定是工程上最主流的路线。但它非常适合教学。因为光子的偏振容易想象,偏振片、波片、分束器也都比较直观。
所以本章的目标不是把光量子计算工程讲全,而是建立一幅画面:
光子 → 量子比特
波片 → 量子门
偏振分束器 + 探测器 → 测量
有了这幅画面,前面那些符号就不再只停留在纸上。
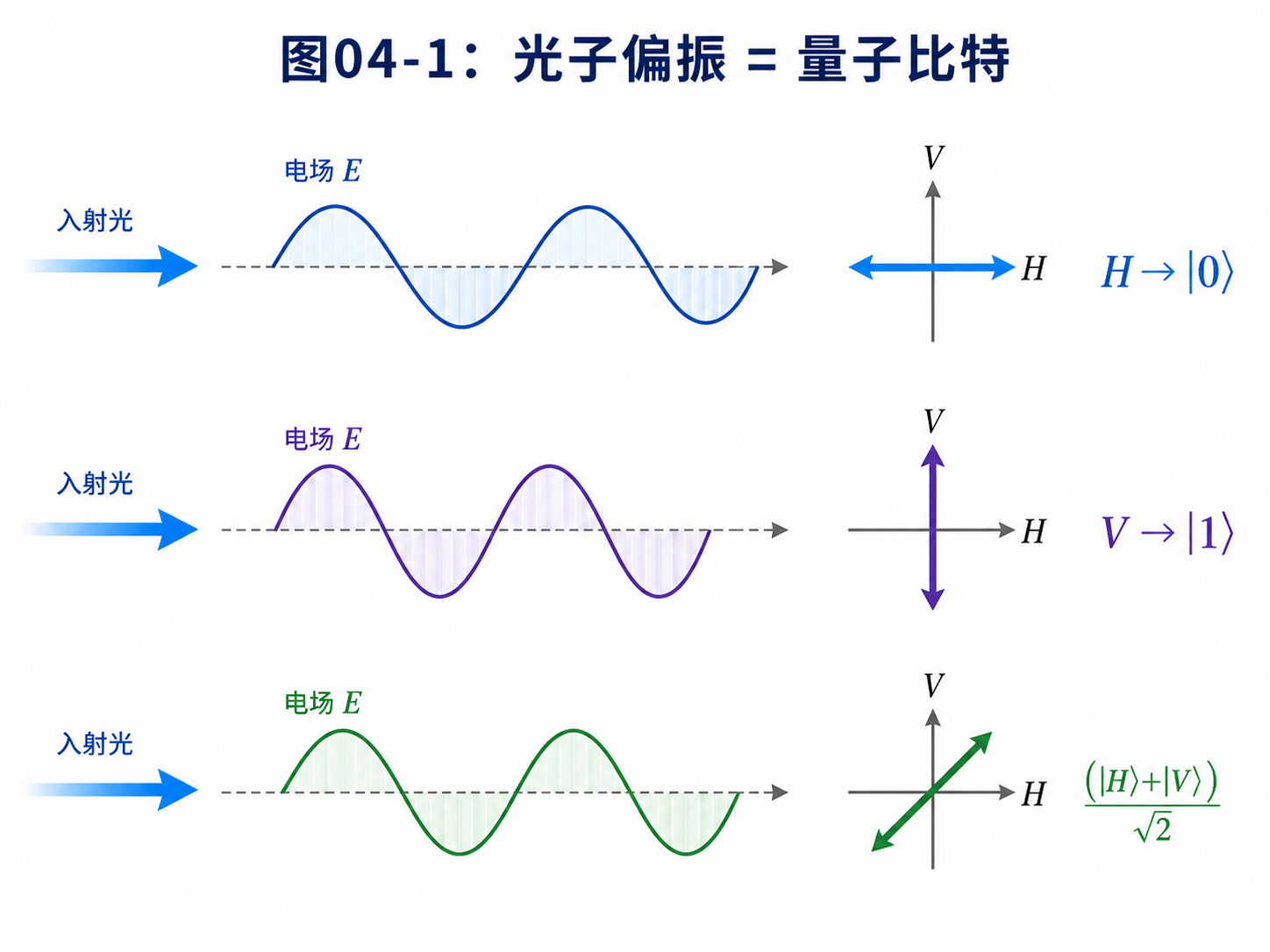
4.1 用光子的偏振表示量子比特
我们先从一个光子开始。
光子可以有偏振。偏振可以先粗略理解成:光的电场振动方向。
如果电场沿水平方向振动,我们叫它水平偏振。
如果电场沿垂直方向振动,我们叫它垂直偏振。
这两个方向刚好可以拿来表示一个量子比特的两个基本状态:
水平偏振 H → |0⟩
垂直偏振 V → |1⟩
于是,一个光子的偏振态就可以写成:
|ψ⟩ = α|H⟩ + β|V⟩
如果把 |H⟩ 叫作 |0⟩,把 |V⟩ 叫作 |1⟩,它就变成我们熟悉的形式:
|ψ⟩ = α|0⟩ + β|1⟩
这就是光量子比特。
注意,这里说的是单个光子。
日常生活里,我们通常看到的是一束光。比如手电筒发出很多很多光子,太阳光更是大量光子的集合。可是量子计算里的一个量子比特,对应的是一个可控制的量子系统。用光子做例子时,就是一个光子。
一个光子可以是水平偏振。
也可以是垂直偏振。
也可以是水平和垂直的叠加。
比如45度偏振,可以写成:
(|H⟩ + |V⟩) / √2
换成量子计算记号,就是:
(|0⟩ + |1⟩) / √2
这就是第三章里的叠加态,现在有了一个可以想象的物理图像。
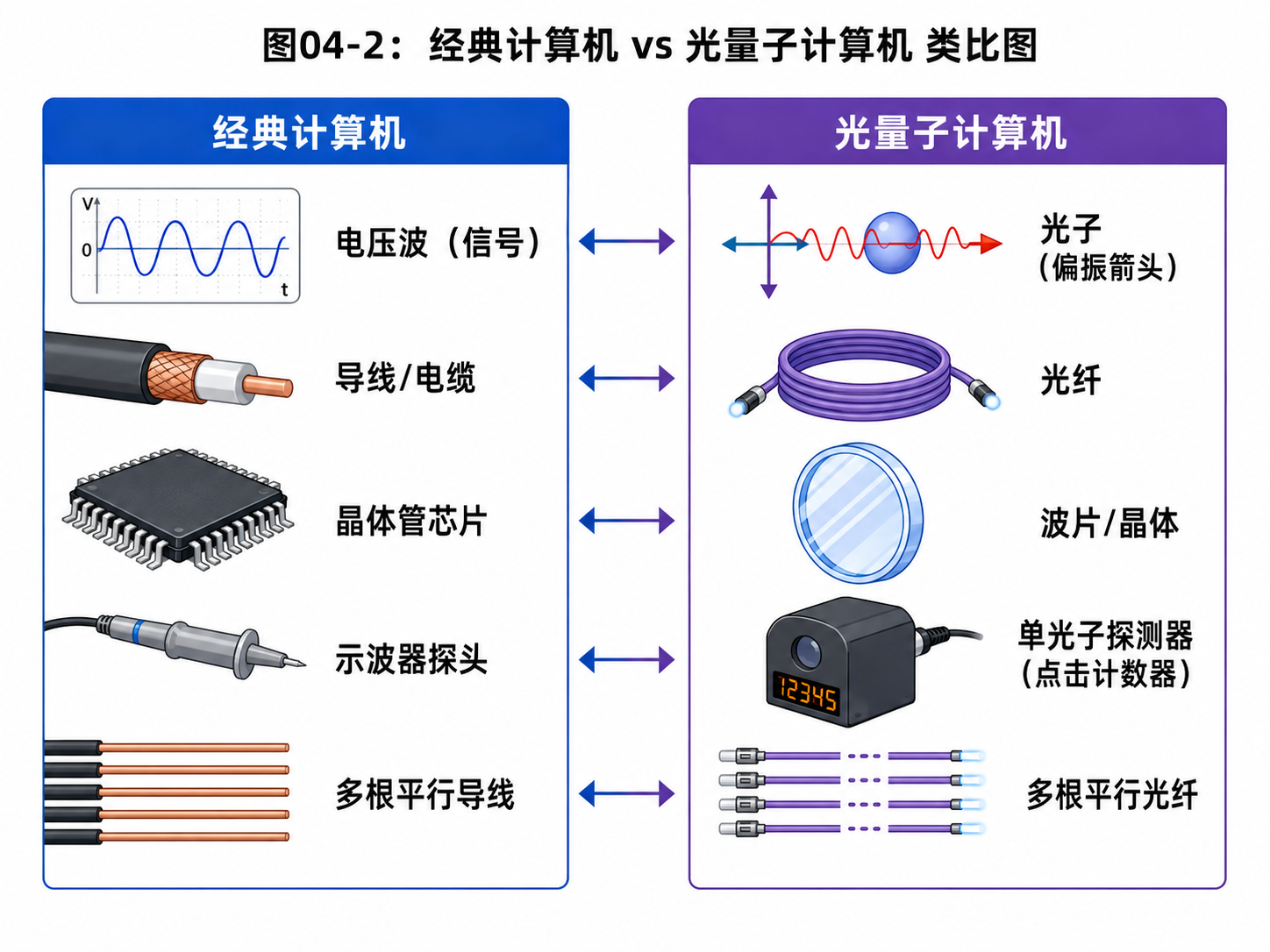
4.2 光路图和电路图怎么对应
如果你习惯了经典计算机,可能会觉得光量子计算的图很陌生。
经典计算机里,我们想象的是导线、晶体管、电压高低。
光量子计算里,我们看到的是光路、偏振片、波片、分束器、探测器。
它们的对应关系可以先这样记:
| 经典计算机 | 光量子计算 |
|---|---|
| 电压高低 | 光子的偏振方向 |
| 导线 | 光路或光纤 |
| 逻辑门 | 波片、分束器等光学器件 |
| 读取电压 | 单光子探测器点击 |
| 多个比特 | 多个光子或多条光路 |
这张表不是严格工程图,只是帮你建立第一层直觉。
在经典电路里,一个比特沿着导线传。
在光量子图像里,一个光子沿着光路走。
经典门插在导线上,改变电信号。
波片插在光路上,改变光子的偏振。
最后,经典电路可以测电压。
光量子实验可以用探测器检测光子走到了哪条路径。
所以,量子线路图上的一条线,在光量子实现里可以想成一条光路。一个门,可以想成某个光学器件放在光路上。
这样看,量子门就不是纯数学符号了。
它可以是一个真实装置。
光子穿过它,状态就改变了。
4.3 制备:先把光子准备到指定状态
量子计算的第一步是制备。
所谓制备,就是把量子比特准备到算法需要的初始状态。
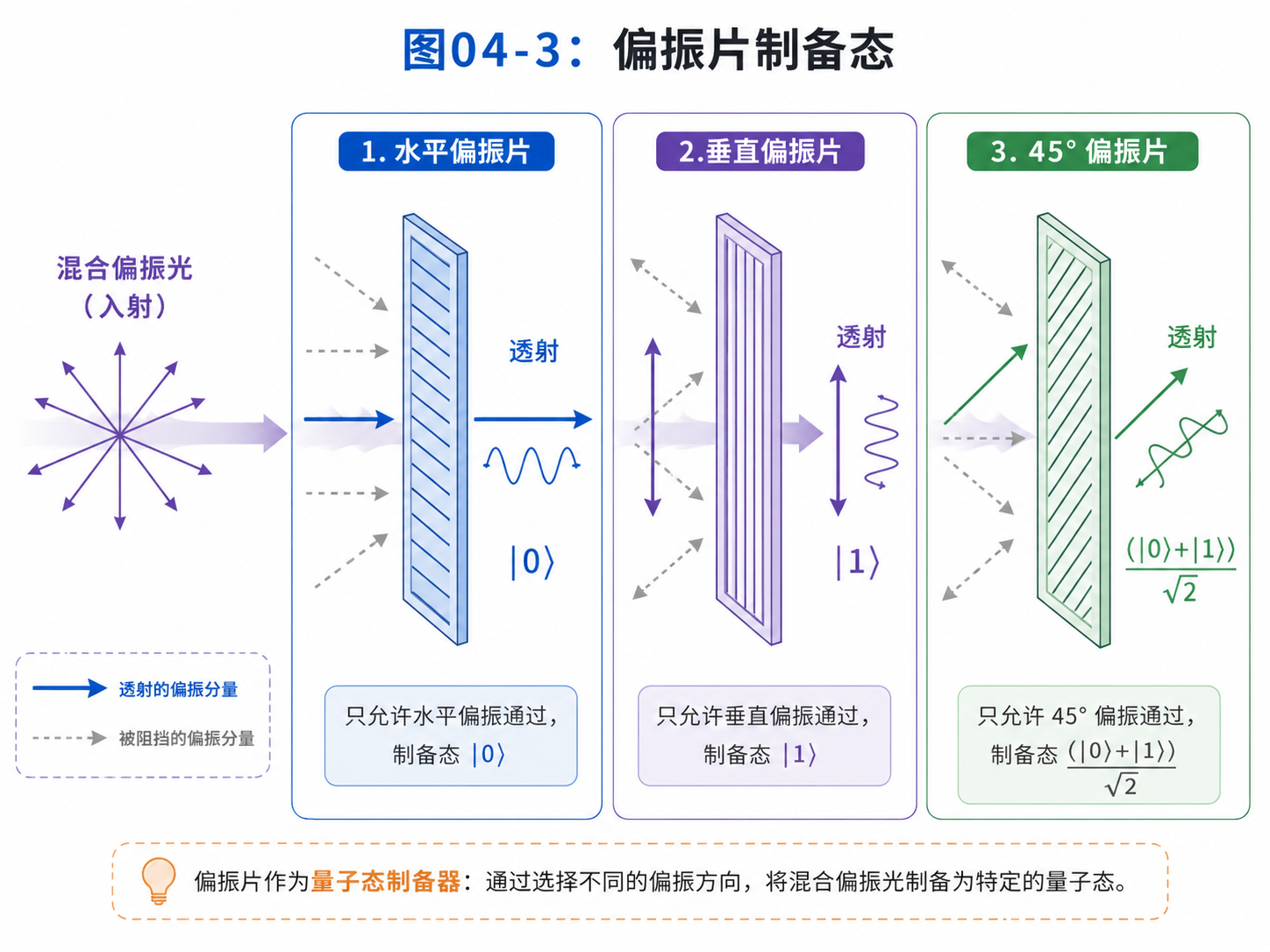
如果用光子做量子比特,制备就是准备光子的偏振。
先看最简单的状态。
如果我们要制备 |0⟩,也就是水平偏振,可以让光子通过水平偏振片。
通过之后,这个光子的偏振就是水平的。
如果要制备 |1⟩,也就是垂直偏振,就换成垂直偏振片。
如果要制备45度叠加态,就用45度方向的偏振片,或者先制备水平偏振,再用波片把偏振方向转过去。
这里有一个容易混淆的地方。
日常经验里,偏振片像是在“过滤”一束光。
比如太阳光通过偏振墨镜以后变暗了。
但在单光子图像里,我们更关心的是:通过偏振片之后的那个光子,处在什么状态。
如果一个光子通过了水平偏振片,它就被准备成水平偏振态。
也就是说,偏振片既可以看成过滤器,也可以看成制备器。
在量子计算里,我们更常从制备的角度看它。
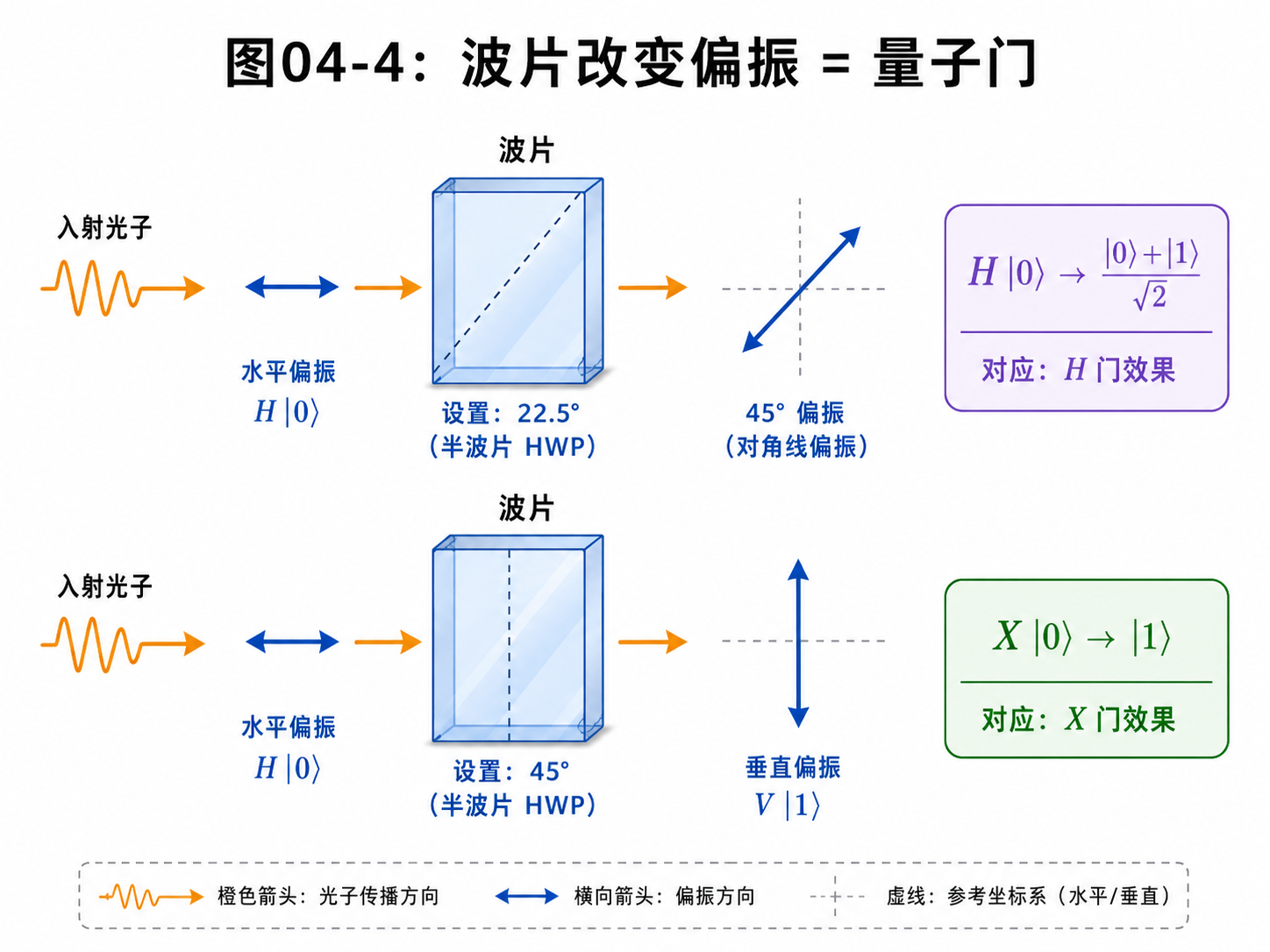
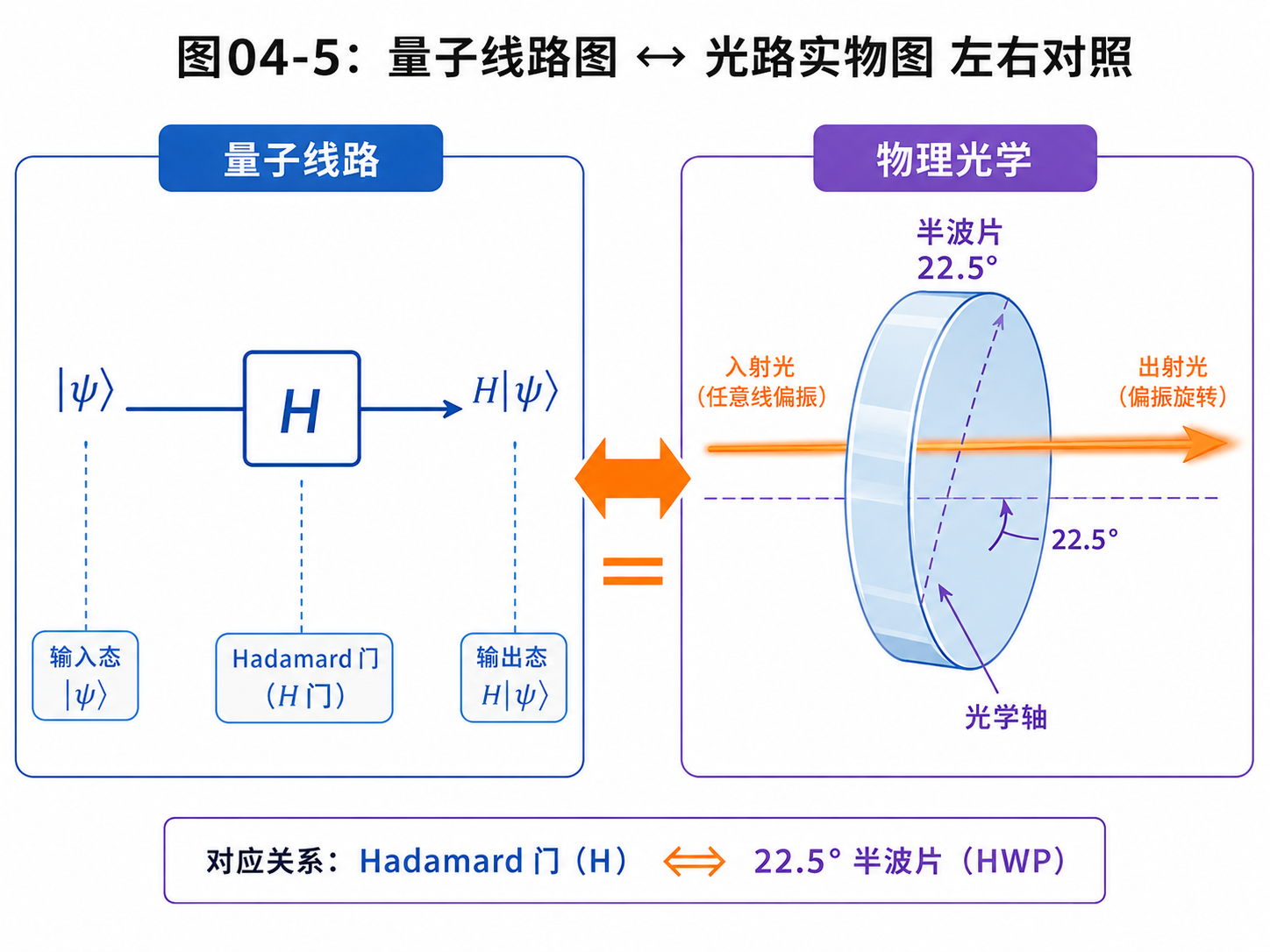
4.4 波片:用光学器件实现量子门
制备好量子比特以后,下一步是操作它。
对光量子比特来说,操作偏振最常见的器件是波片。
你可以先把波片理解成一种“旋转偏振方向”的器件。
光子穿过波片以后,偏振会发生变化。
这和量子门非常像。
量子门作用在量子态上,让状态从一个方向变到另一个方向。
波片作用在光子的偏振上,让偏振从一个方向变到另一个方向。
比如 X门。
X门要把 |0⟩ 和 |1⟩ 对调。
在偏振语言里,就是把水平偏振变成垂直偏振,把垂直偏振变成水平偏振。
某些角度的半波片就可以做到类似效果。
再比如 H门。
H门可以把 |0⟩ 变成平均叠加:
H|0⟩ = (|0⟩ + |1⟩) / √2
在偏振语言里,就是把水平偏振变成45度偏振。
半波片放在合适角度时,就可以实现这个效果。
所以,前面抽象的 H门,在光学桌上可以对应一个具体器件。
当然,真实光学实现会有细节:波片类型、光轴角度、相位差、实验误差。作为入门,我们先抓住核心图像:
波片改变偏振,就像量子门改变量子态。
这已经足够支撑后面的直觉。
4.5 测量:偏振分束器和探测器
量子计算的最后一步是测量。
在光量子比特里,最直观的测量方式是:
偏振分束器 + 两个单光子探测器
偏振分束器常简称 PBS。
它的作用是按偏振把光分开。
水平偏振的光走一条路。
垂直偏振的光走另一条路。
于是,如果我们在两条路末端各放一个探测器,就可以知道这个光子被测成了水平偏振,还是垂直偏振。
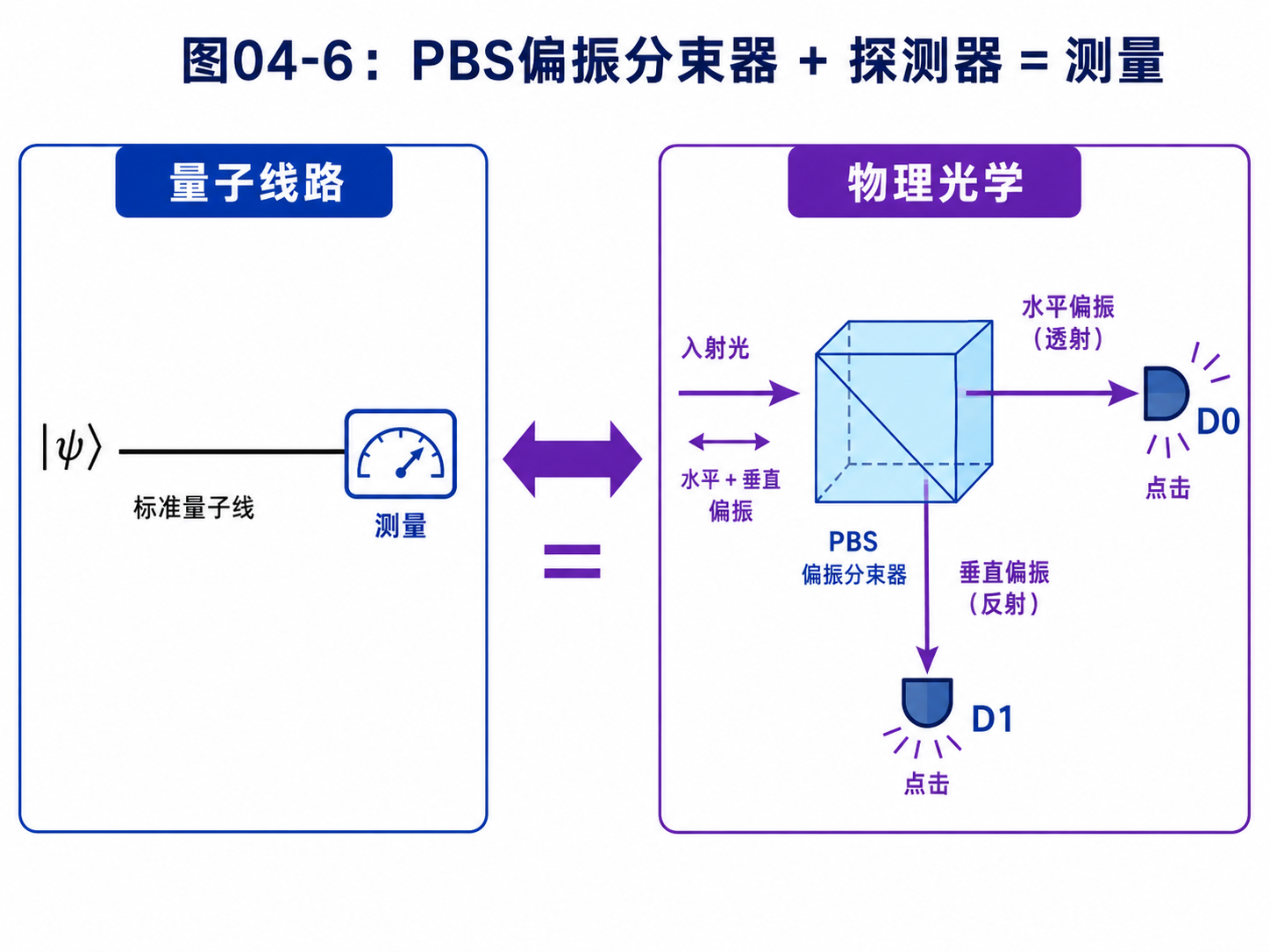
如果水平那边的探测器点击,就记作测到 |0⟩。
如果垂直那边的探测器点击,就记作测到 |1⟩。
这就是测量。
如果光子原本就是水平偏振,它一定走水平路径。
如果光子原本就是垂直偏振,它一定走垂直路径。
但如果光子原本是:
(|H⟩ + |V⟩) / √2
也就是45度偏振,那么情况就变成概率性的。
有一半概率,水平探测器点击。
有一半概率,垂直探测器点击。
每次实验只会点击一个探测器。
不会两个一起点击。
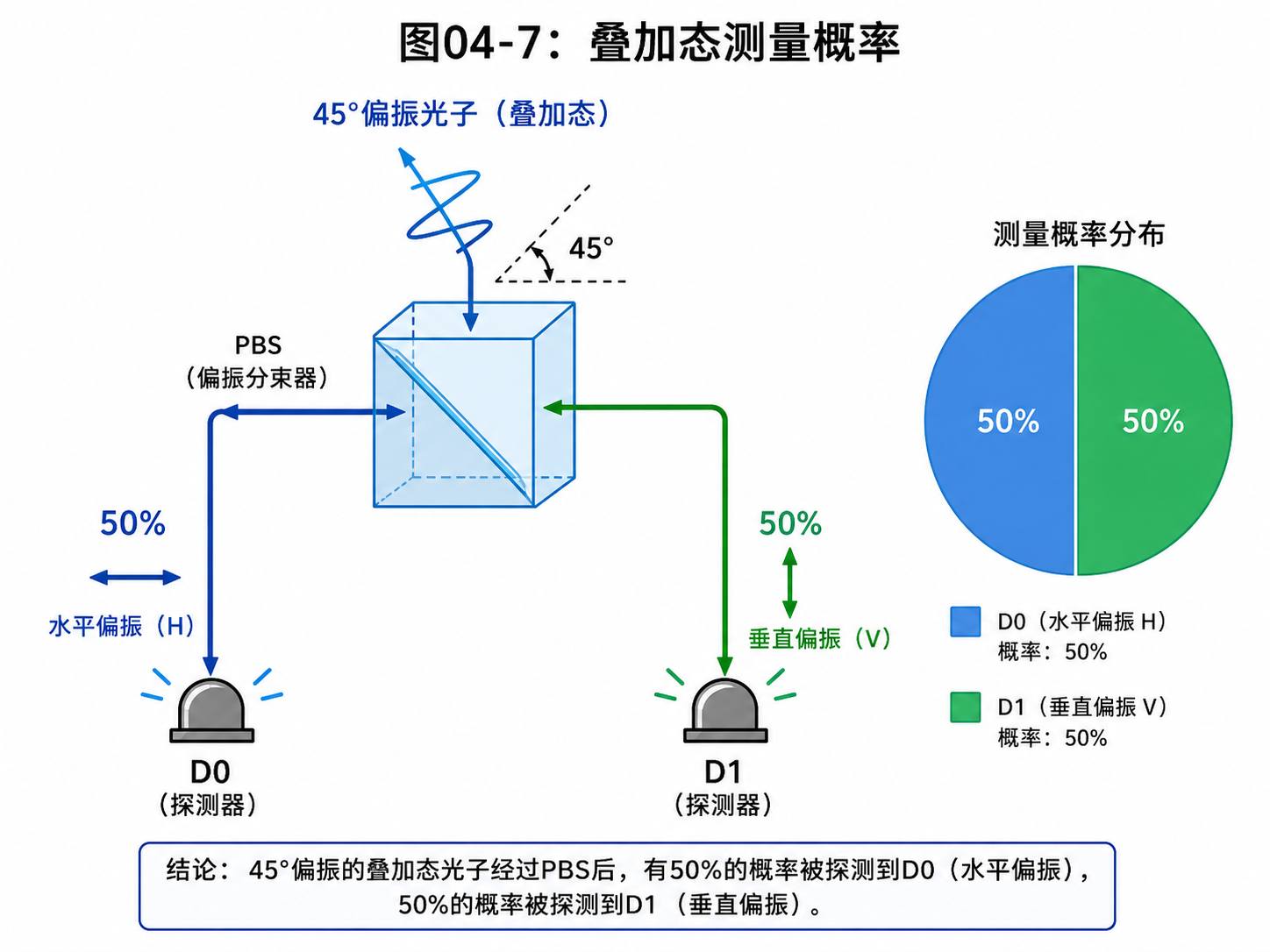
这就是第零章说过的:测量会把叠加态压成一个经典结果。
4.6 测量为什么会丢信息
现在我们用光子的例子再看一次测量。
假设一个光子处在45度偏振:
(|H⟩ + |V⟩) / √2
它到达 PBS。
最后水平探测器点击。
你知道了什么?
你知道这次测量结果是水平偏振。
但你不知道测量前的完整状态。
因为很多不同的输入状态,都可能在某次测量中给出水平结果。
比如水平偏振一定给水平结果。
45度偏振有一半概率给水平结果。
其他某些偏振态也可能给水平结果。
所以一次测量不能告诉你原来状态里的全部振幅和相位。
更重要的是,测量之后,原来的状态已经被改变了。
如果探测到水平结果,后续你就只能把它当成水平偏振处理。
这就是为什么量子计算不能靠“多看几眼”读出完整量子态。
想知道一个未知量子态,通常需要反复制备很多份相同状态,再做统计。可对于一次具体计算过程中的那个量子态,你不能复制出来慢慢看。
这也解释了第三章里说的调试困难。
经典程序可以中途打印变量。
光量子线路里,如果你中途放一个探测器看一眼,光子就被测掉了,后面的计算也就改变了。
4.7 多个光子:多量子比特从哪里来
一个光子可以表示一个量子比特。
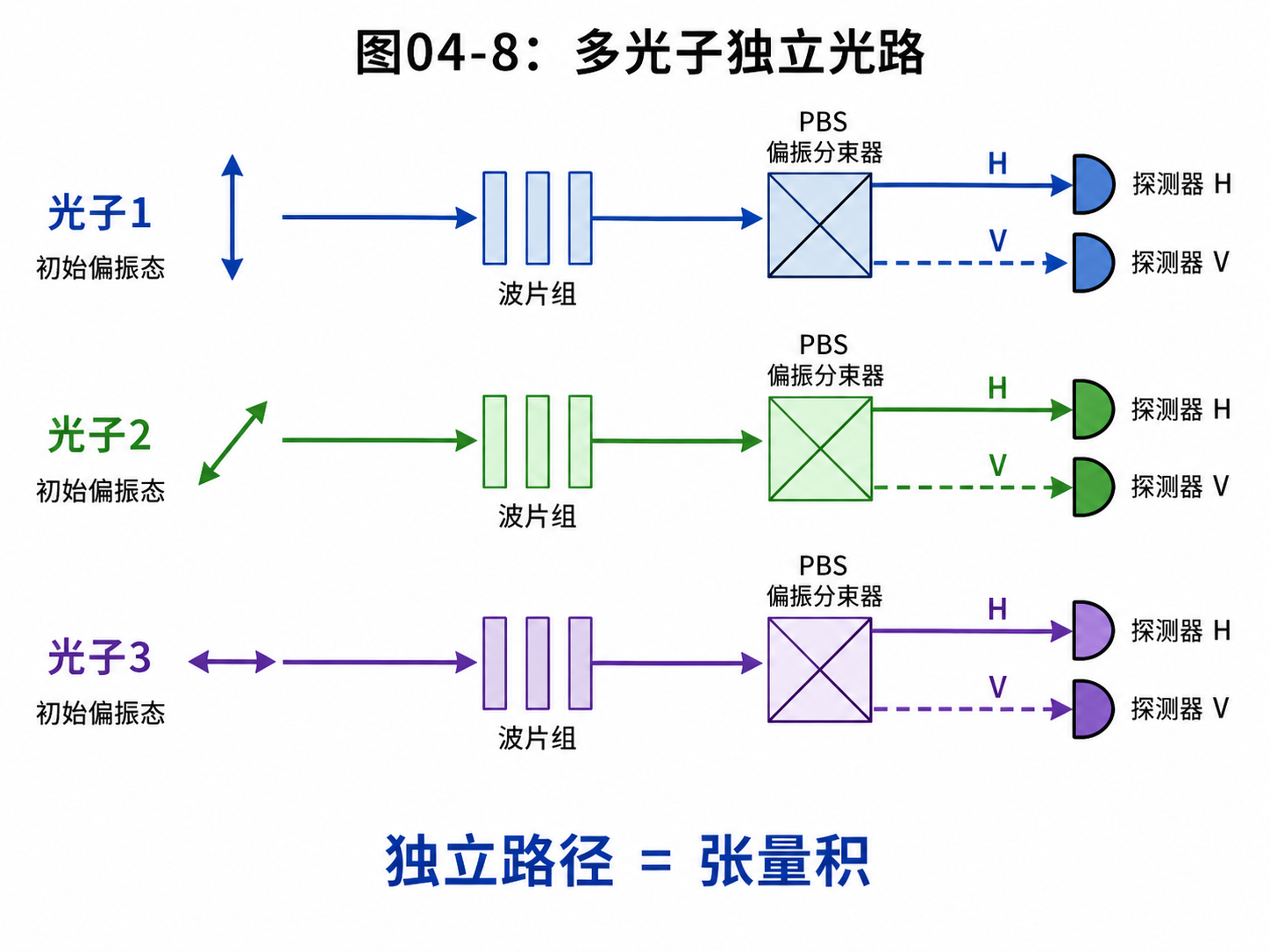
那么多个量子比特怎么办?
最直接的想法是:多个光子。
第一个光子表示第一个量子比特。
第二个光子表示第二个量子比特。
第三个光子表示第三个量子比特。
每个光子可以走自己的光路。
如果它们只是各自独立,那么整个状态就是各自状态的组合。
比如第一个光子是水平偏振,第二个光子是垂直偏振,就可以写成:
|H⟩|V⟩
也就是量子计算记号里的:
|0⟩|1⟩ = |01⟩
如果第一个光子处在叠加态,第二个光子也处在叠加态,那么整体状态会展开成四个分量。
这就是张量积在物理图像中的样子。
多个光子放在一起,不只是“多个小球排队”。它们的整体状态需要放在一个更大的状态空间里描述。
如果这些光子之间出现纠缠,情况就更有意思。
例如:
(|HH⟩ + |VV⟩) / √2
换成量子比特记号,就是:
(|00⟩ + |11⟩) / √2
这表示两个光子的偏振必须作为整体描述。你不能只看第一个光子就说清全部状态。
这样的纠缠光子对,在实验中可以通过一些特殊过程产生,比如自发参量下转换。这个名词先不用深入,只要知道:在光量子实验里,纠缠光子对是真实可以制备出来的。
4.8 光量子的优点和困难
用光子讲量子计算,有很多优点。
第一,直观。
偏振方向、偏振片、波片、分束器,都比“抽象希尔伯特空间”更容易想象。
第二,光子不太容易和环境发生强相互作用。
这意味着它比较不容易退相干。简单说,光子在传播过程中比较能保持自己的量子状态。
第三,光子很适合传输。
光纤通信本来就是现代信息技术的重要部分,所以用光子传递量子信息也很自然。
但光量子也有一个大困难:
光子之间不太容易相互作用。
这对双量子比特门很麻烦。
单量子比特门比较容易。你放一块波片,就能改变一个光子的偏振。
但双量子比特门需要两个量子比特发生有效关联。对光子来说,这件事不容易,因为两个光子通常只是擦肩而过,不会强烈影响彼此。
所以,光量子计算在原理教学上非常清楚,但在工程上有自己的难题。
这也提醒我们:量子计算的数学规则是统一的,但物理实现可以有很多路线。
光量子是一条路线。
超导量子比特是一条路线。
离子阱是一条路线。
半导体量子点也是一条路线。
不同路线的硬件不同,但它们都要实现同一套基本循环:
制备 → 演化 → 测量
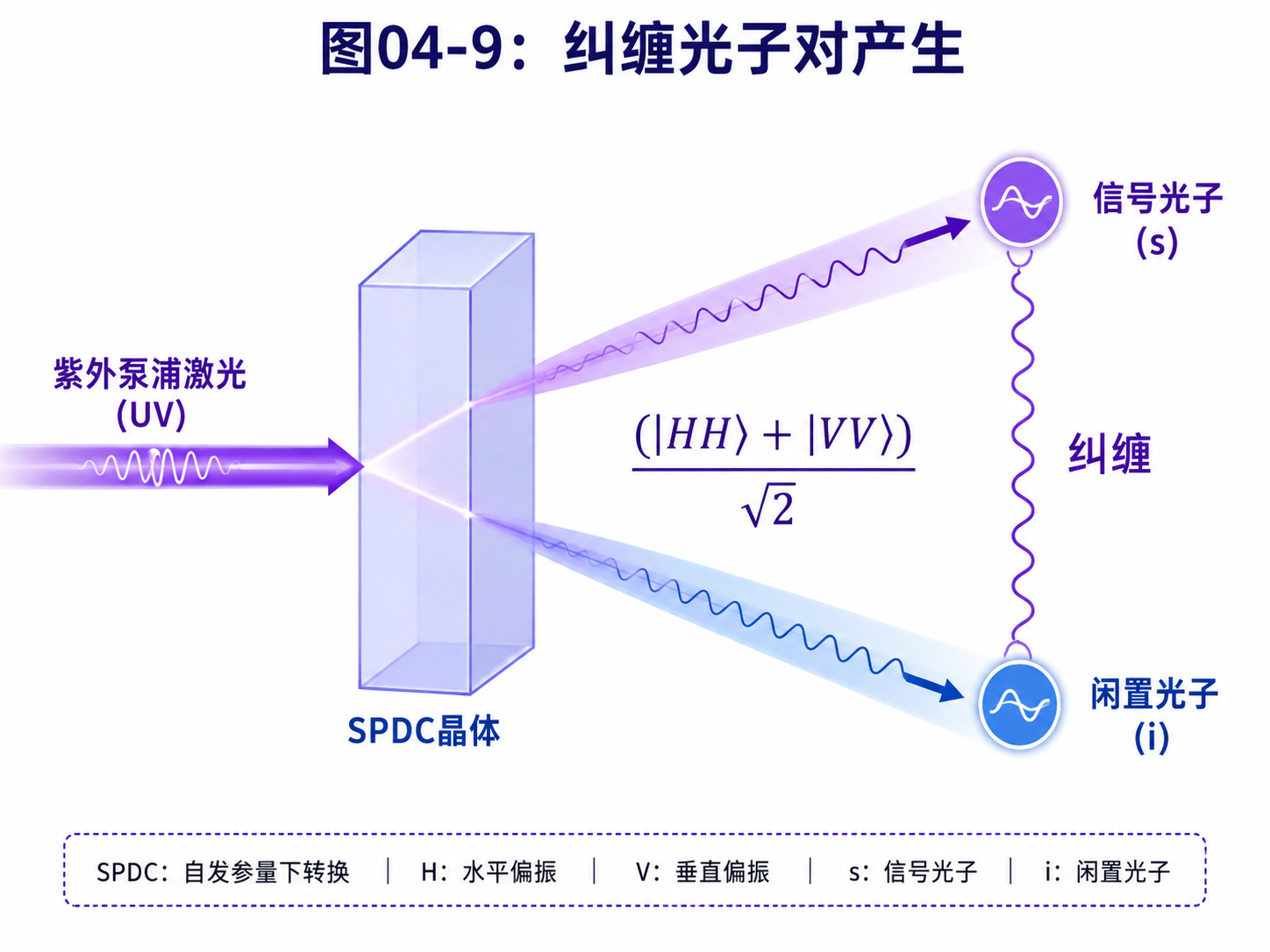
4.9 本章小结:把符号落到光路上
本章做了一件事:把前面抽象的量子比特、量子门和测量,放到光子的例子里。
我们看到:
一个光子的水平偏振和垂直偏振,可以表示 |0⟩ 和 |1⟩。
45度偏振,可以表示 (|0⟩ + |1⟩)/√2 这样的叠加态。
偏振片可以用来制备状态。
波片可以用来改变量子态,相当于实现某些单量子比特门。
偏振分束器加探测器,可以用来测量。
多个光子可以表示多个量子比特。
纠缠光子对可以展示两个量子比特不能拆开描述的整体状态。
这章的重点不是让你成为光学实验专家,而是帮你建立一个物理直觉:
量子计算不是纸上公式。它必须落在真实物理系统上。
下一章,我们会回到量子计算本身,讨论一个核心问题:叠加到底带来了什么?为什么n个量子比特会对应 2ⁿ 个振幅?为什么这听起来像并行,但又不能简单理解成“免费得到所有答案”?
第五章 叠加与量子并行性
上一章,我们把量子比特放进了光路里。
一个光子可以水平偏振,也可以垂直偏振。
如果换成量子计算的记号,它就像是在 |0⟩ 和 |1⟩ 之间取状态。
当这个光子处在 45 度偏振时,它又不是简单的 |0⟩,也不是简单的 |1⟩,而是两个可能性的叠加。
这件事看起来不大。
一个量子比特,只是从“0 或 1”变成了“0 和 1 的叠加”。
但一旦量子比特的数量增加,它的力量就会迅速变得惊人。
本章要讨论的问题是:
叠加到底给量子计算带来了什么?
先说结论。
n 个量子比特不是只带着 n 个数。
它们要用 2ⁿ 个振幅来描述。
量子门作用在这些量子比特上时,会改变这一整组振幅。
这就是人们常说的“量子并行性”的来源。
但这里一定要慢一点。
量子并行性不是“免费得到所有答案”。
测量的时候,我们仍然只能看到一个结果。
如果只会制造叠加,却不会安排干涉,那么最后读出来的很可能只是一个随机结果。
真正有用的量子算法,必须做三件事:
- 先把状态展开。
- 再让所有振幅一起变化。
- 最后用干涉把有用信息凸显出来。
这一章先把前两步讲清楚,同时提前说明第三步为什么重要。
下一章的 Deutsch 算法,会把这三步第一次完整串起来。
5.1 从一个量子比特到多个量子比特
先从最小的情况开始。
一个经典比特只能是 0 或 1。
一个量子比特可以写成:
α|0⟩ + β|1⟩
这里有两个基底态:|0⟩ 和 |1⟩。
也有两个振幅:α 和 β。
如果你暂时不想管希腊字母,可以把它理解成:
这个量子比特带着两个可能性的权重
这些权重不是普通概率。
它们是振幅。
振幅可以有方向,可以互相加强,也可以互相抵消。
这一点后面会变得非常重要。
现在加到两个量子比特。
两个经典比特的状态,可以是下面四种之一:
00
01
10
11
两个量子比特的状态,则可以是这四种基底态的叠加:
α00|00⟩ + α01|01⟩ + α10|10⟩ + α11|11⟩
为了少写下标,我们也可以暂时只看意思:
第一个振幅 对应 |00⟩
第二个振幅 对应 |01⟩
第三个振幅 对应 |10⟩
第四个振幅 对应 |11⟩
这时,系统不再只需要两个振幅,而是需要四个振幅。
再加到三个量子比特。
三个经典比特一共有八种可能状态:
000
001
010
011
100
101
110
111
三个量子比特的一般状态,要给这八种基底态各配一个振幅。
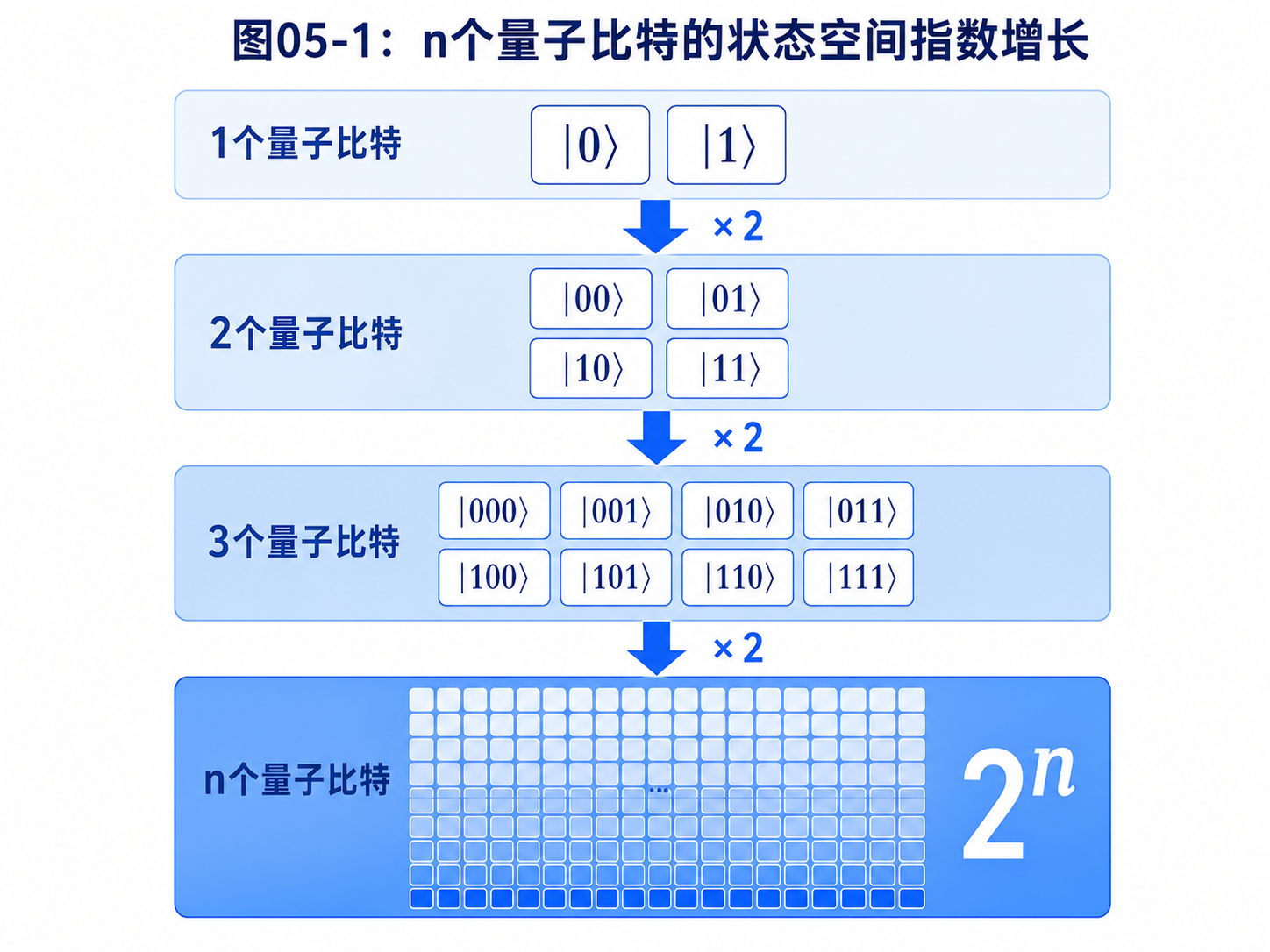
规律已经很清楚了:
1 个量子比特 -> 2 个基底态 -> 2 个振幅
2 个量子比特 -> 4 个基底态 -> 4 个振幅
3 个量子比特 -> 8 个基底态 -> 8 个振幅
n 个量子比特 -> 2ⁿ 个基底态 -> 2ⁿ 个振幅
这就是指数增长。
指数增长的意思是,每多一个量子比特,基底态的数量就翻一倍。
不是多一个,不是多十个,而是直接乘以 2。
10 个量子比特,需要 2¹⁰ = 1024 个振幅。
20 个量子比特,需要 2²⁰ 个振幅,差不多是一百万个。
30 个量子比特,需要 2³⁰ 个振幅,已经超过十亿个。
50 个量子比特,需要 2⁵⁰ 个振幅,大约是一千万亿个。
如果到 300 个量子比特,2³⁰⁰ 会大到难以想象。
它甚至超过我们通常估计的宇宙中原子数量。
这就是量子计算让人兴奋的第一层原因:
很少的量子比特,可以对应极大的状态空间。
但“对应极大的状态空间”还不等于“已经完成了计算”。
这一点非常重要。
你可以想象一本有很多页的书。
叠加让这本书一下子有了很多页。
可是,如果你最后只能随便翻开一页,那并不代表你已经读完了整本书。
量子计算的难点,不是把书页变多。
难点是让正确的那一页更容易被翻到。
5.2 叠加不是很多经典状态排队
在继续讲量子门之前,我们先澄清一个直觉问题。
很多人第一次听到叠加,会把它想成这样:
量子计算机同时开了很多条经典分支
每条分支各算一个答案
最后把所有答案拿出来
这个想法很诱人,但它不准确。
如果量子计算真的只是“很多经典机器同时工作”,那它就只是并行计算的一种特别说法。
我们只要堆更多芯片、更多线程、更多服务器,就能模仿它。
但量子叠加不是很多经典状态排队。
它是一个整体状态。
两个量子比特的叠加态:
α00|00⟩ + α01|01⟩ + α10|10⟩ + α11|11⟩
不是四台小机器分别站在四个格子里。
它更像是一张整体的波形图。
四个振幅一起描述同一个系统。
如果你改变其中一个量子比特,通常会影响整张图的形状。
如果你测量它,整张图也会被压缩成一个结果。
上一章的光子例子可以帮我们建立直觉。
45 度偏振的光子,不是“半个水平光子加半个垂直光子”。
它就是一个完整的光子,只是它的偏振状态可以用水平和垂直两个方向的叠加来描述。
同样,多个量子比特的叠加,也不是很多个经典世界各自独立运行。
它是一个需要用很多振幅来描述的整体状态。
这个区别会影响我们对“并行”的理解。
经典并行像是很多人同时做题。
每个人手里有一张纸,最后可以把所有纸收上来。
量子并行更像是在调整一张复杂的波形。
你不能把每一部分单独拿出来读。
你只能通过合适的操作,让某些波峰变高、某些波峰变低,最后再测量。
所以,量子并行的核心不是“分身很多个自己”。
核心是:
一个量子系统的整体状态,包含了大量振幅;量子门可以同时改变这些振幅。
5.3 量子门:一次改变整组振幅
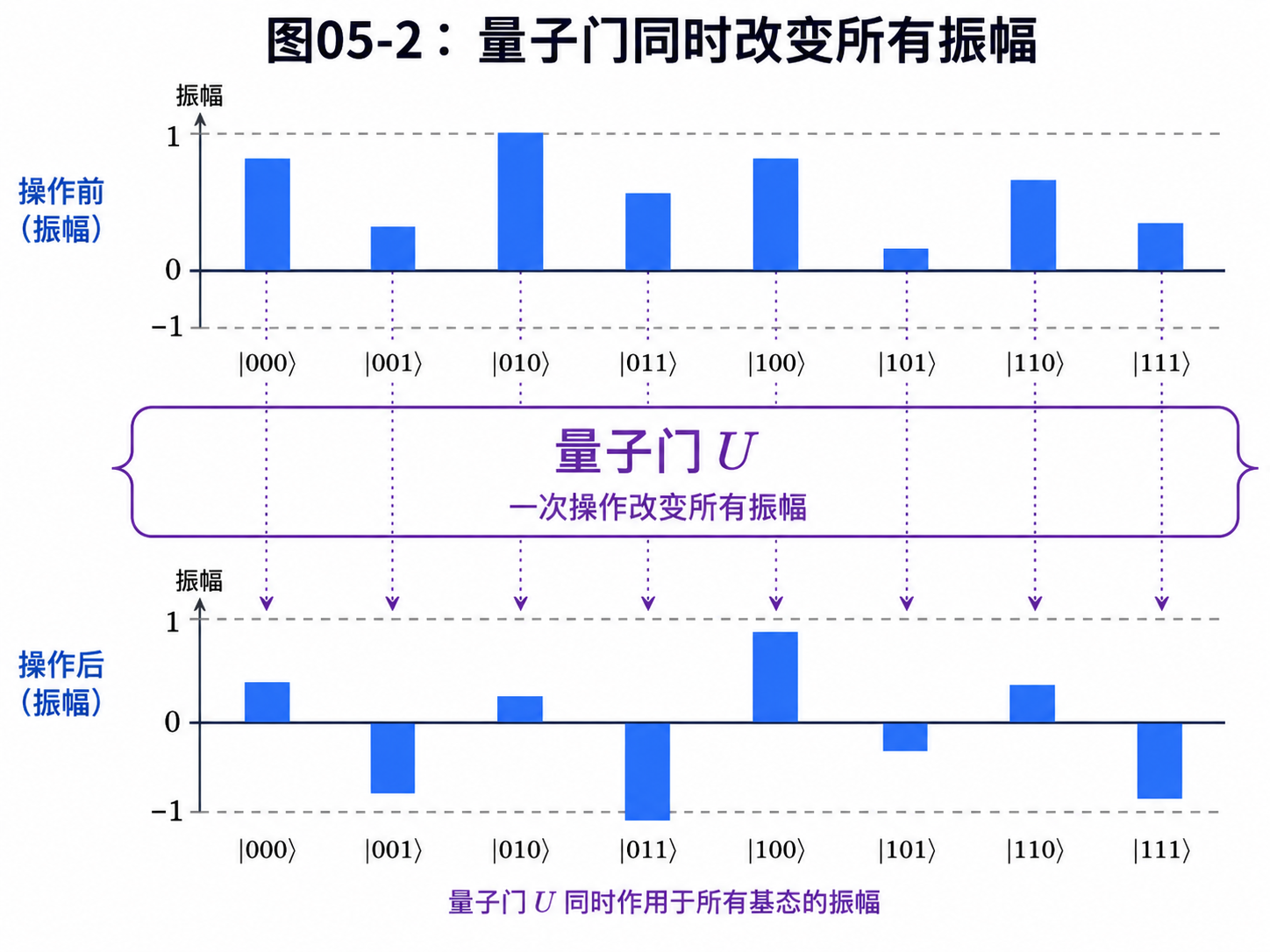
有了叠加态之后,下一步就是操作它。
经典计算里,门作用在比特上。
比如 NOT 门把 0 变成 1,把 1 变成 0。
量子计算里,量子门作用在量子态上。
它改变的不是一个孤立的数字,而是一组振幅。
我们先看最熟悉的 Hadamard 门。
在一个量子比特上,它的作用可以简单记成:
H|0⟩ = (|0⟩ + |1⟩)/√2
H|1⟩ = (|0⟩ - |1⟩)/√2
也就是说,Hadamard 门可以把一个确定的基底态变成叠加态。
如果我们从两个量子比特的 |00⟩ 开始,并且对两个量子比特都做 Hadamard 操作,会发生什么?
第一步,对第一个量子比特做 Hadamard。
|00⟩ -> (|00⟩ + |10⟩)/√2
意思是:
第一个量子比特从 |0⟩ 展开成 |0⟩ 和 |1⟩ 的叠加。
第二个量子比特暂时还是 |0⟩。
第二步,对第二个量子比特也做 Hadamard。
(|00⟩ + |10⟩)/√2
会变成:
(|00⟩ + |01⟩ + |10⟩ + |11⟩)/2
现在,四个基底态都出现了。
每一个的振幅都是 1/2。
测量时,每个结果的概率都是振幅绝对值的平方,也就是 1/4。
这就是最简单的均匀叠加。
如果是 n 个量子比特,全都从 |0⟩ 开始,然后每个都做一次 Hadamard,就会得到所有 2ⁿ 个基底态的均匀叠加。
写成一句话就是:
H 作用在每个量子比特上
可以把 |00...0⟩ 展开成所有 0/1 串的叠加
这听起来就很像“同时准备了所有输入”。
在某种意义上,这个说法有帮助。
因为后面的量子门确实会作用在整组振幅上。
比如我们有一个量子操作,它根据输入改变相位。
当输入处在所有 0/1 串的叠加中时,这个操作就会给每个基底态对应的振幅做相应改变。
但请注意:
它改变的是振幅,不是把每个答案打印出来。
你不能在中途偷看每个输入算出了什么。
一偷看,叠加态就被测量破坏了。
这也是上一章说过的调试困难。
经典程序可以中途打印变量。
量子程序不能随便这么做。
因为你要利用的是整个叠加态的演化,而不是某一条单独路径。
5.4 经典并行和量子并行有什么不同
“并行”这个词很容易引起误会。
如果你学过计算机,听到并行,可能会想到多核 CPU、GPU、线程、集群。
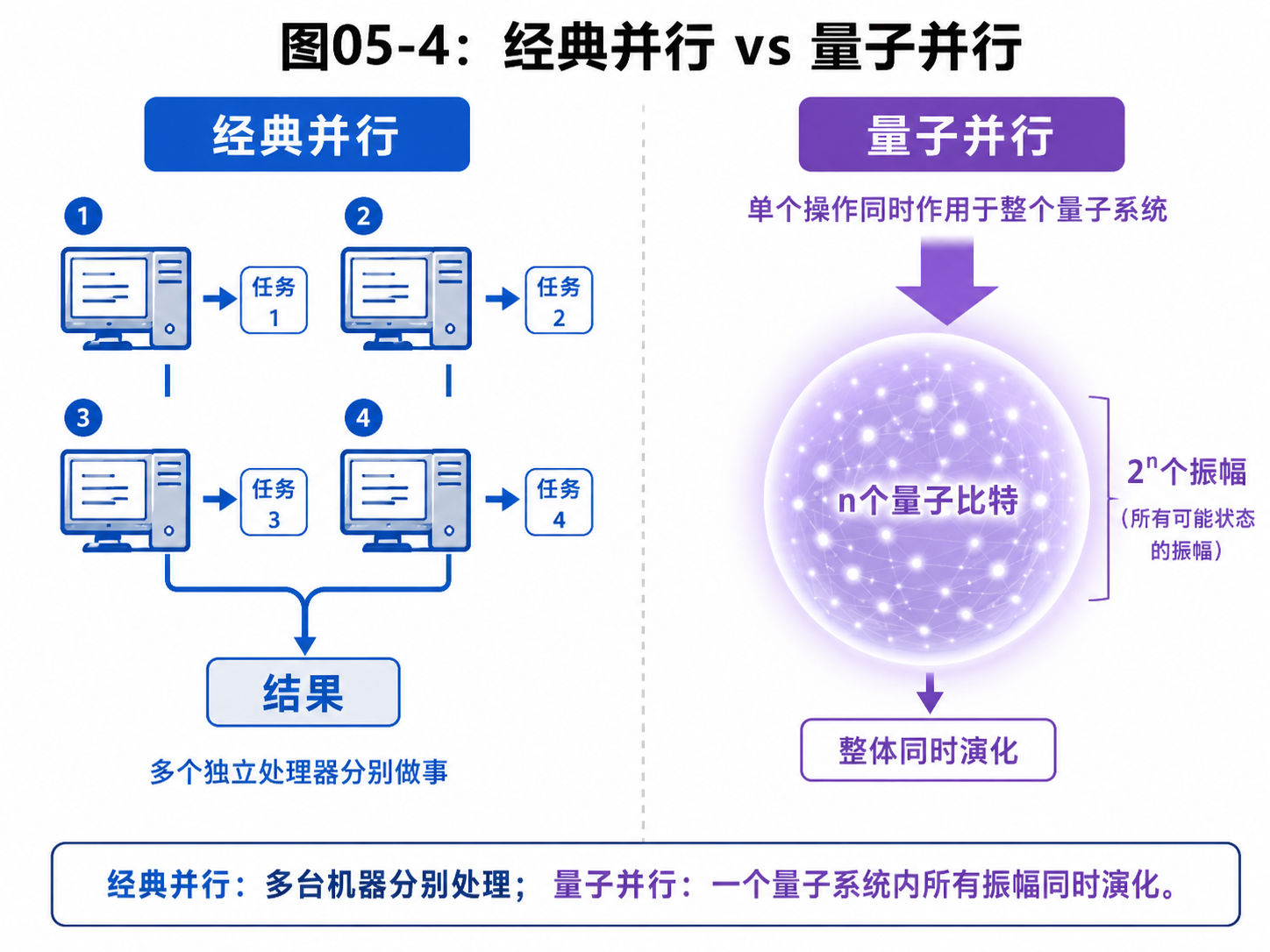
这些都是经典并行。
经典并行的基本思路是:
任务很多 -> 多放一些机器 -> 每台机器做一部分
比如要检查一百万个密码。
一台机器从第一个开始试。
十台机器就可以把任务分成十份。
一千台机器就可以分成一千份。
这是非常有用的技术。
现代计算离不开它。
但它的增长方式是加硬件。
你想多处理十倍的任务,通常就要接近十倍的资源。
量子并行不是这样。
它不是把很多机器摆在一起。
它是让 n 个量子比特的状态空间自己展开成 2ⁿ 个振幅。
然后,量子门作为一个整体变换,改变这一整组振幅。
可以做一个简单对照:
经典并行:
更多硬件 -> 更多计算通道 -> 多个结果可以分别读出
量子并行:
更多量子比特 -> 更大的状态空间 -> 振幅整体演化,最后只能测到一个结果
这两者各有优势,也各有边界。
经典并行很稳定,很容易检查中间结果。
你可以把每台机器算出的东西都存下来。
如果某一台机器坏了,也不会立刻改变其他机器的结果。
量子并行更微妙。
它可以在很大的状态空间里做整体变换。
但它不能把所有分量逐个读出来。
它还会受到退相干、噪声和测量的影响。
所以,不要把量子计算理解成“更大规模的 GPU”。
它不是在同一条路上跑得更快。
它是在用另一种方式组织信息。
在经典计算里,信息通常像一串清楚的符号。
在量子计算里,信息更像一组会相互影响的振幅。
经典并行的关键问题是:
我能不能安排更多工人同时做事?
量子并行的关键问题是:
我能不能设计一组操作,让振幅的变化最终指向答案?
这就是量子算法和普通并行程序的根本区别。
5.5 测量:为什么不能免费得到所有答案
现在我们来到最容易误解的地方。
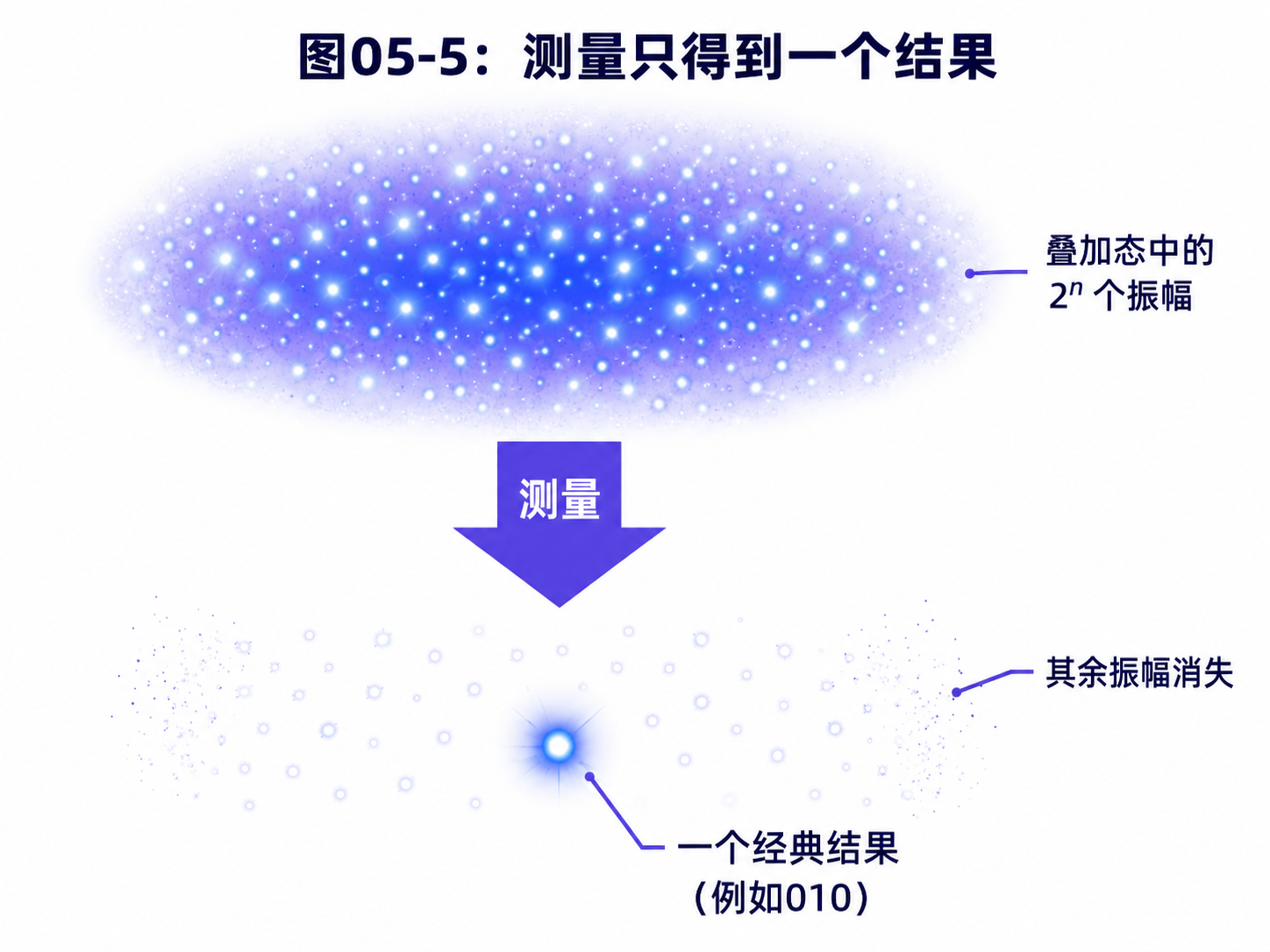
既然 n 个量子比特有 2ⁿ 个振幅,而且量子门会同时改变它们,那我们能不能最后一次性读出所有结果?
不能。
原因很简单:
测量只能给出一个结果。
如果一个三量子比特系统处在八个基底态的叠加中,测量时不会把八个结果都交给你。
它只会给你其中一个,比如:
010
或者:
111
具体得到哪个结果,取决于各个振幅对应的概率。
某个基底态的振幅越大,它被测到的可能性越高。
振幅越小,被测到的可能性越低。
如果所有结果的概率都一样,那测量就像是在均匀抽签。
你只是随机拿到其中一个。
这没有什么神奇优势。
比如你把 20 个量子比特展开成一百多万个基底态的均匀叠加。
如果你什么都不做,直接测量。
结果只是从一百多万个字符串里随机抽一个。
这当然不等于你知道了一百多万个答案。
所以,量子算法的目标从来不是“制造一个很大的叠加,然后直接测量”。
那样只会得到随机数。
真正的目标是:
让错误答案的振幅变小
让正确答案的振幅变大
最后测量时更容易得到正确答案
这件事靠的就是干涉。
5.6 干涉:把有用信息推到前台
上一章说光子时,我们已经接触过一点“波”的感觉。
光可以叠加。
波峰和波峰遇到,会变得更强。
波峰和波谷遇到,会互相抵消。
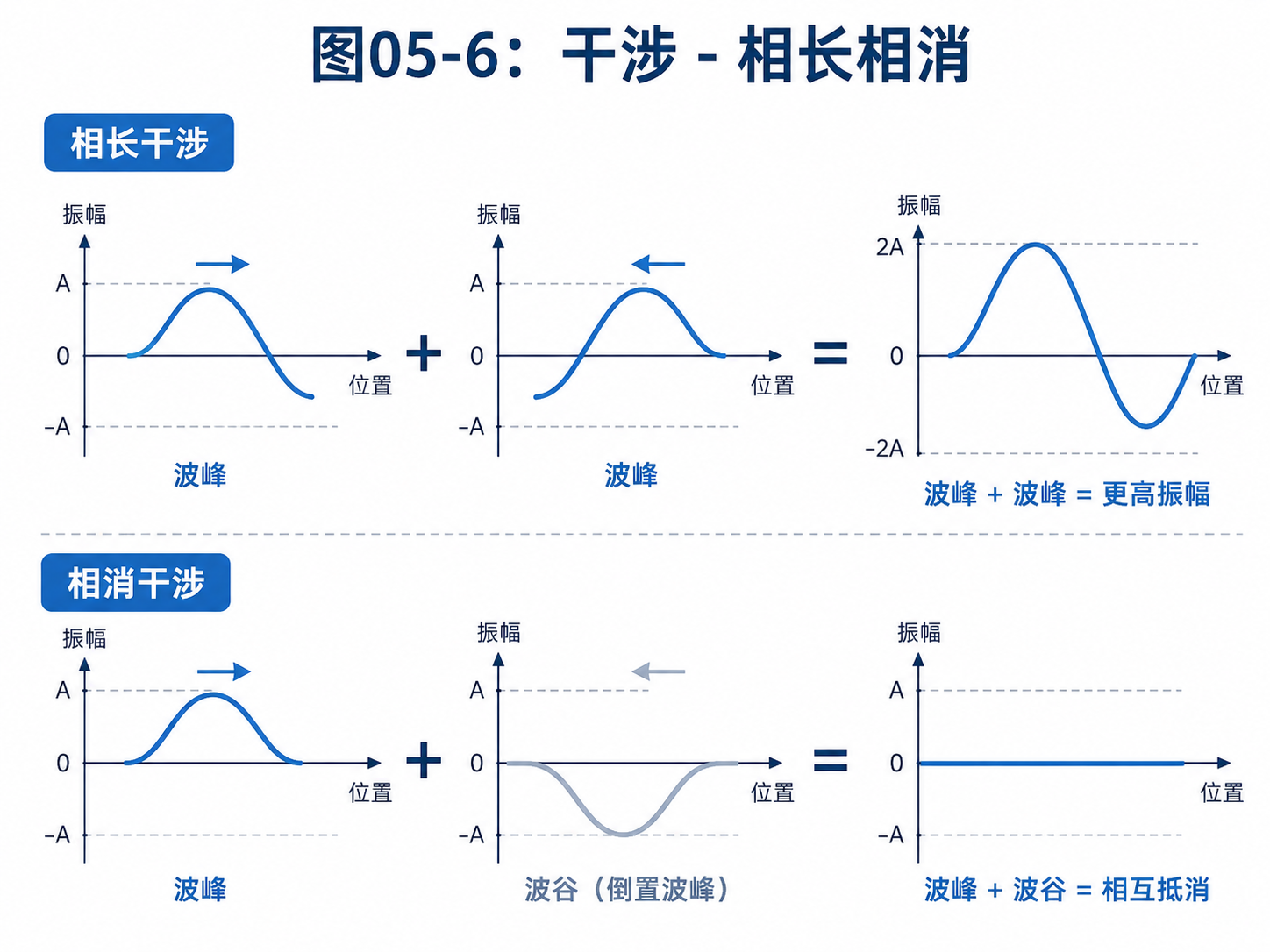
量子振幅也有类似的特点。
如果两条路径对同一个结果贡献了同方向的振幅,它们会相长。
结果的概率会变大。
如果两条路径对同一个结果贡献了相反方向的振幅,它们会相消。
结果的概率会变小,甚至变成零。
这就是量子干涉。
量子算法真正厉害的地方,不只是“状态很多”。
而是能安排这些状态的振幅互相作用。
你可以把它想成一次很精细的排练。
开始时,舞台上站满了人。
这对应叠加。
接着,每个人按照规则移动位置、改变方向。
这对应量子门的整体变换。
最后,灯光只照亮某些位置。
观众最容易看到的,就是那些被推到亮处的人。
这对应干涉后再测量。
这个比喻当然不完全精确。
但它提醒我们一点:
叠加只是把可能性展开。
干涉才负责把有用的可能性推到前台。
如果没有干涉,量子并行就只是一大片看不清的可能性。
有了干涉,量子算法才有机会把隐藏的信息读出来。
第六章的 Deutsch 算法会给出一个非常小的例子。
它只处理一个看起来简单的问题:
一个函数是常量函数,还是平衡函数?
经典计算至少要问两次。
量子算法只问一次。
这不是因为量子计算机偷偷把两个答案都打印出来。
而是因为它把两个输入放进叠加里,让函数作用在整个叠加态上,再用干涉把“常量”或“平衡”这个分类信息变成可测量的结果。
这就是本章要为下一章铺好的台阶。
5.7 量子并行性的三个层次
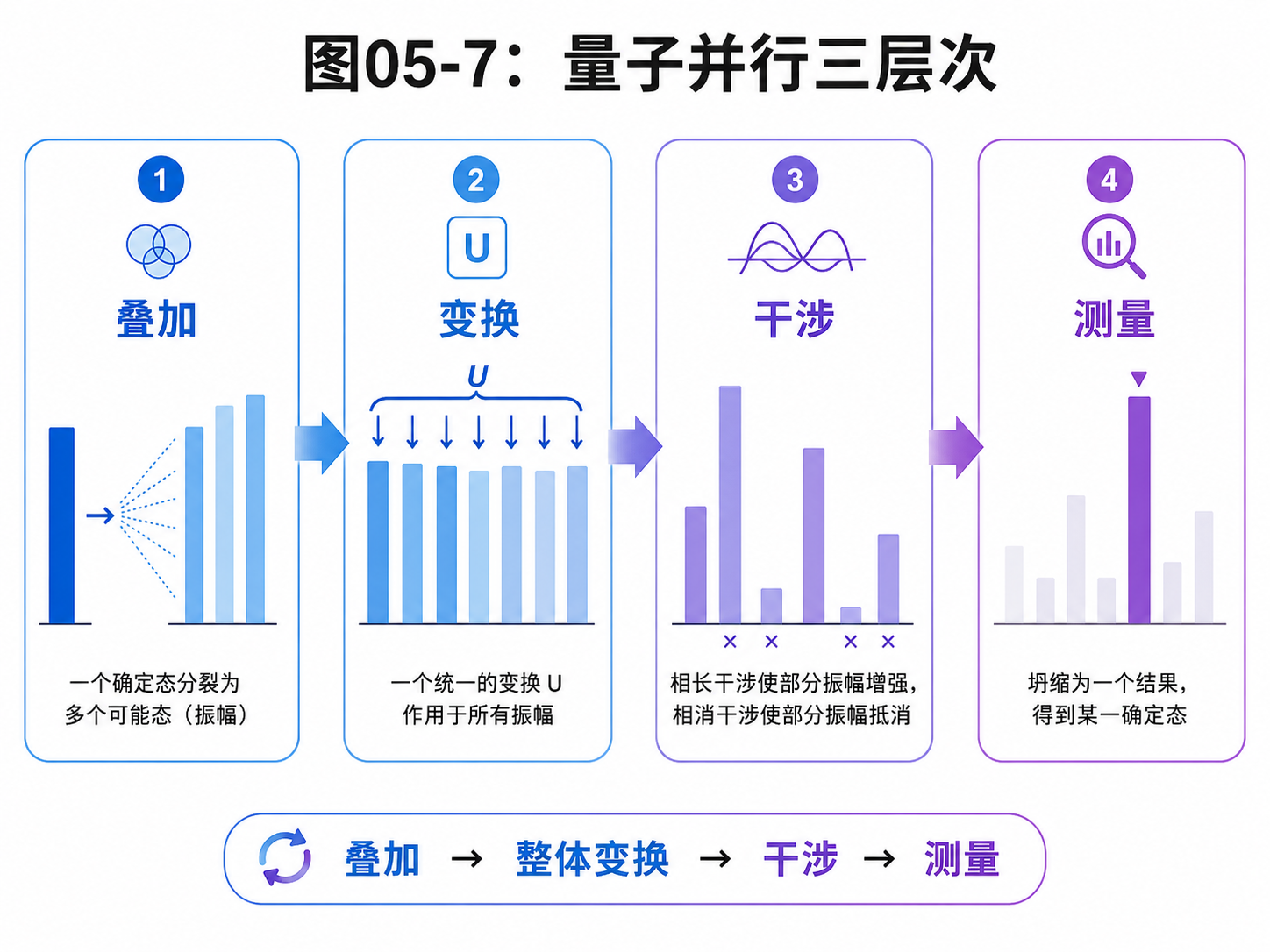
现在可以把本章的内容压缩成三层。
第一层:叠加。
n 个量子比特可以带着 2ⁿ 个振幅。
这给量子计算提供了巨大的状态空间。
没有叠加,就没有这个容量。
第二层:变换。
量子门不是只改一个振幅。
它按照线性规则改变整组振幅。
当状态已经展开成很多基底态的叠加时,一个量子操作会影响这一整组分量。
这就是量子并行性的直接来源。
第三层:干涉。
测量只能给出一个结果。
所以,算法必须让振幅先发生有目的的加强和抵消。
正确方向的振幅要变大,错误方向的振幅要变小。
这样测量才更可能得到有用信息。
三层缺一不可:
没有叠加,就没有大状态空间。
没有整体变换,就没有量子并行。
没有干涉,就无法从并行中提取答案。
这也解释了为什么量子算法不好设计。
在经典程序里,你通常可以一步一步写:
先算 A
再算 B
如果满足条件,就输出 C
在量子程序里,你必须更像是在设计一段波的演化:
先展开
再写入信息
再安排干涉
最后测量
中间任何一步安排不好,测量都可能只给你一个没有意义的随机结果。
所以,量子计算不是“把经典算法放进叠加态里就自动加速”。
它需要专门的算法结构。
这就是为什么我们接下来要学 Deutsch 算法。
它很小,甚至小到不像一个真正的实用算法。
但它第一次清楚展示了量子算法的基本骨架:
叠加 -> 整体变换 -> 干涉 -> 测量
理解了这个骨架,再看后面的 Grover 搜索、Shor 分解、量子模拟,就不会只看到一堆公式。
你会知道它们都在做同一类事情:
让振幅以正确的方式流动,最后把答案推到最容易被测到的位置。
5.8 本章小结:大空间不等于全答案
本章讨论了量子计算里一个最有吸引力、也最容易被误解的概念:量子并行性。
我们从一个量子比特开始。
一个量子比特需要两个振幅描述。
两个量子比特需要四个振幅。
三个量子比特需要八个振幅。
n 个量子比特需要 2ⁿ 个振幅。
这说明量子系统的状态空间增长得极快。
接着,我们看到量子门会作用在整个量子态上。
当量子态已经展开成很多基底态的叠加时,量子门会改变整组振幅。
这就是量子并行性的基础。
但我们也反复强调:
量子并行不是免费读出所有答案。
测量只能给出一个结果。
如果没有精心安排干涉,最后得到的就只是随机抽样。
因此,一个真正有用的量子算法,不只是制造叠加。
它必须让正确答案的振幅变大,让错误答案的振幅变小。
这就是干涉的作用。
到这里,我们已经有了进入第六章的全部准备:
叠加提供容量
量子门提供整体变换
干涉负责提取信息
测量给出最终结果
下一章,我们会用 Deutsch 算法看见这条路线第一次完整运行。
它会告诉我们:量子计算的优势不是玄学,也不是“同时偷看所有答案”,而是把信息藏进振幅,再通过干涉把它读出来。
第六章 Deutsch 算法:量子优势的第一个证明
前一章,我们把量子并行性拆成了三层:
叠加 -> 整体变换 -> 干涉 -> 测量
这条线如果只停留在文字上,还是有点抽象。
所以本章要看第一个完整的量子算法:Deutsch 算法。
它解决的问题很小。
小到你可能会觉得:“这有什么用?”
但它的重要性不在于实用价值,而在于它第一次清楚地展示了量子算法的基本结构:
经典计算必须问两次
量子计算只问一次
这个“问”,指的是向一个黑盒函数查询。
经典计算一次只能查一个输入。
量子计算可以把输入放进叠加里,让一次查询同时影响多个振幅。
然后,算法再用干涉把我们想要的分类信息读出来。
注意这里的说法:
不是“量子计算一次拿到了所有答案”。
而是“一次查询让两个答案都参与了振幅变化,最后我们只读出需要的那一点信息”。
这正好接住第五章的核心提醒:
大状态空间不等于全答案。干涉才是把有用信息提出来的关键。
6.1 问题:常数函数还是平衡函数
先介绍问题。
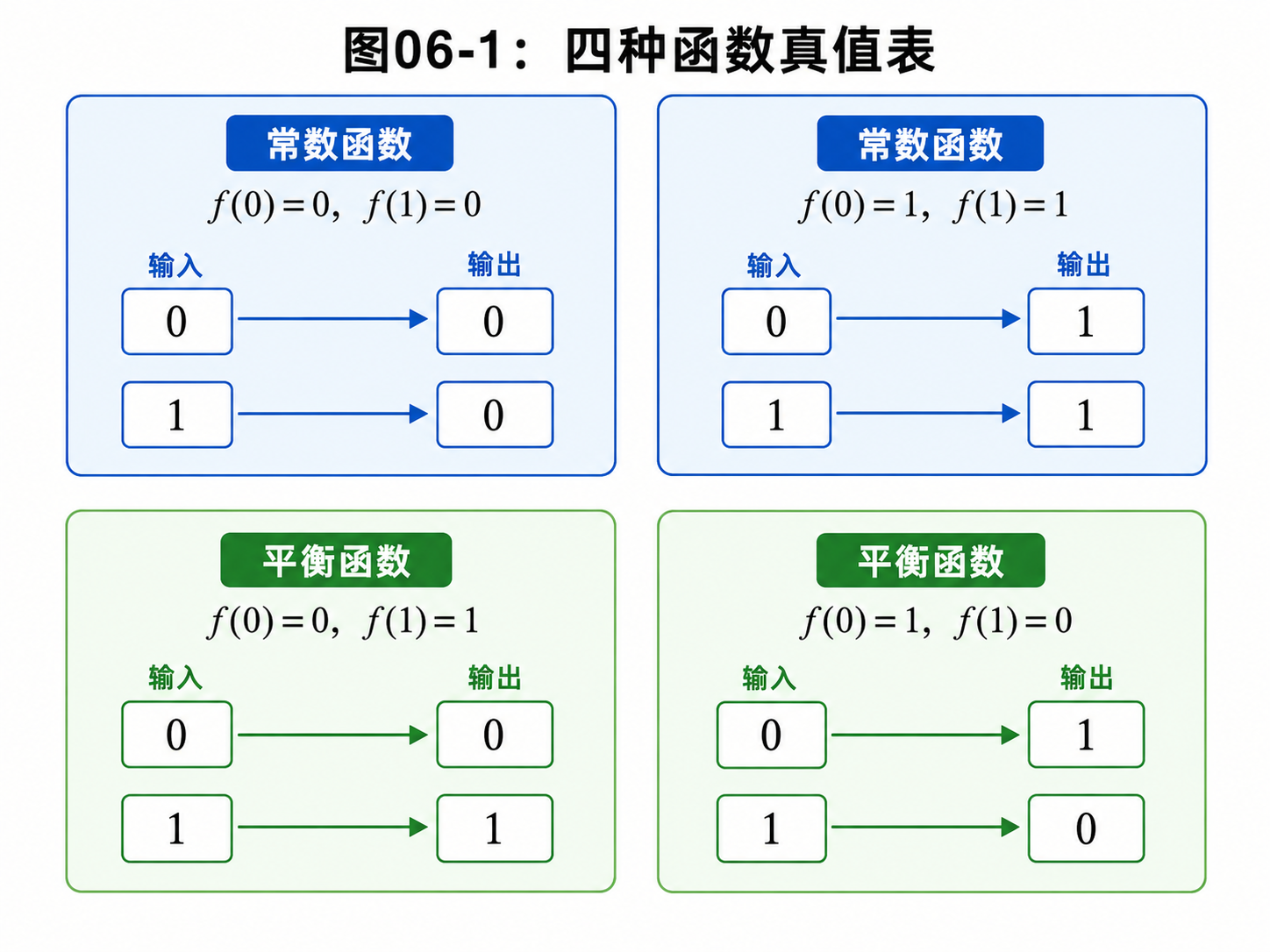
我们有一个函数:
f: {0, 1} -> {0, 1}
这句话的意思是:
输入只能是 0 或 1。
输出也只能是 0 或 1。
因为输入只有两个,输出也只有两个,所以这样的函数一共只有四种。
第一种:
f(0) = 0
f(1) = 0
不管输入是 0 还是 1,输出都是 0。
这叫常数函数。
第二种:
f(0) = 1
f(1) = 1
不管输入是什么,输出都是 1。
这也叫常数函数。
第三种:
f(0) = 0
f(1) = 1
两个输入给出两个不同输出。
这叫平衡函数。
第四种:
f(0) = 1
f(1) = 0
这也是平衡函数。
现在,问题来了。
我们不知道黑盒里面到底是哪一种函数。
我们只能给它一个输入,然后看它返回什么输出。
我们的任务不是找出完整函数表。
任务只是判断:
它是常数函数,还是平衡函数?
这就是 Deutsch 问题。
6.2 经典计算为什么需要两次查询
先看经典做法。
如果你只查询一次,比如只问:
f(0) = ?
假设黑盒回答:
f(0) = 0
这时你能判断它是常数函数还是平衡函数吗?
不能。
因为还有两种可能:
f(1) = 0 -> 常数函数
f(1) = 1 -> 平衡函数
只知道 f(0),完全不够。
如果你只问 f(1),情况也是一样。
你只知道一半信息,另一半仍然未知。
所以经典计算必须问两次:
先查 f(0)
再查 f(1)
然后比较两个值
如果两个值一样,就是常数函数。
如果两个值不同,就是平衡函数。
这里没有技巧可以绕开。
因为经典查询一次只能给你一个输入对应的一个输出。
要比较两个输出,就必须知道两个输出。
这就是经典边界。
Deutsch 算法要展示的,就是量子计算怎样越过这个边界。
6.3 量子黑盒 Uf 是什么
量子算法也要查询这个函数。
但量子计算不能直接使用普通黑盒。
原因在第三章已经讲过:
量子门必须是可逆的。
普通函数 f(x) 可能不可逆。
比如常数函数把 0 和 1 都变成 0。
如果只看到输出 0,你无法知道输入到底是 0 还是 1。
所以量子计算会把函数包装成一个可逆的量子黑盒,记作 Uf。
它有两个输入:
x
y
也有两个输出:
x
y ⊕ f(x)
写成规则就是:
Uf |x⟩|y⟩ = |x⟩|y ⊕ f(x)⟩
这里的 ⊕ 读作“异或”。
它的规则很简单:
0 ⊕ 0 = 0
0 ⊕ 1 = 1
1 ⊕ 0 = 1
1 ⊕ 1 = 0
你可以把它理解成:
如果 f(x) = 0,y 不变
如果 f(x) = 1,y 翻转
为什么这样就可逆?
因为第一个比特 x 被保留下来了。
第二个比特只是根据 f(x) 翻转或不翻转。
如果再做一次同样操作,就能翻回去。
这和第三章讲的可逆门是一条线。
第一个量子比特叫输入比特。
第二个量子比特叫辅助比特。
辅助比特看起来只是帮忙,但在 Deutsch 算法里,它非常关键。
它会让函数值从“普通输出”变成“相位变化”。
这句话先记住。
下面一步一步看。
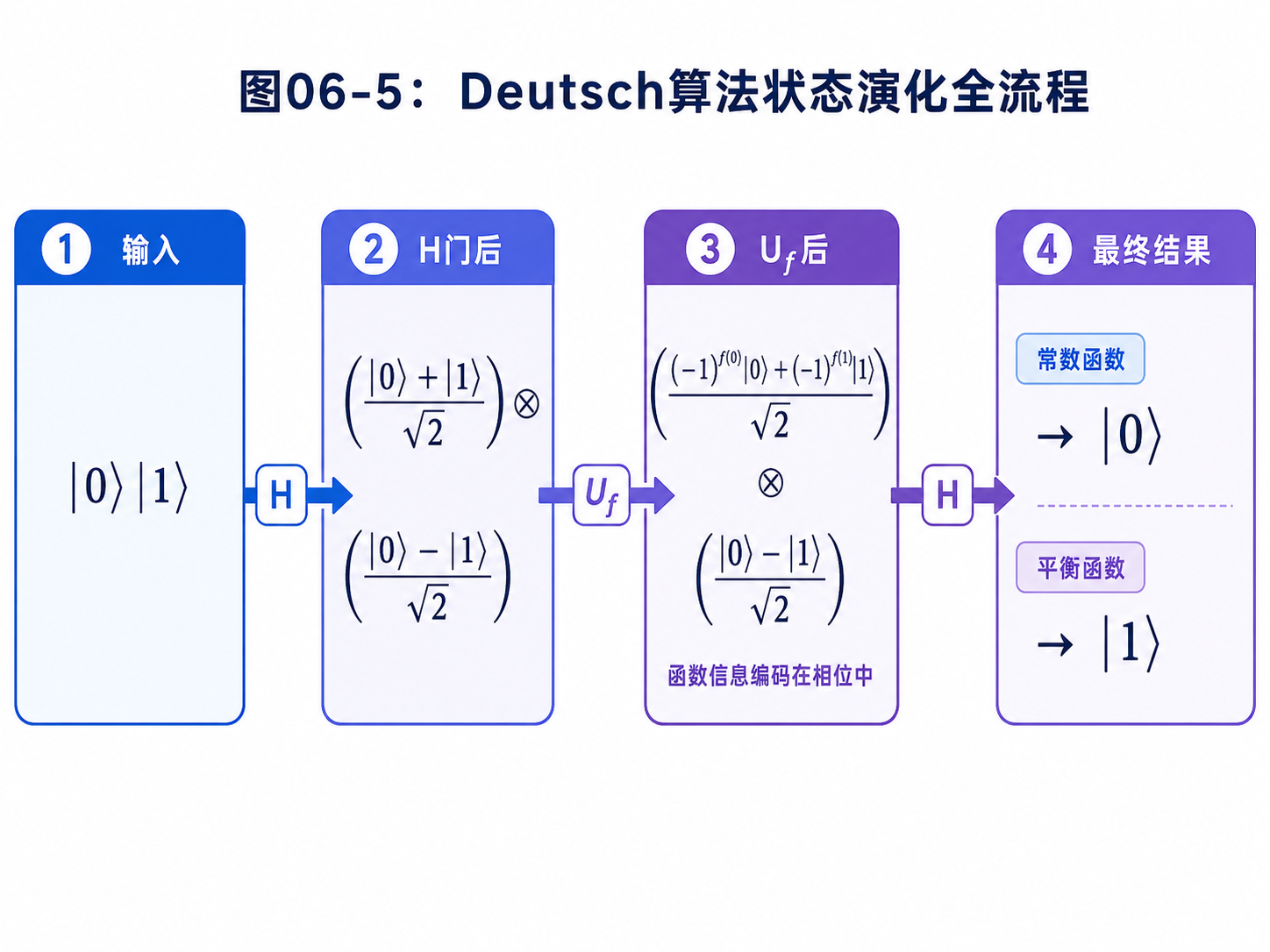
6.4 初始状态:为什么从 |0⟩|1⟩ 开始
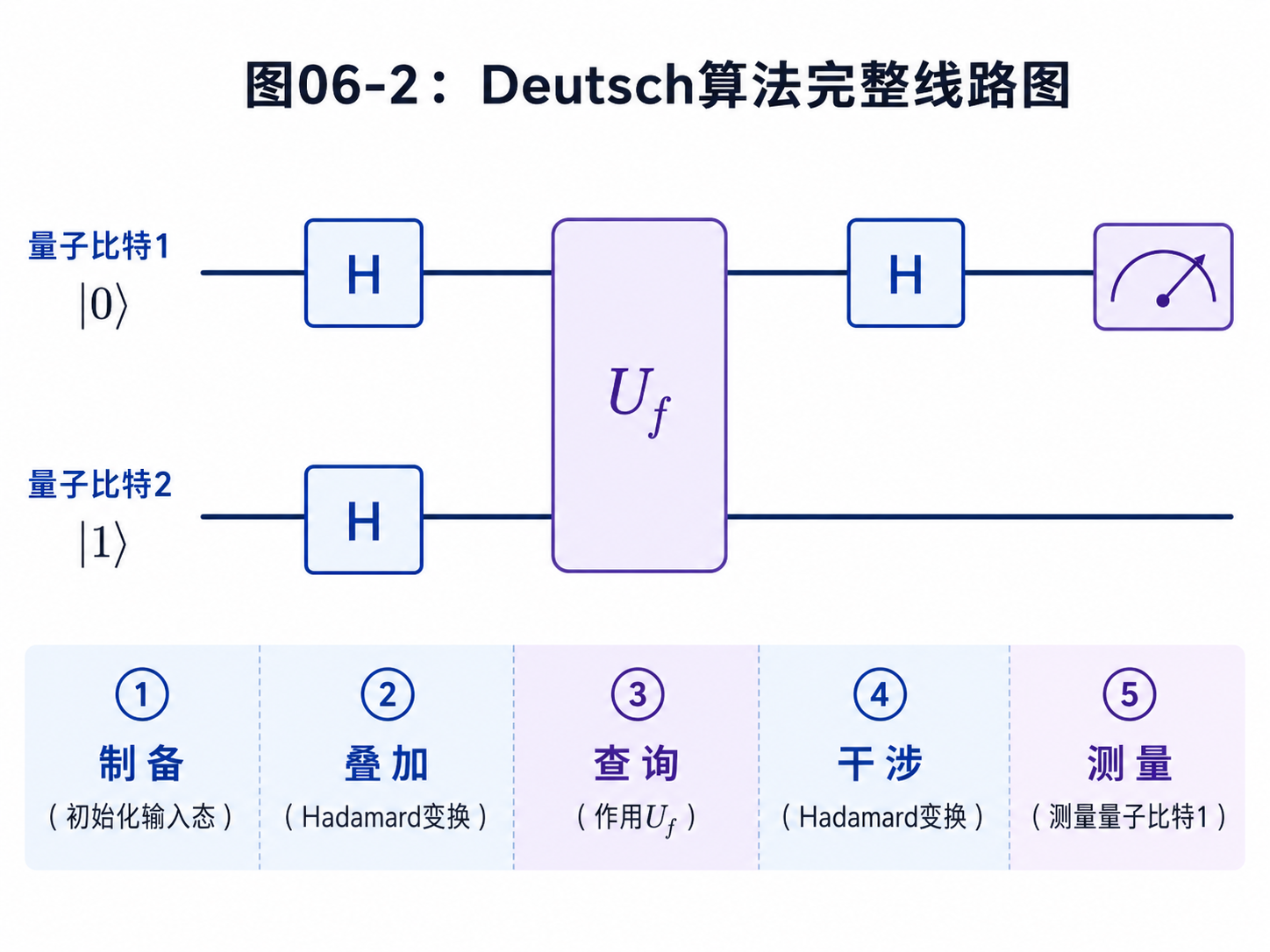
Deutsch 算法使用两个量子比特。
初始状态选成:
|0⟩|1⟩
也可以写成:
|01⟩
第一个量子比特从 |0⟩ 开始。
它后面会被放进 |0⟩ 和 |1⟩ 的叠加里,用来同时代表两个输入。
第二个量子比特从 |1⟩ 开始。
它是辅助比特。
它的作用不是让我们最后读出 f(x)。
恰恰相反,它最后通常会被丢开。
那为什么还需要它?
因为它会经过 Hadamard 门,变成:
(|0⟩ - |1⟩) / √2
这个负号很重要。
正是这个负号,让 Uf 能把函数值写进相位。
如果你现在还觉得“相位”有点抽象,可以先把它理解成量子态前面的正负号。
正号和负号在直接测量时不一定能看出来。
但它们会影响后面的干涉。
这就像第五章说的:
相位是藏起来的信息,干涉能把它翻译成测量结果。
在光量子的图像里,可以把第一个光子准备成水平偏振,也就是 |0⟩。
把第二个光子准备成垂直偏振,也就是 |1⟩。
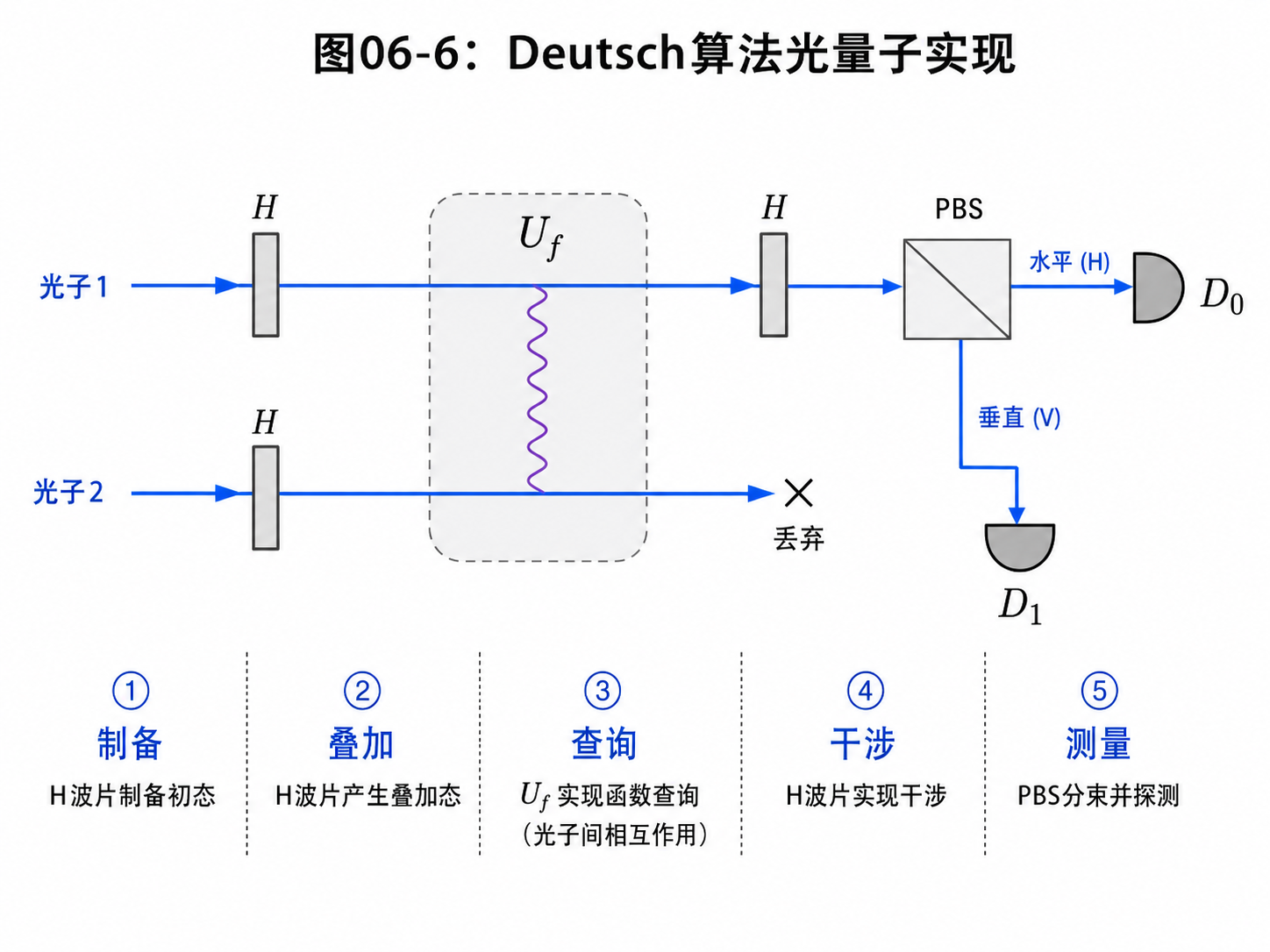
后面的波片负责把它们转成需要的叠加态。
真实实验会有更多工程细节。
这里我们只借光路建立直觉:量子态必须先被制备出来,才能开始演化。
6.5 第一步:Hadamard 制造叠加
现在对两个量子比特都做 Hadamard 门。
Hadamard 门的两个基本作用是:
H|0⟩ = (|0⟩ + |1⟩) / √2
H|1⟩ = (|0⟩ - |1⟩) / √2
所以初始状态:
|0⟩|1⟩
会变成:
(|0⟩ + |1⟩) / √2 ⊗ (|0⟩ - |1⟩) / √2
为了读起来轻一点,我们先不展开全部乘法。
只看每个量子比特发生了什么。
第一个量子比特:
|0⟩ -> (|0⟩ + |1⟩) / √2
它现在同时带着两个输入:0 和 1。
这就是第五章说的“叠加提供容量”。
第二个量子比特:
|1⟩ -> (|0⟩ - |1⟩) / √2
它变成一个带负号的叠加态。
这个状态像一个专门的接收器,后面会把函数值变成相位。
到这里,我们还没有查询函数。
只是把舞台搭好了。
6.6 第二步:一次通过黑盒 Uf
现在,把两个量子比特送进黑盒 Uf。
黑盒规则还是:
Uf |x⟩|y⟩ = |x⟩|y ⊕ f(x)⟩
关键问题是:
当第二个量子比特是
(|0⟩ - |1⟩) / √2
时,Uf 会做什么?
我们分两种情况看。
如果 f(x) = 0,第二个比特不变。
|y⟩ -> |y⟩
所以:
(|0⟩ - |1⟩) / √2
还是它自己。
如果 f(x) = 1,第二个比特翻转。
|0⟩ -> |1⟩
|1⟩ -> |0⟩
那这个状态会变成:
(|1⟩ - |0⟩) / √2
把顺序调整一下:
-(|0⟩ - |1⟩) / √2
也就是说,如果 f(x) = 1,整个状态多了一个负号。
于是,Uf 的作用可以简化理解为:
如果 f(x) = 0,前面乘上 +1
如果 f(x) = 1,前面乘上 -1
写成更紧凑的形式:
|x⟩ 变成 (-1)^f(x) |x⟩
这就是相位回踢。
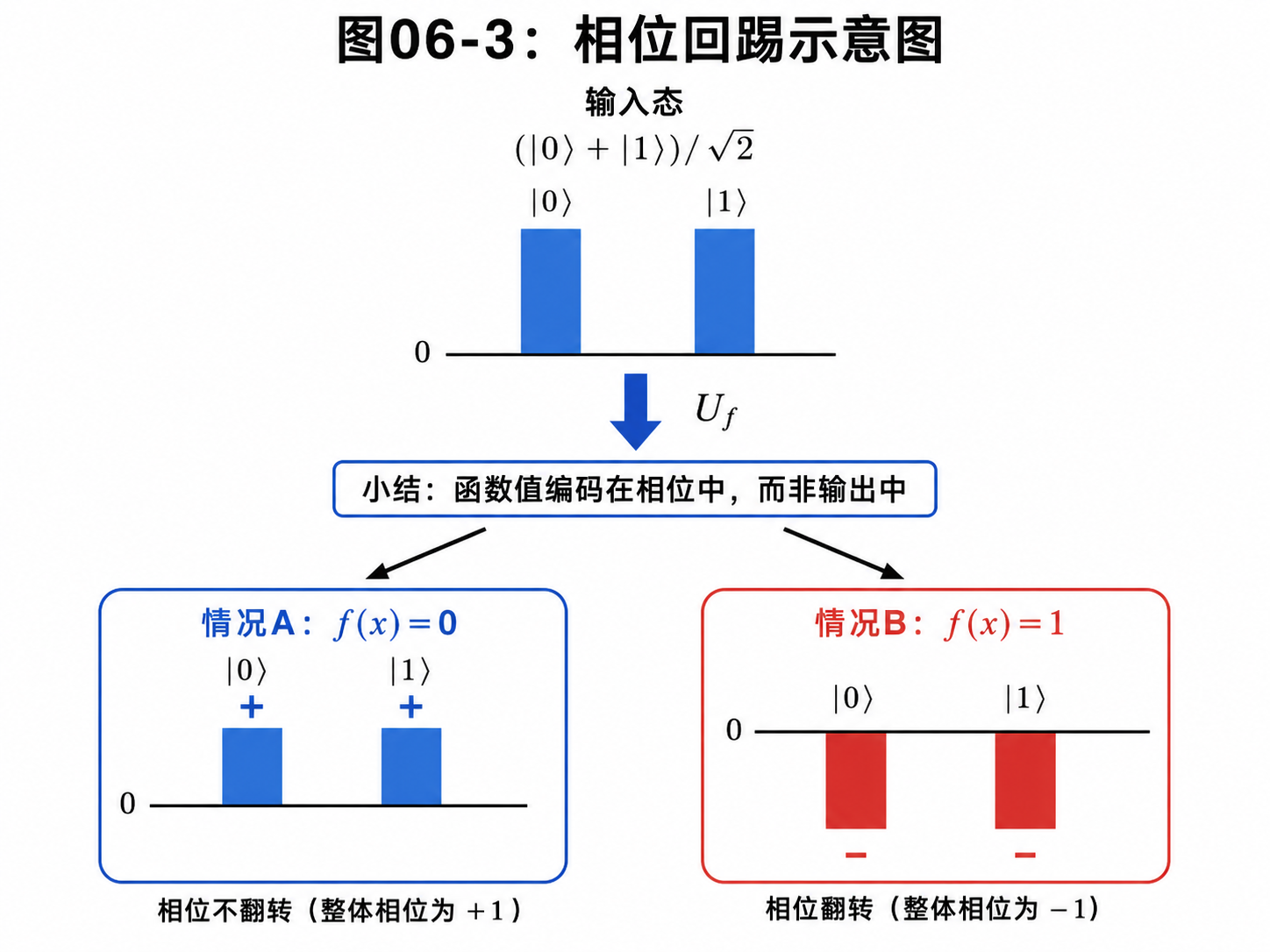
名字听起来有点专业,但意思很朴素:
函数值没有作为普通输出跑出来,而是变成了输入分量前面的正负号。
现在看第一个量子比特。
它本来是:
(|0⟩ + |1⟩) / √2
经过 Uf 后,变成:
((-1)^f(0)|0⟩ + (-1)^f(1)|1⟩) / √2
这就是 Deutsch 算法最关键的一步。
一次查询里,f(0) 和 f(1) 都参与了状态变化。
但它们没有被打印成两个普通答案。
它们被写成了两个分量前面的正负号。
如果函数是常数函数,两个正负号一样。
比如:
f(0)=0, f(1)=0 -> +|0⟩ + |1⟩
f(0)=1, f(1)=1 -> -|0⟩ - |1⟩
这两种情况整体只差一个共同的负号。
共同负号不会影响测量结果。
所以它们对我们来说都是“同一类”:常数。
如果函数是平衡函数,两个正负号相反。
比如:
f(0)=0, f(1)=1 -> +|0⟩ - |1⟩
f(0)=1, f(1)=0 -> -|0⟩ + |1⟩
这两种情况也是整体可能差一个共同负号。
但内部结构是“一个正、一个负”。
所以它们是另一类:平衡。
到这里,我们已经用一次查询把分类信息藏进了相位:
两个符号相同 -> 常数函数
两个符号相反 -> 平衡函数
但还没结束。
因为相位不能直接读。
如果现在测量第一个量子比特,还是不够好。
我们需要把“符号相同或相反”变成“测到 0 或 1”。
这就轮到干涉上场。
6.7 第三步:第二次 Hadamard 让干涉发生
现在只对第一个量子比特再做一次 Hadamard 门。
我们需要用到两条规则:
H(|0⟩ + |1⟩)/√2 = |0⟩
H(|0⟩ - |1⟩)/√2 = |1⟩
第一条的意思是:
如果 |0⟩ 和 |1⟩ 前面的符号相同,经过 Hadamard 后会回到 |0⟩。
第二条的意思是:
如果 |0⟩ 和 |1⟩ 前面的符号相反,经过 Hadamard 后会变成 |1⟩。
这正是我们想要的。
常数函数对应“两个符号相同”。
所以第二次 Hadamard 后,第一个量子比特变成:
|0⟩
平衡函数对应“两个符号相反”。
所以第二次 Hadamard 后,第一个量子比特变成:
|1⟩
现在测量就很简单了。
如果测到:
0
函数是常数函数。
如果测到:
1
函数是平衡函数。
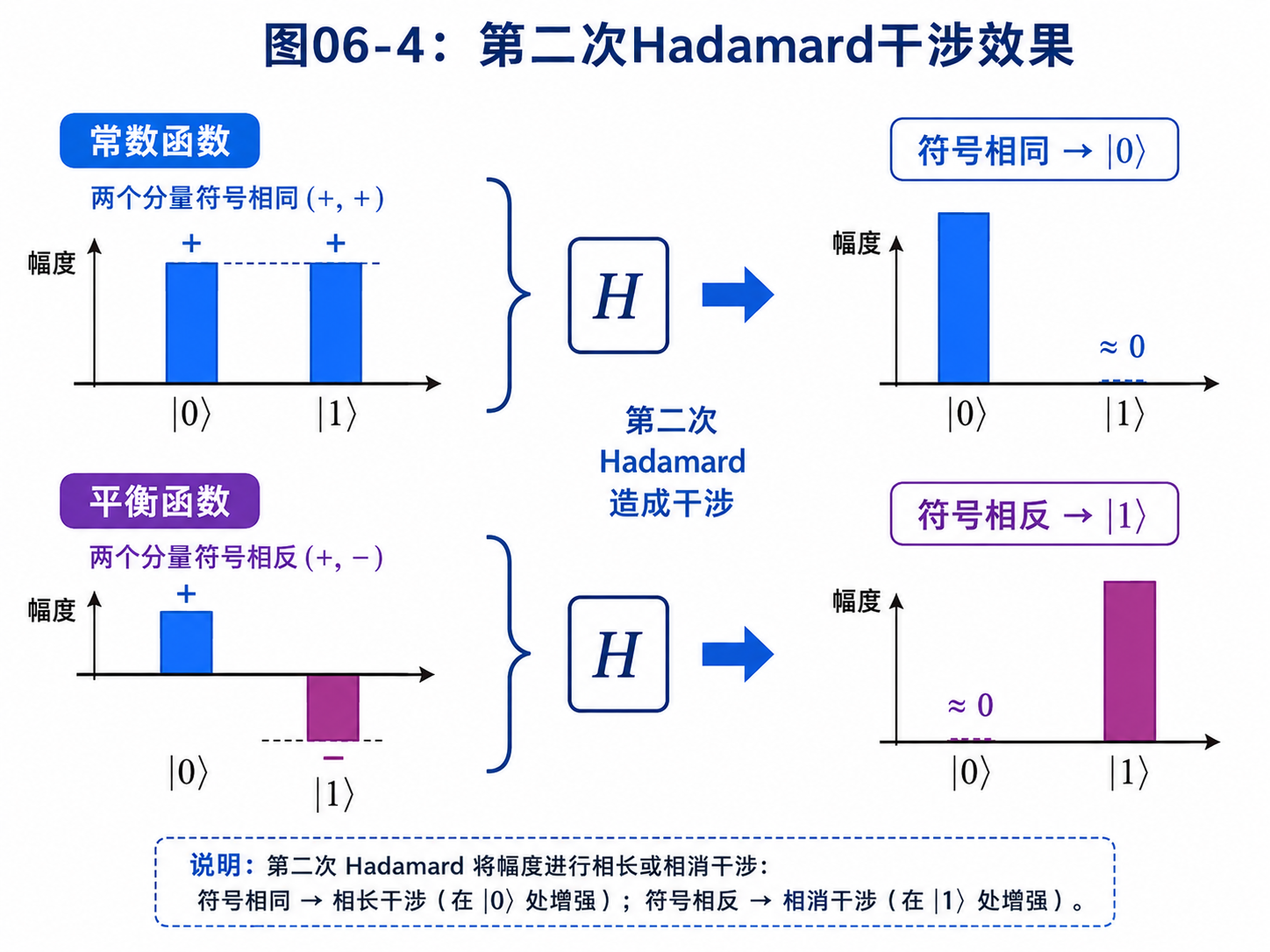
整个过程只调用了一次 Uf。
这就是 Deutsch 算法的 1:2 优势。
6.8 把四种函数全部走一遍
为了让这件事更踏实,我们把四种函数都看一眼。
先看两个常数函数。
第一种:
f(0)=0, f(1)=0
一次查询后,第一个量子比特变成:
(|0⟩ + |1⟩) / √2
第二次 Hadamard 后:
|0⟩
测到 0,判断为常数。
第二种:
f(0)=1, f(1)=1
一次查询后,第一个量子比特变成:
-(|0⟩ + |1⟩) / √2
它只是多了一个整体负号。
整体负号不会改变测量结果。
第二次 Hadamard 后仍然等价于:
|0⟩
测到 0,判断为常数。
再看两个平衡函数。
第三种:
f(0)=0, f(1)=1
一次查询后,第一个量子比特变成:
(|0⟩ - |1⟩) / √2
第二次 Hadamard 后:
|1⟩
测到 1,判断为平衡。
第四种:
f(0)=1, f(1)=0
一次查询后,第一个量子比特变成:
-(|0⟩ - |1⟩) / √2
同样只是多了一个整体负号。
第二次 Hadamard 后等价于:
|1⟩
测到 1,判断为平衡。
四种情况合在一起,规律很清楚:
f(0) 和 f(1) 相同 -> 测到 0
f(0) 和 f(1) 不同 -> 测到 1
算法没有告诉我们完整函数是哪一个。
它只告诉我们想知道的分类。
这点很重要。
量子算法常常不是把所有信息都取出来。
它是把问题改写成一种形式,让我们只取出真正需要的那一点。
6.9 这到底快在哪里
现在回到最初的问题:
Deutsch 算法到底快在哪里?
它不是因为量子门本身“跑得更快”。
也不是因为量子计算机偷偷开了两台经典机器。
它快在查询方式不同。
经典查询一次,只能问一个输入:
请告诉我 f(0)
或者:
请告诉我 f(1)
量子查询一次,可以让黑盒作用在叠加态上。
于是 f(0) 和 f(1) 都会影响振幅。
但这还不够。
如果只是让它们影响振幅,却没有后面的 Hadamard 干涉,我们仍然读不出分类信息。
真正的路线是:
叠加:让两个输入同时参与
相位:把两个输出写成正负号
干涉:把正负号关系变成 0 或 1
测量:读出常数或平衡
所以,Deutsch 算法的优势不是“我一次得到了两个输出”。
更准确地说,它是:
我一次让两个输出共同改变同一个量子态,再用干涉只读出它们之间的关系。
我们要判断的是“两个输出是否相同”。
这是一个关系问题。
量子算法没有分别拿出 f(0) 和 f(1)。
它直接把“相同”或“不同”变成了测量结果。
这就是“问得巧”。
6.10 和第五章的三层结构对应
现在把 Deutsch 算法放回第五章的框架里。
第一层:叠加。
第一次 Hadamard 把第一个量子比特从:
|0⟩
变成:
(|0⟩ + |1⟩) / √2
这让黑盒的一次调用同时涉及两个输入。
第二层:整体变换。
Uf 作用在整个叠加态上。
它不是先算 f(0),再算 f(1)。
它作为一个量子门,一次性改变整个状态。
在这个过程中,函数值被写进相位:
f(x)=0 -> 正号
f(x)=1 -> 负号
第三层:干涉。
第二次 Hadamard 把相位差变成可测量的差别。
符号相同 -> |0⟩
符号相反 -> |1⟩
没有第一步,黑盒只看到一个输入。
没有第二步,函数信息没有进入量子态。
没有第三步,相位信息藏在里面,测量不出来。
这三步连起来,才是完整的量子算法。
6.11 这个例子小,但意义不小
Deutsch 算法本身不解决一个很实用的问题。
如果只看这个问题,经典计算问两次,量子计算问一次。
优势只是 1:2。
这并不震撼。
但它像一块干净的小样本。
它把量子计算为什么可能有优势这件事,第一次摆在了桌面上。
后来更大的算法,很多也沿着相似路线前进:
先制造叠加
再让问题作用在叠加态上
再通过干涉提取全局信息
比如 Deutsch-Jozsa 算法,是 Deutsch 算法的推广。
当输入从 1 个比特变成 n 个比特时,要判断函数是常数还是平衡。
在经典确定性算法里,最坏情况下需要查很多次。
量子算法仍然只需要一次查询。
再往后,Grover 搜索会用振幅放大,让目标答案的概率逐步升高。
Shor 算法会用量子傅里叶变换,把周期信息通过干涉读出来。
这些算法比 Deutsch 算法复杂得多。
但它们都不是凭空冒出来的。
它们都在利用同一个核心事实:
量子态里的振幅可以被整体改变,也可以通过干涉把隐藏结构转成可测量结果。
所以,本章不是为了让你记住一串公式。
它是为了让你第一次看见量子算法的骨架。
6.12 本章小结:量子优势不是多拿答案,而是读出关系
本章讲了 Deutsch 算法。
问题是:
给定 f: {0,1} -> {0,1}
判断它是常数函数还是平衡函数
经典计算必须查询两次。
因为只查一次,只能知道 f(0) 或 f(1) 的一个值。
要判断两个值是否相同,就必须知道两个值。
量子计算只查询一次。
它的路线是:
准备 |0⟩|1⟩
对两个量子比特做 Hadamard
通过 Uf
对第一个量子比特再做 Hadamard
测量第一个量子比特
结果是:
测到 0 -> 常数函数
测到 1 -> 平衡函数
真正关键的机制是:
叠加让两个输入同时参与
Uf 把函数值写进相位
Hadamard 让相位发生干涉
测量读出分类结果
这就是量子优势的第一个清晰例子。
它不神秘,也不是“免费得到所有答案”。
它只是用一种经典计算无法复制的方式,把两个输出之间的关系直接变成了一个可测量的结果。
下一章,我们会从这个小例子继续往外走。
Deutsch 算法告诉我们量子算法可以问得更巧。
接下来要问的是:如果问题规模变大,这种“问得巧”会不会带来更明显的优势?
第七章 从玩具算法到真正优势
第六章讲了 Deutsch 算法。
它很小。
输入只有 0 和 1。
经典计算问两次,量子计算问一次。
如果只看这个数字,你可能会觉得优势不大。
两次变一次,确实不像科幻故事里那种“瞬间破解一切”的场面。
但 Deutsch 算法的价值不在于规模。
它的价值在于把量子算法的骨架摆了出来:
叠加 -> 相位 -> 干涉 -> 测量
本章要把视野放大一点。
我们不再只看一个小问题,而是看几类更典型的量子算法:
Deutsch-Jozsa:把 Deutsch 问题扩展到 n 个输入比特
Bernstein-Vazirani:一次查询读出隐藏字符串
Grover:无结构搜索中的平方根加速
Shor:从周期结构中找到因数
这四个名字听起来像一串人名清单。
先别急着背。
我们关心的不是名字,而是它们背后的共同套路。
量子算法不是对所有问题都自动加速。
它通常需要问题本身有某种结构。
算法要做的事情,就是把这种结构写进振幅和相位,再通过干涉把它读出来。
如果问题没有结构,量子计算也不能凭空创造结构。
它最多给出有限的加速。
所以,本章的目标不是把每个算法推到论文细节。
我们先建立一张地图:
哪些问题能快很多?
哪些问题只能快一点?
量子优势到底来自哪里?
7.1 Deutsch-Jozsa:从 1 个输入比特到 n 个输入比特
先看 Deutsch 算法的直接推广:Deutsch-Jozsa 算法。
Deutsch 问题里,函数输入只有 1 个比特。
所以输入只有两种:
0
1
Deutsch-Jozsa 问题把输入扩展成 n 个比特。
如果 n 是 3,输入就有八种:
000
001
010
011
100
101
110
111
如果 n 是 10,输入就有 2¹⁰ = 1024 种。
如果 n 是 100,输入就有 2¹⁰⁰ 种。
问题仍然是判断函数的类型。
但这里有一个承诺:
这个函数要么是常数函数
要么是平衡函数
常数函数的意思是:
所有输入都输出 0
或者:
所有输入都输出 1
平衡函数的意思是:
一半输入输出 0
一半输入输出 1
任务是判断:
它是常数函数,还是平衡函数?
经典计算要问多少次
经典确定性计算在最坏情况下要问很多次。
假设你已经查了很多输入,结果全都是 0。
你能不能立刻断定它是常数函数?
不能。
只要还有没查的输入,就可能存在一种情况:
前面查到的全是 0,剩下的某些输入会输出 1。
在最坏情况下,经典计算需要查:
2ⁿ⁻¹ + 1
次。
为什么是这个数?
因为如果一个函数是平衡函数,它有一半输出 0,一半输出 1。
你最多可能先碰到整整一半同样的结果。
只有当你多查一个,仍然没有看到不同输出时,才能确认它不是平衡函数,而是常数函数。
这就是经典查询的成本。
量子计算只问一次
Deutsch-Jozsa 算法的量子版本仍然只查询一次黑盒。
它的路线和 Deutsch 算法很像:
先把所有输入放进叠加
再让黑盒把函数值写进相位
最后用 Hadamard 门让相位发生干涉
如果函数是常数函数,所有输入得到的相位变化是同一种模式。
干涉后,测量会回到全 0 状态。
如果函数是平衡函数,一半输入带一种符号,另一半输入带另一种符号。
这些振幅会在全 0 方向上相互抵消。
测量时就不会得到全 0。
所以判断规则很简单:
测到 00...0 -> 常数函数
测到其他结果 -> 平衡函数
这里最重要的不是公式,而是思路:
量子算法不是逐个读取所有函数值,而是直接读取一个全局性质。
这个全局性质就是:
所有输出是否都一样?
Deutsch-Jozsa 展示了一个指数级优势。
经典最坏要问 2ⁿ⁻¹ + 1 次。
量子只问 1 次。
但也要注意,它依赖一个前提:
题目提前承诺函数一定是常数或平衡。
如果没有这个承诺,问题就不是同一个问题。
量子算法的优势,常常来自“问题结构”和“算法设计”一起配合。
7.2 Bernstein-Vazirani:一次查询读出隐藏字符串
第二个算法叫 Bernstein-Vazirani。
名字长,但问题很清楚。
有一个隐藏字符串 s。
比如:
s = 10110
我们不能直接看到它。
只能向黑盒输入一个字符串 x。
黑盒返回:
f(x) = s · x
这里的点乘不用想得太复杂。
它的意思是:
把 s 和 x 对应位置上的 1 做匹配,然后算一个 0 或 1 的结果。
举个小例子。
假设:
s = 101
x = 110
只有第一位同时是 1。
第三位里 s 是 1,但 x 是 0。
所以结果是:
f(x) = 1
如果:
s = 101
x = 001
第三位同时是 1,所以:
f(x) = 1
如果两个位置都同时匹配,就会按照模 2 规则相加。
模 2 的意思是:
0 + 0 = 0
0 + 1 = 1
1 + 0 = 1
1 + 1 = 0
所以结果永远是 0 或 1。
经典怎么找 s
经典计算可以一位一位问。
如果你想知道 s 的第一位,就输入:
10000
黑盒返回的就是第一位的信息。
想知道第二位,就输入:
01000
这样问下去。
如果 s 有 n 位,经典做法通常需要 n 次查询。
量子怎么一次读出来
量子算法的做法仍然是熟悉的套路:
把所有 x 放进叠加
让黑盒把 f(x) 写进相位
再用 Hadamard 门让这些相位干涉
最后测量,会直接得到隐藏字符串 s。
这件事听起来像魔术。
但它和 Deutsch 算法其实是同一个精神。
Deutsch 算法读出的,是两个输出之间“相同还是不同”的关系。
Bernstein-Vazirani 读出的,是隐藏字符串对所有输入留下的相位痕迹。
经典计算一次查询只得到一个 0 或 1。
量子计算让所有输入一起参与相位变化。
Hadamard 门再把这些相位关系折回来,变成可测量的字符串。
这一类算法提醒我们:
量子计算擅长提取隐藏在函数背后的整体模式。
它不是把函数表完整打印出来。
它是把函数表里的结构直接压成我们想要的答案。
7.3 Grover 搜索:没有结构也能快一点
前面两个算法都利用了很强的结构。
Deutsch-Jozsa 有承诺:函数要么常数,要么平衡。
Bernstein-Vazirani 有隐藏字符串结构。
那如果问题没有这么漂亮的结构呢?
比如,在 N 个候选项里找一个目标。
你只知道有一个黑盒可以判断某个候选项是不是目标:
输入一个候选项
黑盒回答 是 或 不是
经典计算如果运气不好,可能要查很多次。
最坏情况下,要查接近 N 次。
这就是无序搜索。
它没有明显结构。
目标可能在任何位置。
你不能提前知道哪里更有希望。
Grover 算法说明:
即使在这种没有结构的问题上,量子计算也能加速。
但加速不是指数级,而是平方根级。
如果经典需要大约:
N
次查询,Grover 大约需要:
√N
次查询。
比如 N 是 1,000,000。
经典最坏可能要查接近一百万次。
Grover 大约需要一千次量级的查询。
这已经很有价值。
但它也告诉我们一件事:
量子计算不是万能的指数加速器。
Grover 的核心:振幅放大
Grover 的思路不是一次看完所有候选项。
它先把所有候选项放进均匀叠加。
一开始,每个候选项被测到的概率都差不多。
目标答案也只是其中很小的一部分。
然后算法反复做两类操作。
第一类操作:标记目标。
如果某个候选项是目标,就把它的相位翻一下。
可以理解成给目标做一个暗号。
第二类操作:围绕平均值反射。
这个名字听起来不太友好。
可以先理解成一种干涉操作:
它会让被标记目标的振幅变大,让其他候选项的振幅相对变小。
一次操作,目标振幅只增加一点。
重复很多次后,目标答案的概率会明显升高。
最后测量,就很可能得到目标。
Grover 的核心可以概括成:
先平均铺开
再标记目标
再反复放大目标振幅
最后测量
它不像 Deutsch-Jozsa 那样一次完成。
它需要重复大约 √N 次。
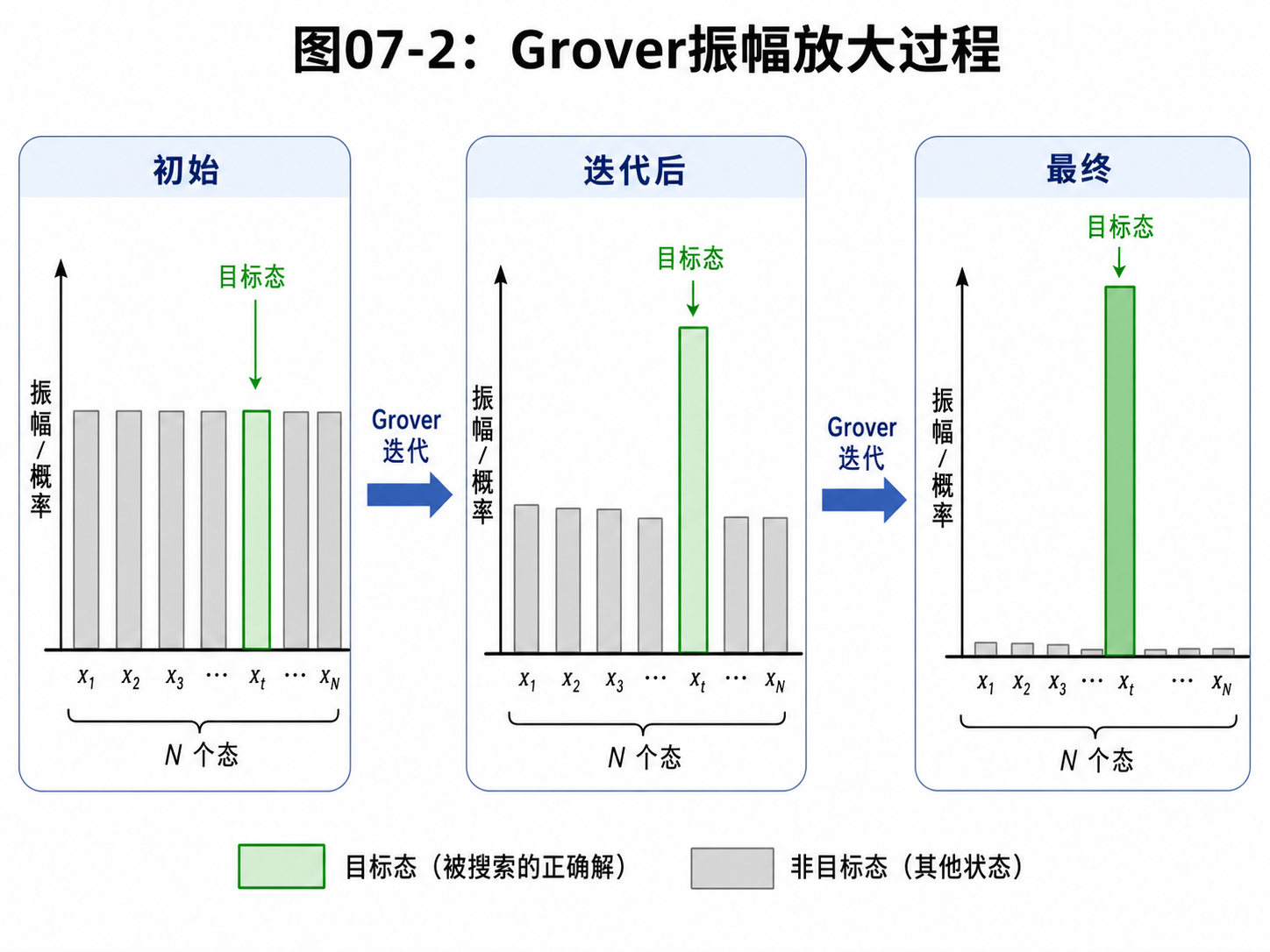
这正说明了结构的重要性。
如果问题有强结构,量子算法可能直接提取全局性质。
如果问题几乎没有结构,量子算法仍然可以利用振幅放大,但速度优势就有限。
7.4 Shor 算法:从周期找到因数
现在来到最有名的量子算法:Shor 算法。
它之所以有名,是因为它和大整数因数分解有关。
给你一个很大的数,比如:
N = p × q
其中 p 和 q 是两个大质数。
如果只给你 N,要反推出 p 和 q,对经典计算机来说可能非常困难。
现代密码体系里,有些方案正是利用了这一点。
乘法很容易。
反过来分解因数很难。
Shor 算法说明:
理想的大规模量子计算机可以高效做因数分解。
这句话很重要,但也要说准确。
Shor 不是让量子计算机暴力尝试所有因子。
它不是从 2 开始,一个一个试到平方根。
它做的是结构提取。
具体说,Shor 把因数分解转化成一个寻找周期的问题。
周期是什么
我们先看一个普通周期。
如果一个函数的值不断重复,比如:
3, 5, 7, 3, 5, 7, 3, 5, 7
它的周期就是 3。
因为每隔 3 步,模式重复一次。
Shor 算法里的周期更抽象一些。
它和模运算有关。
但直觉类似:
某个函数的输出会按固定间隔重复
如果能找到这个周期,就能通过经典数学步骤推出 N 的因子。
量子部分负责最难的一段:
从很大的叠加态里提取周期信息
经典部分负责后处理:
把测量结果整理成周期
再用周期推出因子
量子傅里叶变换的作用
Shor 算法里有一个重要工具:量子傅里叶变换。
傅里叶变换在很多领域都出现过。
如果你学过信号处理,可能知道它能把一个信号拆成不同频率。
这里不用深入公式。
只要先记住一个直觉:
傅里叶变换擅长发现周期。
量子傅里叶变换会把周期结构转成测量时更容易出现的峰值。
换句话说,周期本来藏在一大片振幅关系里。
量子傅里叶变换让这些振幅发生干涉。
和周期匹配的方向被加强。
不匹配的方向被抵消。
最后测量得到的信息虽然不是周期本身,但足够让经典后处理恢复周期。
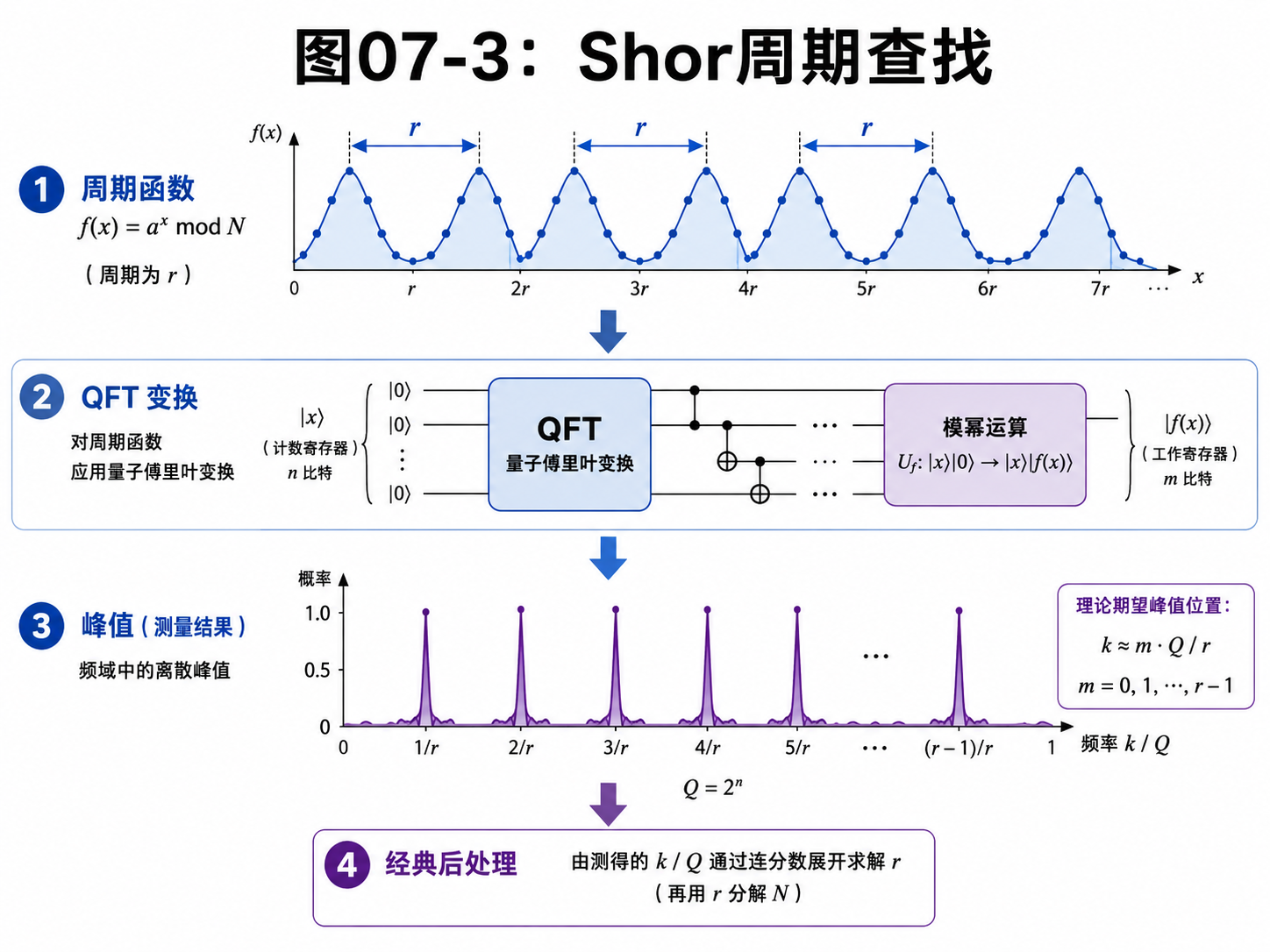
所以 Shor 的主线可以写成:
把因数分解转成找周期
制造大叠加
把周期结构写进量子态
用量子傅里叶变换让周期信息显出来
测量
用经典算法恢复周期并推出因子
这仍然是第五章以来的老主题:
叠加提供容量
问题写入相位和振幅
干涉凸显结构
测量读出有用信息
Shor 算法复杂得多。
但它不是魔法。
它是这条路线在更大问题上的成功应用。
7.5 四类算法放在一起看
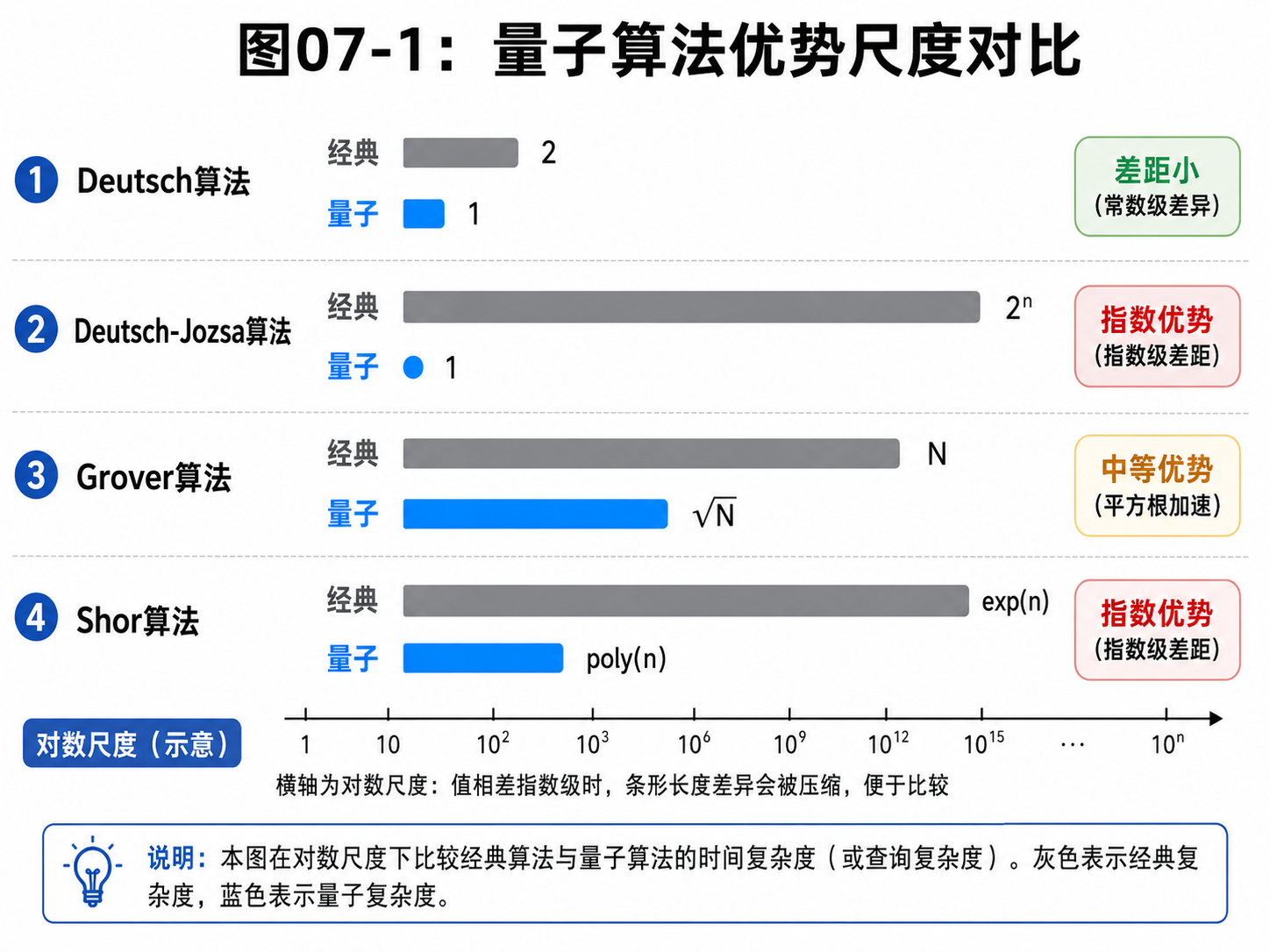
现在把这几个算法放在一起。
Deutsch:
判断两个输出是相同还是不同。
经典 2 次,量子 1 次。
Deutsch-Jozsa:
判断大量输出是全部相同,还是一半一半。
经典最坏指数次,量子 1 次。
Bernstein-Vazirani:
找隐藏字符串。
经典通常 n 次,量子 1 次。
Grover:
无序搜索。
经典约 N 次,量子约 √N 次。
Shor:
因数分解。
经典已知高效算法很难做到,量子可以转成周期问题高效处理。
它们的共同点不是“都把所有答案读出来”。
共同点是:
把问题结构写进量子态
让振幅发生有目的的干涉
只测量最后需要的信息
不同点在于结构强弱。
Deutsch-Jozsa 的结构很强。
题目承诺函数不是常数就是平衡。
所以量子算法能一次提取全局性质。
Bernstein-Vazirani 的结构也很强。
函数背后有一个隐藏字符串。
相位干涉可以直接把它读出来。
Grover 的结构弱。
黑盒只告诉你“是不是目标”。
所以量子计算只能做振幅放大,得到平方根加速。
Shor 的结构很深。
因数分解表面上难,但它可以转成周期查找。
一旦周期结构进入量子态,量子傅里叶变换就能发挥力量。
这给我们一个重要判断:
量子优势不是只看量子比特数量,而是看问题结构能不能被量子算法利用。
有很多量子比特,但问题没有合适结构,未必有巨大优势。
量子比特不多,但结构刚好,也可能展示清楚的优势。
7.6 量子算法的共同设计模式
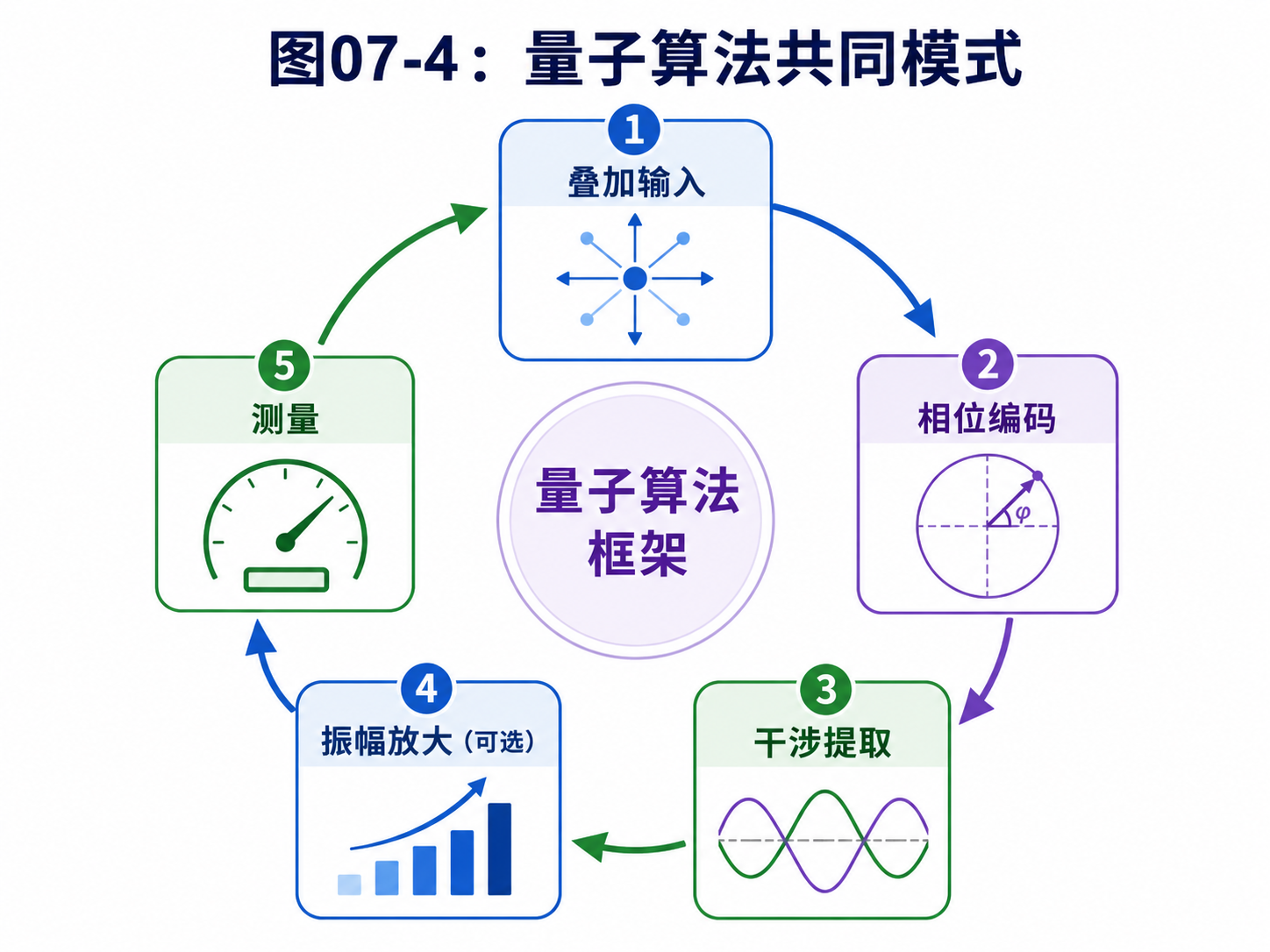
回看这些算法,可以总结出几种常见设计模式。
第一种:叠加输入。
把很多可能输入放进一个量子态里。
这不是为了最后把所有输入逐个读出来,而是为了让它们一起参与后面的变换。
Deutsch-Jozsa 和 Shor 都很依赖这一点。
第二种:相位记录。
把函数值写进相位,而不是写成普通输出。
相位直接测量不容易看见,但它能参与干涉。
Deutsch 和 Bernstein-Vazirani 都展示了这个思路。
第三种:干涉提取。
让有用方向的振幅加强,让无用方向的振幅抵消。
这是大多数量子算法真正读出信息的地方。
第四种:振幅放大。
当我们知道某些状态是目标,但不知道具体是哪一个时,可以逐步提高目标状态的概率。
Grover 就是最典型的例子。
第五种:傅里叶变换。
当问题里藏着周期时,傅里叶变换能把周期结构变成测量时的峰值。
Shor 的核心就在这里。
这些模式可以放成一张小表:
叠加输入 -> 覆盖大量可能性
相位记录 -> 把函数值藏进量子态
干涉提取 -> 把隐藏信息变成可测结果
振幅放大 -> 提高目标答案概率
傅里叶变换 -> 显出周期结构
后面读更复杂的算法时,可以不断回到这张表。
很多看起来吓人的公式,其实都在做这些事。
7.7 不要把量子计算神化
讲到这里,很容易产生一个反方向的误解:
既然有些算法能指数加速,那量子计算是不是能让所有难题都变简单?
不是。
量子计算很强,但不是万能。
第一,不是所有问题都有已知的量子加速。
有些问题,量子算法只能稍微快一点。
有些问题,目前还不知道能不能快。
也有一些问题,量子计算未必比经典计算有明显优势。
第二,量子优势通常需要特殊结构。
比如周期、隐藏线性关系、可被干涉放大的目标。
如果问题只是完全没有规律地堆在那里,量子计算也只能有限加速。
第三,算法优势不等于立刻能在现实机器上运行。
Shor 算法很有名。
但要分解真正威胁现代密码的大整数,需要大规模、低错误率、可纠错的量子计算机。
这和今天有几十、几百、几千个有噪声量子比特的机器,不是一回事。
所以我们需要同时保持两种态度:
看到量子算法的真实力量
也看到现实工程的困难
这并不矛盾。
真正成熟的理解,既不会把量子计算说成万能钥匙,也不会因为今天机器还不完美就否定它的长期价值。
7.8 本章小结:量子优势来自结构
本章从 Deutsch 算法出发,看了更大的算法地图。
Deutsch-Jozsa 把 Deutsch 问题扩展到 n 个输入比特。
它说明量子计算可以一次提取某些全局性质。
Bernstein-Vazirani 展示了隐藏字符串如何被写进相位,再通过 Hadamard 门读出来。
Grover 搜索说明,即使问题没有强结构,量子计算也能通过振幅放大得到平方根加速。
Shor 算法展示了量子计算最著名的应用方向:
把因数分解转成周期查找,再用量子傅里叶变换提取周期。
这些算法的共同主题是:
叠加不是答案
相位记录信息
干涉提取结构
测量只读最后需要的结果
量子优势不是凭空来的。
它来自问题结构,也来自算法把结构转成振幅变化的能力。
下一章,我们要从理想算法回到真实机器。
前面所有算法都假设量子态能稳定保持,量子门能准确执行。
但现实世界有噪声,有退相干,有错误。
量子计算真正困难的地方,也正是在这里开始显形。
第八章 噪声、退相干与量子纠错
前面几章,我们一直在讲理想量子计算。
理想世界里,量子比特可以稳定保持叠加。
量子门可以准确执行。
测量也不会出错。
算法只要设计得漂亮,答案就会按计划出现。
但真实机器没有这么干净。
真实量子比特很脆弱。
环境会影响它。
控制脉冲会有误差。
测量设备也可能读错。
如果说前几章讲的是“量子计算为什么可能快”,那么本章要讲的是:
为什么真正造出可靠量子计算机这么难?
这不是给量子计算泼冷水。
恰恰相反,只有理解困难,才能真正理解这项技术的价值。
量子计算不是只靠一个好算法就能成功。
它还需要一整套物理工程:
保护量子态
准确操作量子门
发现错误
纠正错误
把许多脆弱物理比特变成少数可靠逻辑比特
这些就是从理想到现实必须跨过的桥。
8.1 为什么量子比特容易受伤
经典比特很粗壮。
在普通电脑里,一个比特通常对应一个清楚的物理状态。
比如高电压表示 1,低电压表示 0。
只要电压差足够大,中间有一点小扰动,电路也能判断出它到底是 0 还是 1。
这就像你把一个开关推到最左边或最右边。
只要它没有被推到中间,机器就能读出明确结果。
量子比特不一样。
量子比特可以处在叠加态:
α|0⟩ + β|1⟩
这里不只是“0 的比例”和“1 的比例”重要。
两个分量之间的相对相位也很重要。
相位可以理解成两个分量之间的精细关系。
很多量子算法正是靠这个精细关系来安排干涉。
问题是:
这种精细关系很容易被环境扰乱。
温度变化、电磁噪声、材料缺陷、控制线路的微小波动,都可能让量子态偏离原来的轨道。
偏得一点点,单次看也许不明显。
但量子算法往往要连续做很多门。
小误差会积累。
积累到一定程度,原本设计好的干涉就乱了。
第五章和第六章一直强调:
正确答案的振幅要加强
错误答案的振幅要抵消
如果噪声把相位搅乱,振幅就不能按计划相长、相消。
最后测量出来的结果也就不可靠。
8.2 退相干:环境在旁边偷听
退相干是量子计算里最重要的困难之一。
“相干”可以先理解成:
量子态内部的相位关系还保持得很好
“退相干”就是:
这种相位关系被环境慢慢破坏
我们可以用一个比喻。
假设你在一个非常安静的房间里听两段声音。
它们的节奏要精确配合,才能合成你想听到的效果。
如果房间里突然有杂音,有人说话,有机器震动。
两段声音之间的细微关系就会变得模糊。
你最后听到的,不再是原来设计好的效果。
量子比特也类似。
叠加态里的相位关系,需要保持安静、稳定、隔离。
环境一旦和它发生微弱相互作用,就像在旁边“偷听”了一点信息。
这里的“偷听”不一定是人真的去测量。
它可能只是一个热振动、一个 stray 电场、一点材料缺陷。
但只要环境带走了关于量子态的信息,叠加态就会被破坏。
这就是退相干。
退相干不是突然爆炸。
很多时候,它更像慢慢褪色。
一开始,量子态还能保持原来的精细关系。
过了一段时间,相位开始漂移。
再过一段时间,原本能产生干涉的关系变弱。
最后,量子态看起来越来越像普通随机混合。
这对量子计算很致命。
因为量子算法依赖的不是普通随机性。
它依赖的是可控叠加和可控干涉。
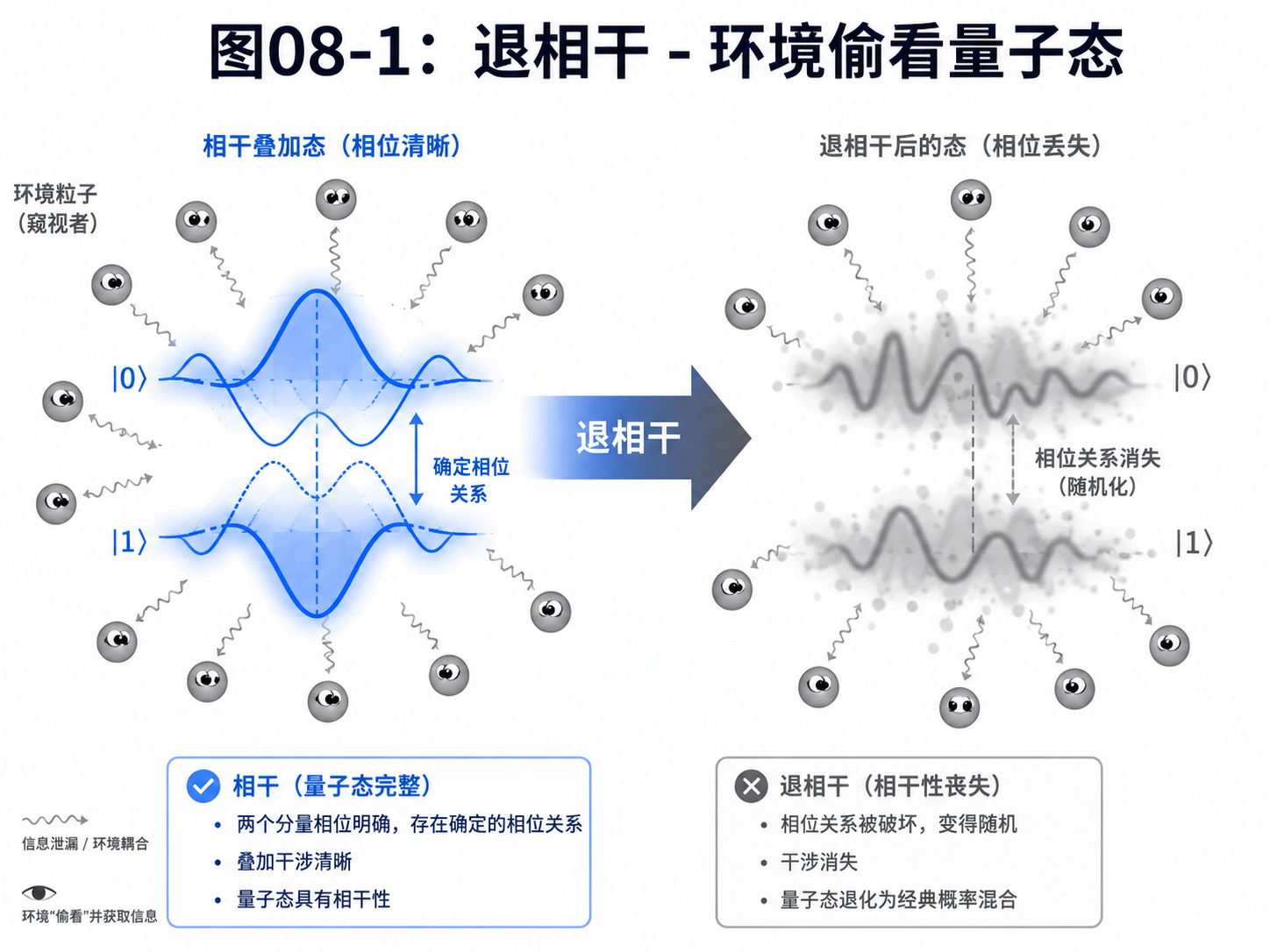
8.3 T1 和 T2:两个常见时间尺度
讨论退相干时,经常会看到两个符号:
T1
T2
这两个符号看起来像工程参数。
但它们背后的意思可以说得很简单。
T1:能量会不会掉下来
T1 常被叫作能量弛豫时间。
如果一个量子比特处在 |1⟩,它可能慢慢掉回 |0⟩。
这就像一个被举高的小球,时间久了会往低处落。
T1 描述的就是这种能量状态能保持多久。
如果 T1 很短,量子比特还没算完就自己变了。
算法当然会出错。
T2:相位关系能不能保持
T2 常被叫作相干时间。
它关心的是叠加态里的相位关系能保持多久。
比如:
(|0⟩ + |1⟩) / √2
和:
(|0⟩ - |1⟩) / √2
测量概率可能都各有一半。
但它们的相位不同。
后面做 Hadamard 时,结果会完全不同。
这就是相位的重要性。
T2 越长,说明这种相位关系能保存越久。
T2 越短,说明叠加态很快就会失去可用的干涉能力。
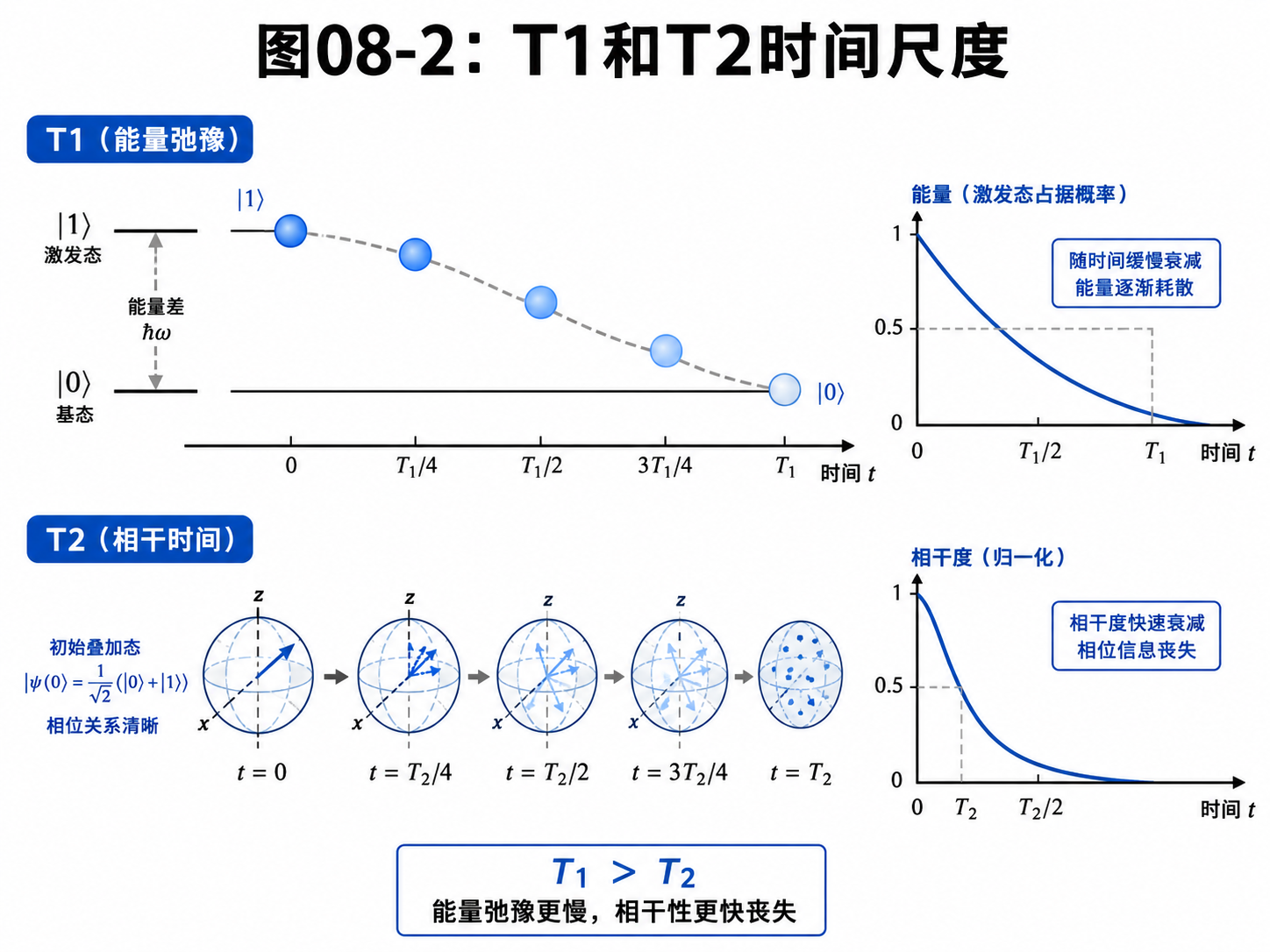
不同硬件路线的 T1、T2 差别很大。
超导量子比特、离子阱、光量子、半导体量子点,各有自己的优势和难题。
这里不需要背具体数字。
只要记住:
量子计算必须在量子态“忘掉自己是谁”之前完成足够可靠的操作。
8.4 噪声:没有完美的量子门
就算量子比特暂时没有退相干,量子门本身也可能不完美。
经典计算里,逻辑门已经非常可靠。
一个普通晶体管开关,虽然也有物理噪声,但工程上已经能把错误压得极低。
量子门更难。
因为它不是简单地把 0 改成 1,或者把 1 改成 0。
它要把量子态转到一个非常精确的位置。
比如 Hadamard 门要把:
|0⟩
变成:
(|0⟩ + |1⟩) / √2
如果控制脉冲稍微偏一点,得到的状态就可能不是理想的 45 度方向。
一次偏一点,也许还可以忍。
但一个有用算法可能需要很多门。
每个门都有一点误差,最后结果就会明显偏离。
噪声可能来自很多地方:
控制脉冲幅度不准
脉冲时间不准
器件之间串扰
温度波动
读出设备误差
材料缺陷
不同硬件路线的噪声来源不一样。
超导量子比特常见的是微波控制、低温环境、线路串扰等问题。
离子阱常见的是激光稳定性、离子运动模式、真空环境等问题。
光量子常见的是单光子源、损耗、探测效率等问题。
路线不同,麻烦不同。
但目标一样:
让量子门足够准
让错误率足够低
让错误能被发现和纠正
8.5 为什么经典纠错不能直接搬过来

经典计算机也会出错。
但经典纠错很成熟。
最简单的思路是复制。
如果你想存一个 0,可以存三份:
000
如果其中一个坏了,变成:
001
你看三份里多数是 0,就知道应该纠正成 0。
这叫多数表决。
它简单,但很有效。
那量子计算能不能也这样?
比如把一个未知量子态复制三份:
|ψ⟩ |ψ⟩ |ψ⟩
然后多数表决?
不行。
原因有三条。
第一,未知量子态不能随便复制。
这就是不可克隆定理。
它的意思是:
你不能造一个通用机器,把任意未知量子态完美复制一份。
第二,量子态不能随便测量。
经典表决需要先读出三份分别是什么。
但量子态一测量,就可能坍缩。
你本来想保护叠加态,结果测量本身把叠加破坏了。
第三,量子错误不只是 0 变 1。
经典比特的典型错误是离散的:
0 -> 1
1 -> 0
量子态的错误可以是连续的。
相位可能偏一点,振幅方向可能转一点。
它不是简单的“这一份错了,那两份对了”。
所以,经典纠错的三个基础:
能复制
能直接读取
错误容易离散判断
在量子世界里都不成立。
量子纠错必须另想办法。
8.6 量子纠错的核心:不问数据,只问错误
量子纠错最聪明的地方在于:
不直接测量量子数据本身,而是测量“有没有错、哪里可能错”。
这句话很关键。
如果你直接问:
这个量子比特是 0 还是 1?
那就破坏了叠加。
但如果你问的是:
这两个量子比特是否保持了某种关系?
就有机会发现错误,而不直接泄露原来的量子信息。
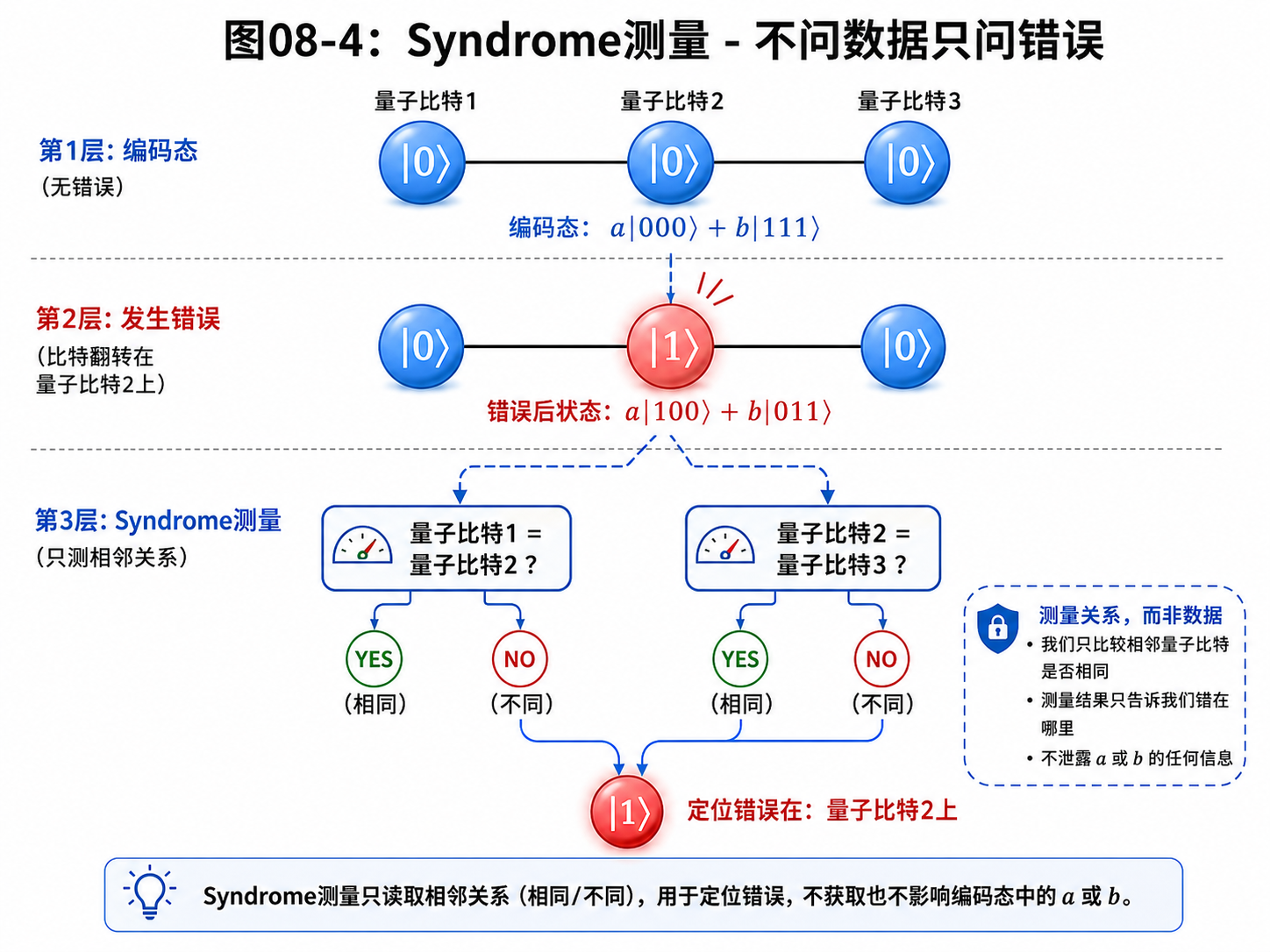
这种“错误的线索”常叫错误症状。
英文是 syndrome。
可以用一个简化例子说明。
我们想保护一个逻辑量子比特。
理想地说,它可能是:
a|0⟩ + b|1⟩
我们不能直接复制它。
但可以把它编码到多个物理量子比特组成的整体状态里。
教学上常用一个简化的三比特例子:
|0⟩_L = |000⟩
|1⟩_L = |111⟩
这里的 _L 表示逻辑比特。
一个逻辑比特不是一个物理比特,而是多个物理比特共同表示的编码状态。
如果逻辑态是:
a|0⟩_L + b|1⟩_L
展开就是:
a|000⟩ + b|111⟩
现在假设第一个物理比特发生了翻转错误。
它会变成:
a|100⟩ + b|011⟩
我们不能直接测量三个比特是什么。
那会破坏 a 和 b 代表的叠加信息。
但我们可以测一些关系。
比如:
第一个和第二个是否相同?
第二个和第三个是否相同?
这些问题不直接问“数据是什么”。
它们问的是“结构有没有破”。
通过这些关系,我们可以推断哪个位置可能出错。
然后对那个位置做纠正。
这个例子很简化。
它只展示了量子纠错的精神:
把信息分散编码
测错误症状
不直接读数据
根据症状纠正
真正实用的量子纠错码要复杂得多。
但核心思想仍然是这条线。
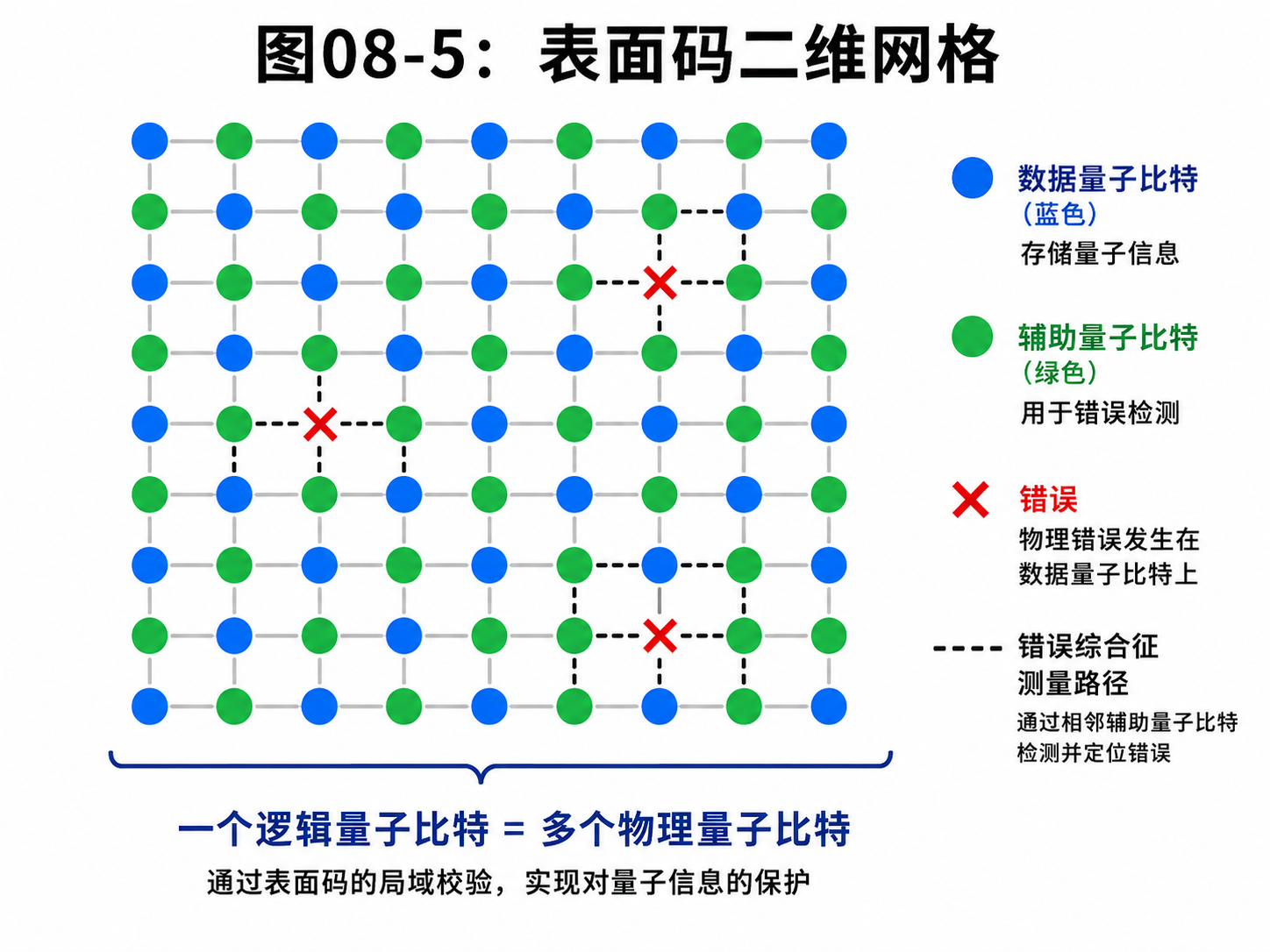
8.7 表面码:把逻辑比特藏进一张网
在许多量子纠错方案里,表面码是很重要的一类。
它的直觉可以这样理解:
不要把一个逻辑量子比特放在一个孤零零的物理比特里。
而是把它分散到一张二维网格上。
网格上有很多物理量子比特。
有些负责存信息。
有些负责帮助检查错误。
机器会反复测量局部关系。
比如相邻区域是否满足某种约束。
如果某处出现异常,错误症状就会在网格上留下痕迹。
纠错程序再根据这些痕迹推测:
错误可能从哪里开始?
经过了哪里?
应该怎样修复?
这有点像在一张地图上看脚印。
你没有直接看到错误本身。
但你看到了它留下的线索。
表面码受重视,是因为它比较适合二维芯片结构,也比较能容忍局部错误。
当然,它的代价也很高。
一个可靠的逻辑量子比特,往往需要很多物理量子比特来保护。
具体需要多少,取决于物理错误率、目标可靠性、纠错码设计和算法长度。
所以,当新闻里说某台机器有多少“物理量子比特”时,不能直接把它等同于多少“可靠量子比特”。
有噪声的物理比特很多,不等于已经能运行长算法。
真正关键的是:
能不能把物理比特组织成可靠的逻辑比特
能不能让逻辑比特执行长时间、低错误的计算
这就是容错量子计算的目标。
8.8 NISQ:有噪声的中等规模量子计算
在大规模容错量子计算到来之前,有一类机器常被称为 NISQ。
NISQ 是几个英文词的缩写:
Noisy
Intermediate-Scale
Quantum
可以翻成:
有噪声的中等规模量子设备
这个名字很诚实。
它说明这些机器确实是量子设备。
它们有一定数量的量子比特。
它们能执行量子门,也能展示量子效应。
但它们也有明显噪声。
门不够完美。
相干时间有限。
纠错能力还不足以支持非常长、非常深的算法。
所以 NISQ 时代的算法思路和理想容错量子计算不同。
理想容错量子计算可以运行很长的算法。
比如大规模 Shor 算法,需要大量稳定逻辑比特和很长的量子线路。
NISQ 设备更适合短线路。
常见思路是量子-经典混合:
量子设备负责准备和测量某些量子态
经典计算机负责调整参数、统计结果、做优化
这类思路包括一些变分算法。
它们常用于量子化学、优化问题、材料模拟等方向的探索。
但这里也要诚实:
NISQ 设备很有研究价值,但并不等于已经普遍解决了商业上的难题。
许多应用仍在探索中。
哪些任务能获得稳定、可重复、超过经典方法的优势,还需要时间检验。
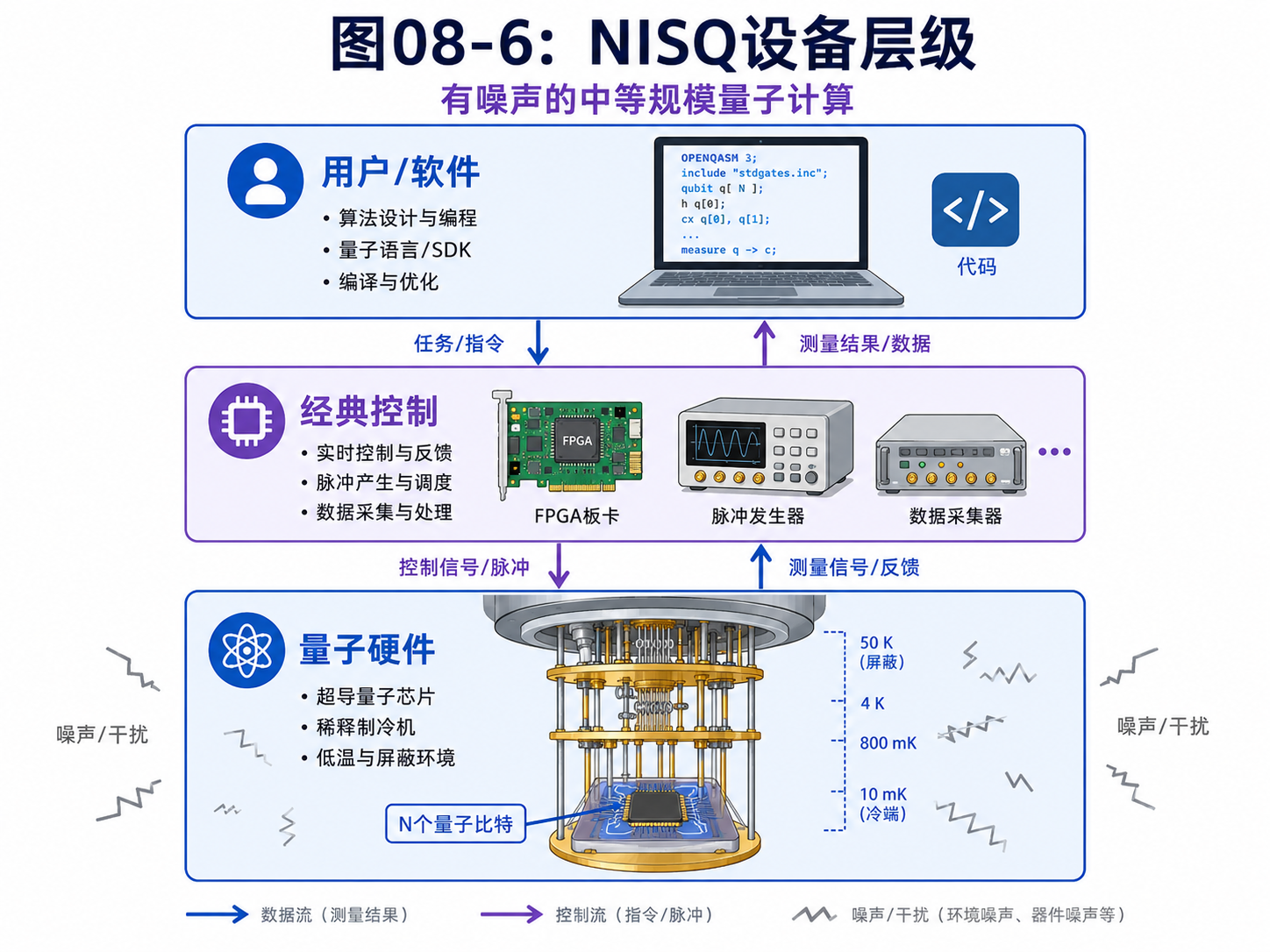
这不是失败。
这是技术发展阶段。
早期经典计算机也经历过体积巨大、成本很高、可靠性有限的时期。
量子计算现在面对的是更难的物理条件。
8.9 从物理比特到逻辑比特
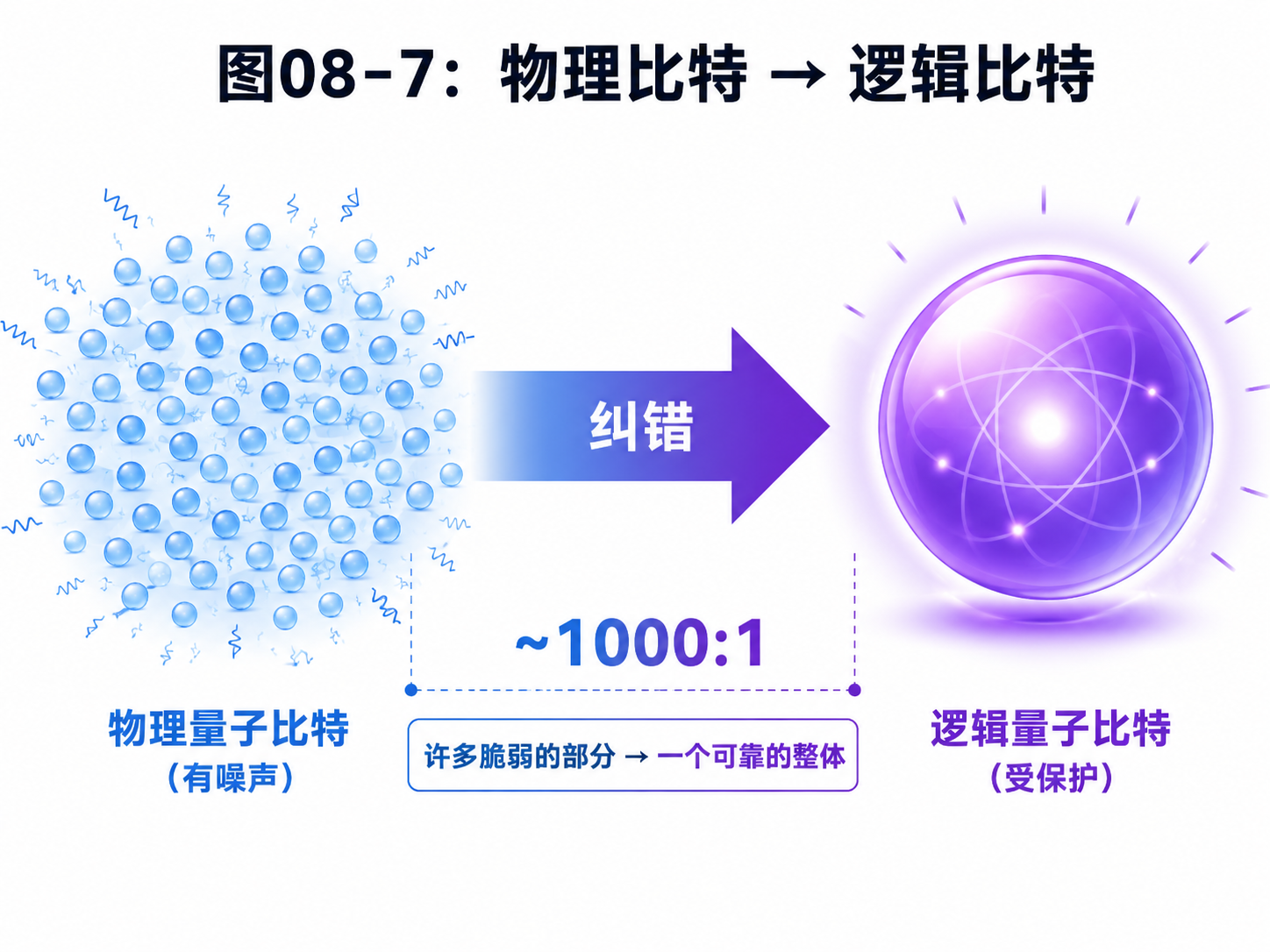
理解真实量子计算机时,一定要区分两个词:
物理量子比特
逻辑量子比特
物理量子比特,是机器里真实存在的量子系统。
比如一个超导电路、一个离子、一个光子模式、一个半导体量子点。
逻辑量子比特,是经过纠错编码后得到的更可靠的信息单位。
一个逻辑量子比特通常需要很多物理量子比特共同保护。
这就像用很多不太可靠的小零件,拼出一个更可靠的大部件。
为什么要这样做?
因为单个物理量子比特太脆弱。
如果一个算法需要运行很久,单个物理比特很可能撑不到最后。
逻辑量子比特通过纠错,不断发现和修正小错误。
只要物理错误率低到一定程度,纠错就能让逻辑错误率变得更低。
这背后有一个重要思想:容错阈值。
可以简单理解为:
如果底层物理错误率低于某个门槛
纠错就有机会越纠越可靠
如果错误率高于门槛
纠错本身也会被错误淹没
这也是为什么量子硬件一直追求更高保真度。
不是为了参数好看。
而是为了让纠错真正开始发挥作用。
8.10 本章小结:量子计算难在把脆弱变可靠
本章从理想算法走到了真实机器。
我们看到,量子计算难,不只是因为数学难。
它还难在物理系统本身非常脆弱。
退相干会破坏相位关系。
噪声会让量子门偏离理想操作。
测量也可能带来错误。
经典纠错不能直接搬到量子世界。
因为未知量子态不能复制,测量会破坏叠加,错误也不只是简单的 0 和 1 翻转。
量子纠错的核心思路是:
不直接测数据
只测错误症状
把一个逻辑量子比特编码到多个物理量子比特里
不断发现并修正错误
表面码等纠错方案,试图把许多脆弱物理比特组织成更可靠的逻辑比特。
NISQ 设备则代表通向未来的一段中间阶段:
它们已经能展示量子效应,但还没有达到大规模容错计算的理想状态。
所以,真实量子计算机的核心任务可以概括成一句话:
把脆弱的量子物理,工程化成可靠的信息处理。
下一章,我们会继续沿着现实机器往下看:
一台完整的量子计算机到底由哪些部件组成?
它和传统计算机的输入、CPU、存储、输出有什么对应关系,又有什么根本不同?
第九章 未来量子计算机的系统架构
前面我们已经看过量子比特、量子门、量子算法,也看过噪声和纠错。
现在可以问一个更具体的问题:
一台完整的量子计算机,到底长什么样?
它会像今天的笔记本电脑吗?
会有键盘、屏幕、CPU、内存和硬盘吗?
它是不是只是在普通电脑里换上一颗“量子 CPU”?
答案是:不是。
量子计算机不是经典计算机的简单升级版。
它更像一个混合系统:
外层是经典计算机
中间是控制电子学
核心是量子处理器
旁边还有低温、真空、激光、微波、屏蔽等物理环境
它当然也有输入、处理、存储、输出和互连。
但每一部分的含义都变了。
传统计算机处理的是稳定的经典比特。
量子计算机处理的是脆弱的量子态。
传统计算机把数据读来读去,一般不会改变数据本身。
量子计算机一测量,量子态就会变成经典结果。
传统计算机的 CPU 自己按指令执行运算。
量子处理器更像一个被外部控制系统精密操控的物理实验装置。
本章就用“传统计算机的五大部件”做参照,看看量子计算机会怎样重构这些部件。
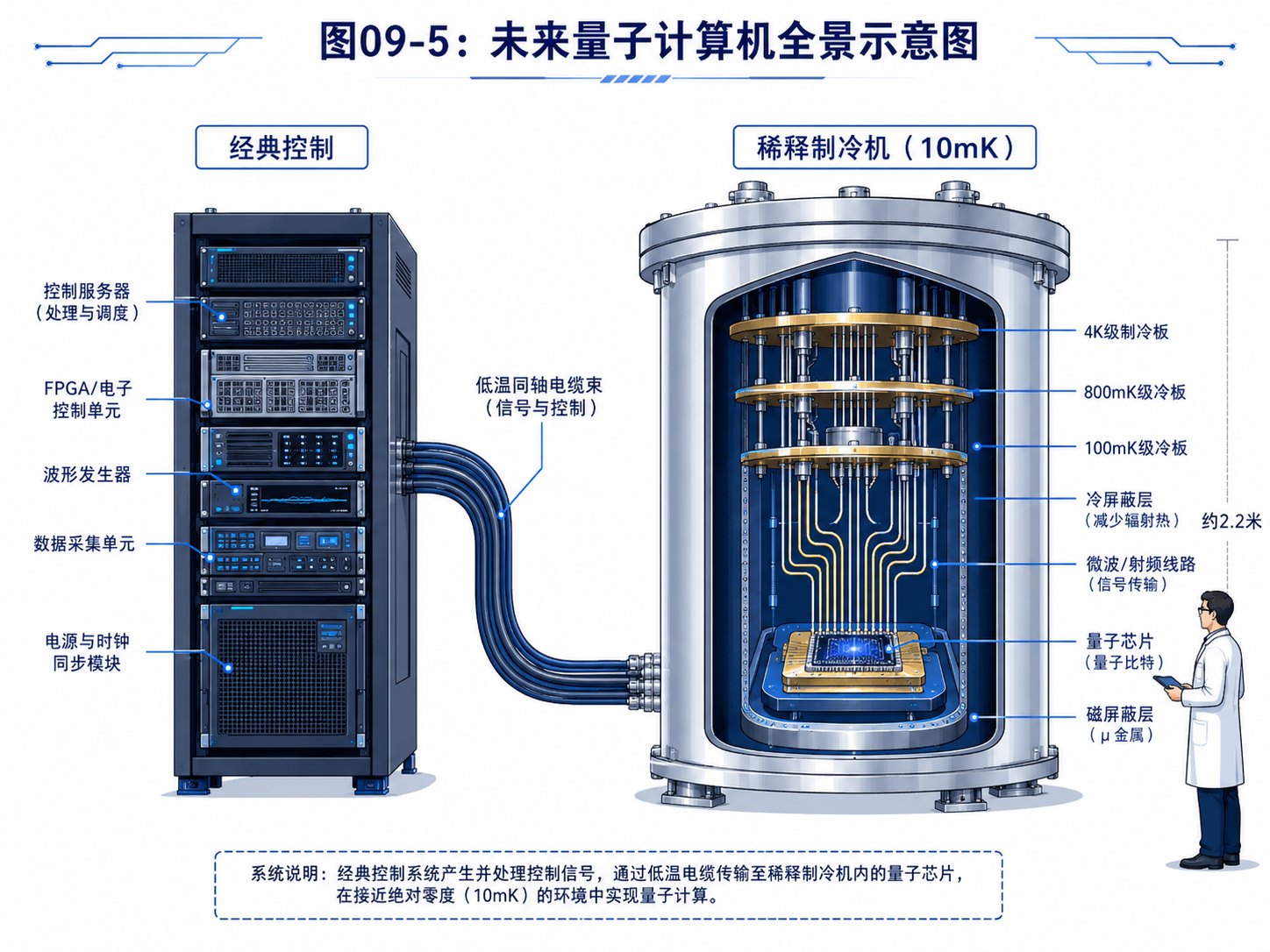
9.1 先看总图:经典外壳,量子核心
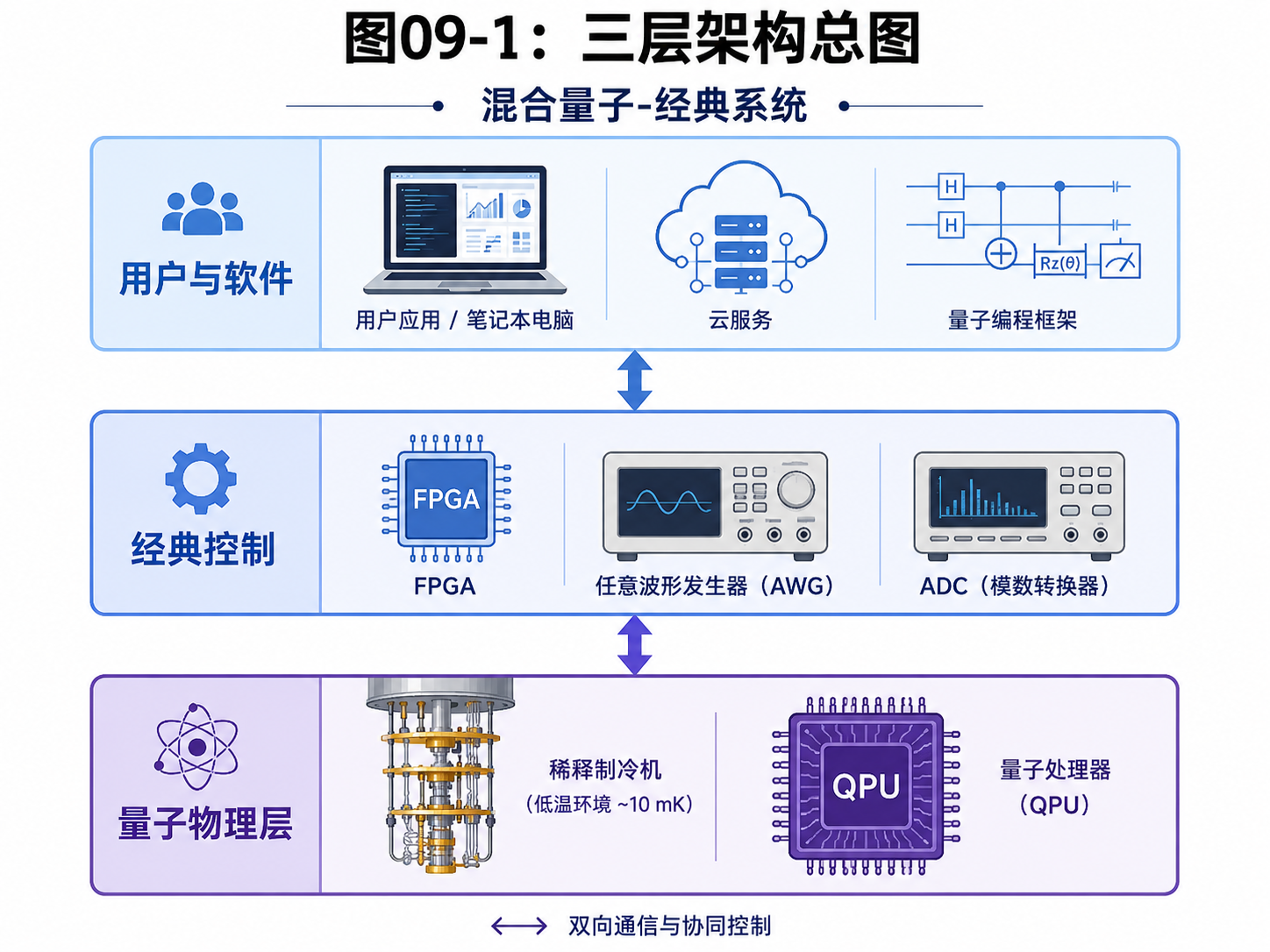
一台实用量子计算机不会只有量子部分。
它一定需要经典计算机。
原因很简单:
用户写程序是经典的
编译器运行在经典机器上
控制信号是经典电子信号
测量结果也是经典比特
纠错解码通常也要经典计算参与
量子处理器负责最特殊的那部分:
让量子比特保持叠加
执行量子门
产生干涉
最后被测量
可以先想象一台量子计算机分成三层。
第一层:用户和软件层。
用户写的是量子程序。
程序会被编译成量子线路,再继续拆成硬件能执行的控制操作。
第二层:经典控制层。
这一层负责发出脉冲、安排时序、收集测量结果、做纠错判断。
它可能包含普通服务器、FPGA、专用控制芯片和高速采集设备。
第三层:量子物理层。
这里才是真正的 QPU,也就是量子处理器。
量子比特可能是超导电路、离子、光子、半导体量子点,或者其他物理系统。
这三层之间不断交换信息。
经典软件给出任务
经典控制器发出操作
量子处理器发生演化
测量系统读出结果
经典计算机继续处理结果
所以,未来量子计算机不是一颗孤立芯片。
它是一套从软件到物理环境都紧密协作的系统。
9.2 输入:从读取数据到制备量子态
传统计算机的输入很直观。
你按键盘,移动鼠标,接入网线,读取文件。
这些输入最后都变成经典比特:
0 和 1
量子计算机的输入不只是把一个文件塞进机器。
更准确地说,它首先要做量子态制备。
也就是把量子比特准备到算法需要的初始状态。
最常见的起点是:
|0⟩
然后通过量子门,把它变成需要的叠加态或纠缠态。
这听起来简单,但物理上很难。
如果是超导路线,量子比特通常在极低温环境中工作。
外部经典电子设备要发出精确的微波脉冲,把超导电路调整到指定状态。
如果是离子阱路线,需要先用激光和电磁场把离子困住、冷却,再用激光脉冲操控它的内部能级。
如果是光量子路线,可能要先产生单光子,再用偏振片、波片、分束器等器件准备光子的状态。
不同路线的设备完全不同。
但它们在信息层面做的是同一件事:
把物理系统准备成算法要用的量子态
这就是量子计算机的“输入”。
它比经典输入更像实验准备。
准备得不准,后面的计算就会从一开始带着偏差。
9.3 运算核心:QPU 不是更快的 CPU
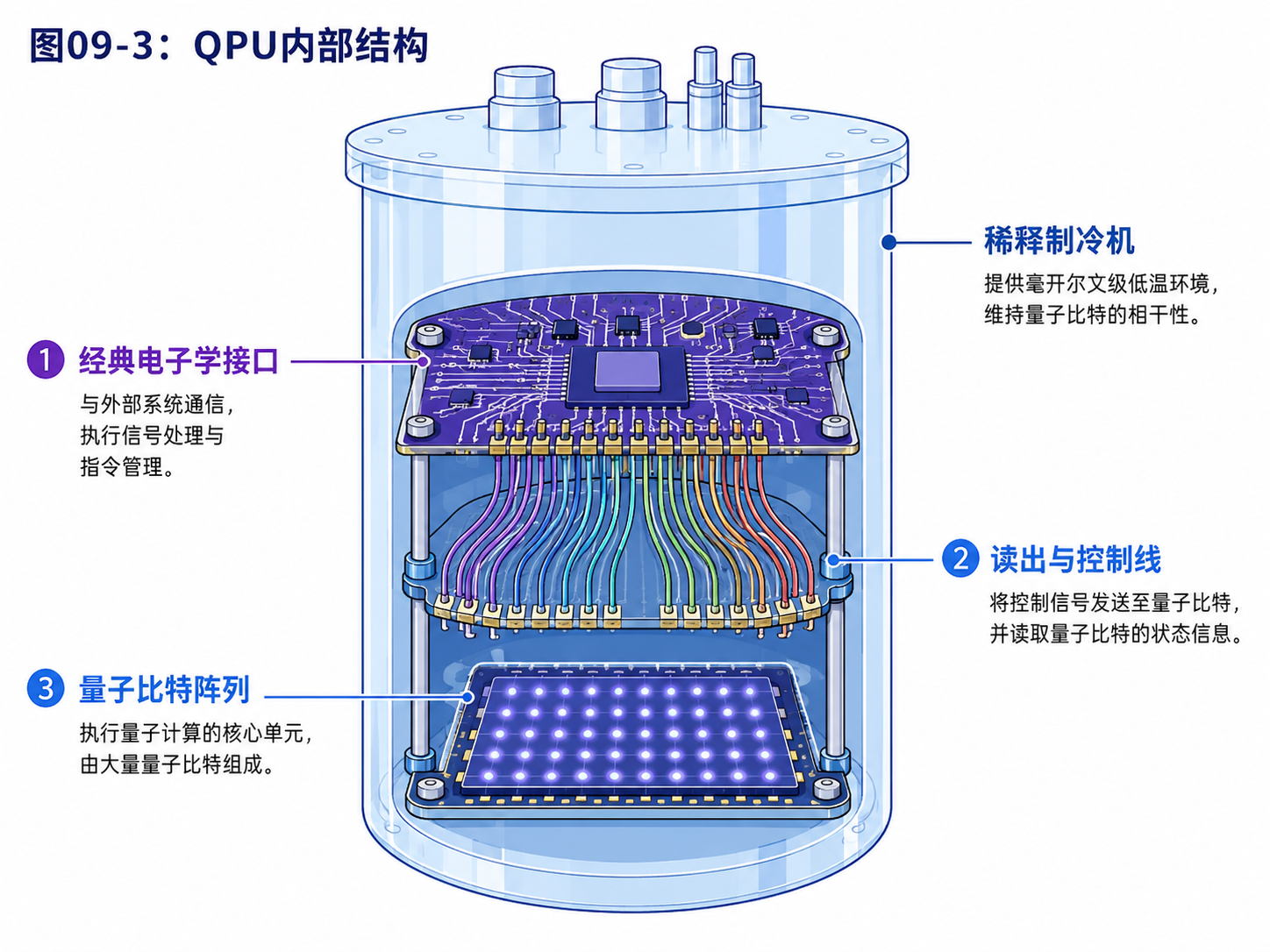
传统 CPU 的核心是逻辑门和寄存器。
它按时钟节拍执行指令。
指令告诉它做加法、比较、跳转、读写内存。
量子处理器常被叫作 QPU。
它不是普通 CPU 的加速版。
QPU 的任务是让量子态按量子门的规则演化。
比如:
Hadamard 门制造叠加
CNOT 门制造关联
相位门改变相位
测量把量子态变成经典结果
这些操作不是在芯片里查一张真值表。
它们是物理操控。
对超导量子比特来说,量子门可能由微波脉冲实现。
对离子阱来说,量子门可能由激光脉冲实现。
对光量子来说,量子门可能由波片、分束器、相移器和探测器组成。
所以 QPU 更像一个“可编程的量子实验平台”。
它的输入不是普通机器码,而是经过编译后的控制指令。
这些指令最后会变成具体的脉冲、相位、持续时间和测量安排。
这也解释了一个常见问题:
量子计算机会不会在量子芯片上运行操作系统?
通常不会。
操作系统、编译器、任务调度、用户接口,主要都在经典计算机上。
量子处理器只执行被安排好的量子操作。
它像一个非常特殊的协处理器。
经典计算机负责组织任务。
QPU 负责执行经典机器难以模拟的量子演化。
9.4 控制器:经典世界和量子世界之间的翻译官
量子处理器不能自己凭空运行。
它需要控制器。
控制器的任务是把经典程序翻译成物理动作。
一个量子程序可能写成:
对第 1 个量子比特做 H
对第 1、2 个量子比特做 CNOT
测量第 1 个量子比特
硬件不能直接理解这几句话。
控制器要把它们翻译成更底层的东西:
什么时候发脉冲
脉冲多强
持续多久
相位是多少
读出窗口开多长
测量结果如何反馈给后续步骤
这就是经典-量子混合控制。
它既要快,又要准。
快,是因为有些纠错和反馈必须在很短时间内完成。
如果反应太慢,量子态已经退相干了。
准,是因为脉冲参数稍微偏一点,量子门就会偏离理想操作。
所以控制器是量子计算机里非常关键的一层。
它不是附属品。
没有稳定控制,就没有稳定量子计算。
9.5 存储:量子寄存器不是量子硬盘
传统计算机有很多层存储:
寄存器
缓存
内存
硬盘
云存储
数据可以长期保存。
也可以复制、备份、传输。
量子信息就麻烦多了。
未知量子态不能随便复制。
量子态会退相干。
测量会破坏叠加。
所以,不要把量子寄存器想成“更高级的内存”。
量子寄存器更像计算过程中的临时工作区。
算法运行时,量子比特暂时保存量子态。
但它们不能像经典内存那样被随便读取。
也不能像硬盘文件那样长期稳定保存。
如果你想长期保存一个结果,通常要把它测量成经典比特,再存进传统存储设备。
比如:
量子计算产生测量结果
测量结果变成 0/1 字符串
经典计算机把字符串存入内存或硬盘
这也说明量子计算机不会完全取代经典计算机。
经典存储仍然非常重要。
量子部分负责处理特殊的量子态。
经典部分负责保存程序、参数、测量结果和用户数据。
未来如果有更成熟的量子存储,也会受到非常严格的物理限制。
它不太可能像普通硬盘那样随便复制未知量子态。
9.6 输出:测量不是普通读取
传统计算机的输出也很直观。
显示器显示画面。
网卡发送数据。
打印机打印文件。
这些输出通常不会改变原始数据。
你可以把一个文件打开很多次。
每次看到的内容都一样。
量子计算机的输出是测量。
测量会把量子态变成经典结果。
比如一个量子比特处在:
α|0⟩ + β|1⟩
测量后,你只会得到:
0
或者:
1
得到哪个,取决于概率。
测量之后,原来的叠加态通常就不再保留。
这和普通读取完全不同。
更重要的是,n 个量子比特虽然需要 2ⁿ 个振幅描述,但一次测量只得到 n 个经典比特。
这再次提醒我们:
量子计算不是把所有振幅打印出来
量子算法必须在测量前就把有用信息推到容易出现的结果上。
输出阶段只是最后一步。
它不是魔法读心术。
在不同硬件路线里,测量方式也不同。
超导路线可能通过读出共振腔的响应来判断量子比特状态。
离子阱路线可能通过离子发不发光来判断状态。
光量子路线可能用探测器记录光子走到哪一路。
物理方式不同。
信息结果相同:
量子态 -> 经典比特
9.7 互连:量子数据不能像普通数据那样搬运
传统计算机里,总线负责搬运数据。
CPU、内存、硬盘、网卡之间,可以通过电信号或光信号传输经典比特。
经典比特可以复制。
也可以放大。
如果信号弱了,可以中继、重发、纠错。
量子互连难得多。
因为未知量子态不能复制。
传输过程中还要保持相干性。
一旦环境获得了太多信息,量子态就会被破坏。
所以,量子互连要解决的问题不是简单“带宽够不够”。
而是:
量子态能不能被可靠传送?
纠缠能不能在远处建立?
传输损耗能不能被控制?
错误能不能被纠正?
在一台量子计算机内部,互连可能是芯片上的耦合器、谐振腔、光波导、离子运动模式等。
在更大的系统里,互连可能变成量子网络。
多个 QPU 之间通过光子或其他媒介建立纠缠,协同完成更大规模的任务。
这仍然是非常困难的方向。
但它很重要。
如果未来要建造大型量子计算机,很可能不能只靠一个无限扩大的芯片。
更现实的路线,是把多个模块连接起来。
模块之间怎样传量子信息,怎样保持纠缠,怎样做分布式纠错,都会成为系统架构的核心问题。
9.8 一台未来机器可能怎样工作
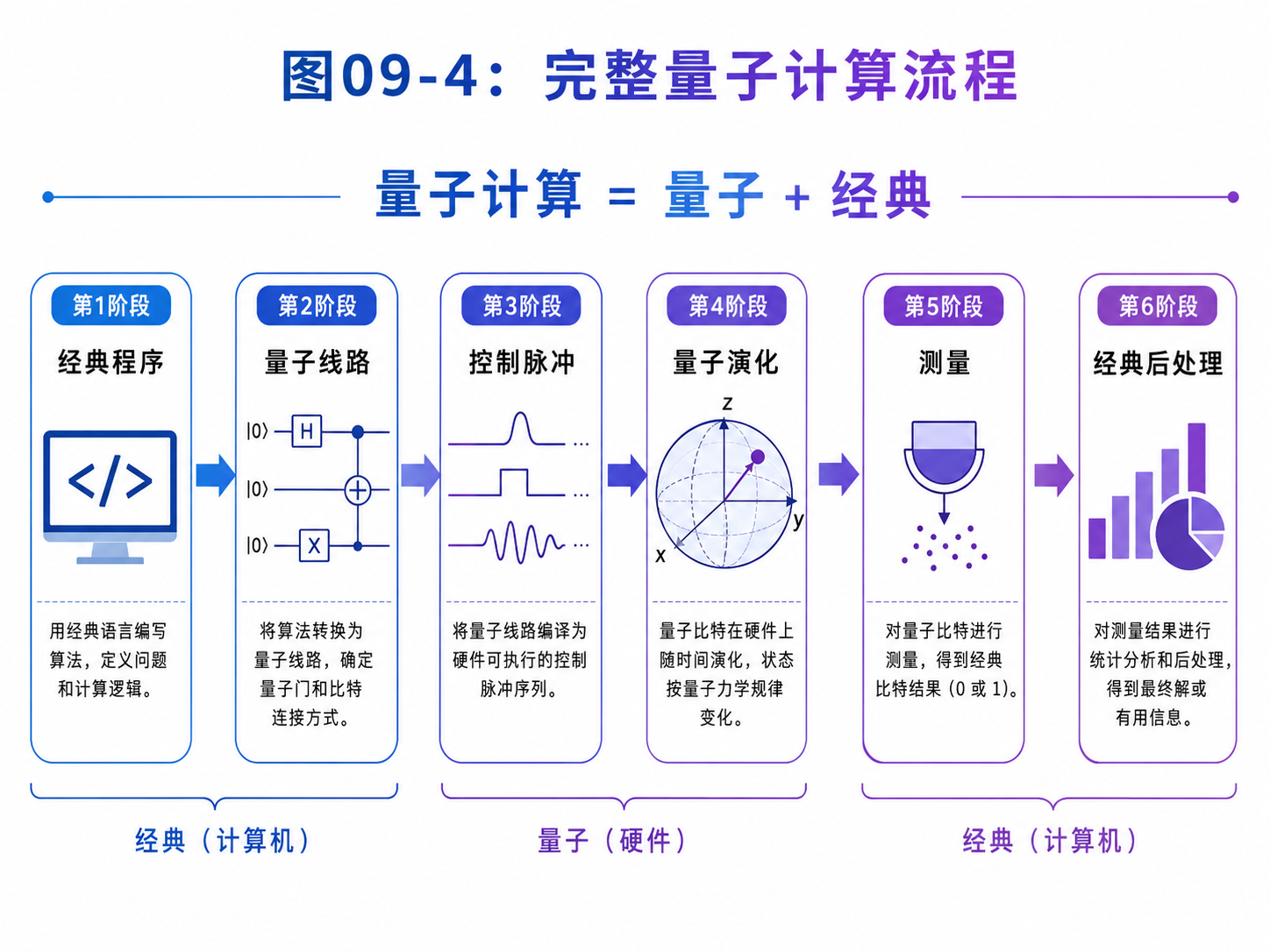
现在把这些部件串起来,看一次完整流程。
假设用户想运行一个量子算法。
第一步,用户在经典电脑上写程序。
程序可能使用某种量子编程框架。
用户写的是量子线路或更高层的算法描述。
第二步,编译器把程序变成硬件能执行的门序列。
它会考虑硬件支持哪些门,哪些量子比特能互相作用,线路能否简化,错误率如何。
第三步,控制系统把门序列变成脉冲和测量安排。
这一步非常接近硬件。
同一个逻辑门,在不同平台上可能对应完全不同的物理操作。
第四步,量子处理器执行操作。
量子比特被制备、演化、纠缠、干涉。
如果机器有纠错系统,还会不断进行错误症状测量和纠正。
第五步,测量系统读出经典结果。
量子态被测量成 0/1 字符串。
结果送回经典计算机。
第六步,经典计算机做后处理。
有些算法需要把测量结果统计很多次。
有些算法需要根据结果调整下一轮参数。
有些算法需要用经典数学步骤恢复最终答案。
所以一台量子计算机的运行流程可以概括成:
经典程序
-> 量子线路
-> 控制脉冲
-> 量子演化
-> 测量结果
-> 经典后处理
这条流程说明:
量子计算不是抛弃经典计算,而是和经典计算深度合作。
9.9 和传统计算机的一张对照表
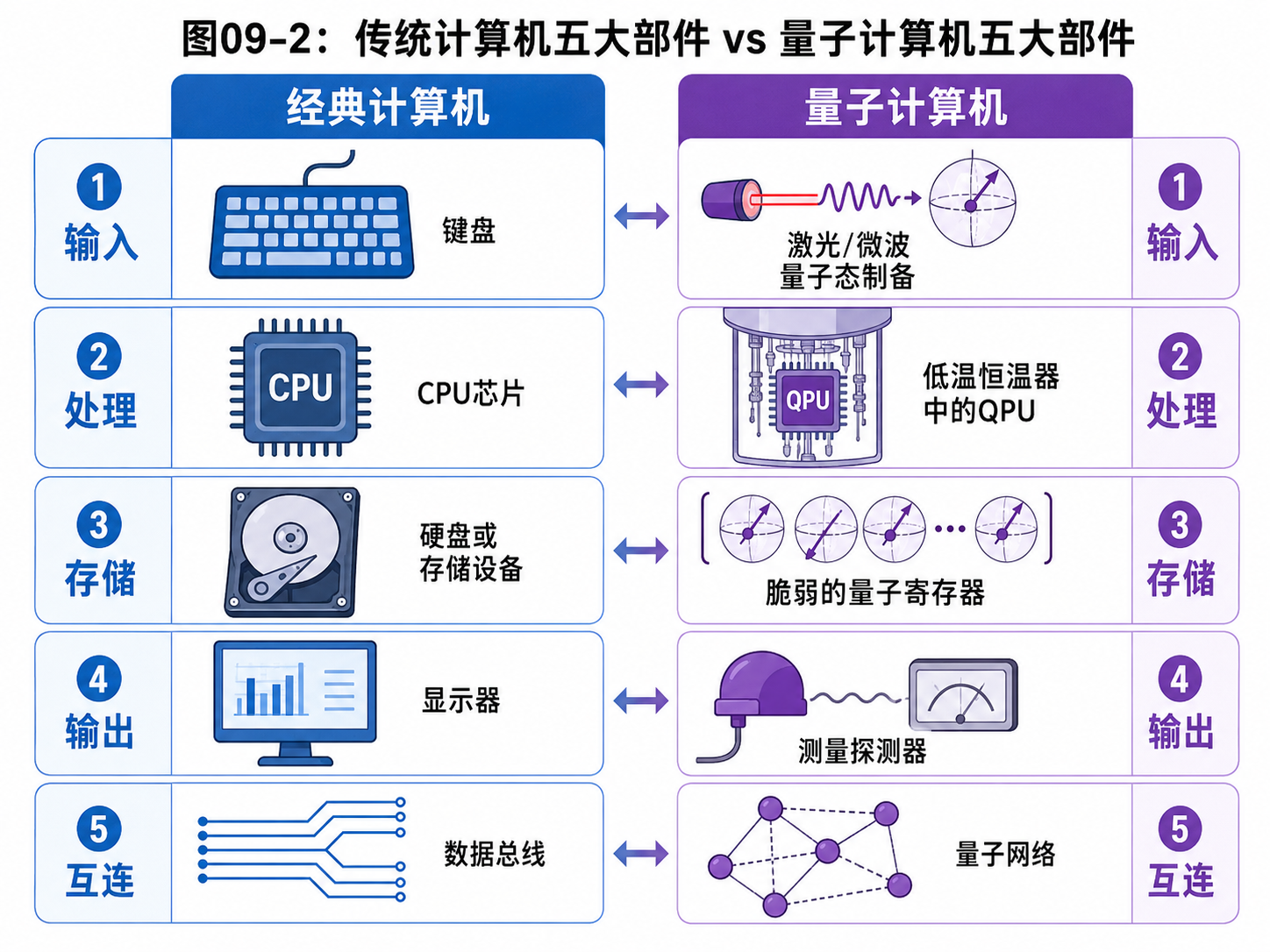
为了把这章收束一下,我们做一张对照。
传统输入:
读取键盘、文件、网络数据
量子输入:
制备量子态
传统 CPU:
按指令执行逻辑运算
量子 QPU:
在经典控制下执行量子门,让量子态演化
传统控制:
CPU 内部控制器调度指令
量子控制:
经典电子学生成脉冲、安排时序、处理反馈
传统存储:
数据可以长期保存、复制、读取
量子存储:
量子态脆弱,计算中临时保存,长期保存需要纠错或转成经典结果
传统输出:
读取数据并显示或传输
量子输出:
测量量子态,得到经典比特
传统总线:
搬运可复制的经典比特
量子互连:
尽量可靠地传递量子态或建立纠缠
这张对照表的重点不是说二者完全对应。
恰恰相反。
它是为了说明:
名字可以相似
工作方式已经变了
9.10 本章小结:量子计算机是一套混合系统
本章讨论了一台未来量子计算机的系统架构。
我们看到,它不会只是普通电脑里插了一块“量子 CPU”。
它更像一套混合系统:
经典软件负责表达任务
经典编译器负责生成线路
经典控制器负责发出精密操作
QPU 负责量子演化
测量系统把量子结果变成经典比特
经典计算机继续做后处理
传统计算机的输入、处理、存储、输出和互连,在量子世界里都有对应角色。
但每个角色都发生了根本变化。
输入变成量子态制备。
处理变成量子态演化。
存储变成脆弱的量子寄存器和纠错编码。
输出变成测量。
互连变成量子态传输和纠缠建立。
最重要的结论是:
量子计算机不是更快的经典计算机,而是经典控制系统和量子物理系统共同组成的新机器。
到这里,本书的主线也走完了。
我们从一点线性代数出发,经过量子力学的基本规则、经典门、量子门、叠加、干涉、算法、噪声和纠错,最后来到一台未来量子计算机的系统形态。
如果只记住一句话,可以记住这一句:
量子计算的核心,不是“同时拿到所有答案”,而是用量子态的振幅和干涉,把问题里的结构变成更容易被测到的结果。
理解了这一点,再看量子计算新闻、算法介绍或硬件进展,就不容易被“神奇”和“万能”这两个词带跑。
它既不是魔法,也不是泡沫。
它是一条很难、很慢、但非常深刻的计算道路。